バイナリファイル
バイナリファイルの中身を見る
16進ダンプ
add5.cやadd5.sはテキストファイルですが,
2節のアセンブリ言語で作成した
add5.oはバイナリファイルです.
バイナリファイルなので,lessコマンドでは中身を読めません.
$ less add5.o
^?❶ELF^B^A^A^@^@^@^@^@^@^@^@^@^A^@>^@^A^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@X^B
^@^@^@^@^@^@^@^@^@^@@^@^@^@^@^@@^@^L^@^K^@<F3>^O^^<FA>UH<89><E5><89>}<FC><8B>E
(長いので省略)
❶ELFとは
上のlessコマンドの結果にELFという文字が見える理由を説明します.
ELFはLinuxが採用しているバイナリ形式(binary format)です.
このELFのバイナリファイルの先頭4バイトにはマジックナンバーという
バイナリファイルを識別する特別な数値が入っています.
ELFバイナリのマジックナンバーは 7F 45 4C 46です.
45 4C 46はASCII文字で E L F なので,lessコマンドがELFと表示したわけです.
バイナリファイルの中身を読むには例えばodコマンドを使います.
$ od -t x1 add5.o
0000000 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
0000020 01 00 3e 00 01 00 00 00 00 00 00 00 00 00 00 00
(長いので省略)
一番左の数字が「先頭からのバイト数(16進表記)」,
その右側に並んでいるのが「1バイトごとに16進表記したファイルの中身」です.
(1バイトのデータは2桁の16進数で表せることを思い出しましょう.
例えば,add5.oの中身の先頭4バイトの値は7F 45 4C 46です).
-t x1というオプションは「1バイトごとに16進数で表示せよ」という意味です.
このような出力を16進ダンプ(hex dump)と言います.
他に16進ダンプするコマンドとして,xxdやhexdumpなどがあります.
ちなみに,add5.cはテキストファイルですが,内容は2進数で保存されて
いますので,odコマンドで中身を表示できます.
$ od -t x1 add5.c
0000000 69 6e 74 20 61 64 64 35 20 28 69 6e 74 20 6e 29
0000020 0a 7b 0a 20 20 20 20 72 65 74 75 72 6e 20 6e 20
0000040 2b 20 35 3b 0a 7d 0a
0000047
先頭の69はASCII文字iの文字コード,
同様に,次の6eは文字n,その次の74は文字tなので,
add5.cの先頭3文字がintであることを確認できます.
ASCIIコード表はman asciiコマンドで閲覧できます.
(例えば,16進数の0x69は10進数の105です.
ASCIIコード表の105番目の文字はiです.)
manコマンドとは
manコマンドはLinux上でマニュアルを表示するコマンドです.
例えばman asciiを実行すると以下のように表示されます.
$ man ascii
ASCII(7) Linux Programmer's Manual ASCII(7)
NAME
ascii - ASCII character set encoded in octal, decimal, and hexadecimal
DESCRIPTION
ASCII is the American Standard Code for Information Interchange. It is
a 7-bit code. Many 8-bit codes (e.g., ISO 8859-1) contain ASCII as
their lower half. The international counterpart of ASCII is known as
ISO 646-IRV.
The following table contains the 128 ASCII characters.
C program '\X' escapes are noted.
Oct Dec Hex Char Oct Dec Hex Char
────────────────────────────────────────────────────────────────────────
000 0 00 NUL '\0' (null character) 100 64 40 @
001 1 01 SOH (start of heading) 101 65 41 A
002 2 02 STX (start of text) 102 66 42 B
(以下略)
デフォルトではlessコマンドで1ページずつ表示されるので,
スペースキーで次のページが,bを押せば前のページが表示されます.
終了するにはqを押します.hを押せばヘルプを表示し,/で検索もできます.
例えば,/backspaceと入力してリターンを押すと,backspaceを検索してくれます.
manコマンドは章ごとに分かれています.例えば
- 1章はコマンド (例:
ls) - 2章はシステムコール (例:
open) - 3章はライブラリ関数 (例:
printf)
となっています.
printfというコマンドがあるので,
man printfとすると(ライブラリ関数ではなく)コマンドのprintfの
マニュアルが表示されてしまいます.
ライブラリ関数のprintfを見たい場合は
man 3 printfと章番号も指定します.
なお,odコマンドに-cオプションをつけると,
(文字として表示可能なバイトは)文字が表示されます.
$ od -t x1 -c add5.c
0000000 69 6e 74 20 61 64 64 35 20 28 69 6e 74 20 6e 29
i n t a d d 5 ( i n t n )
0000020 0a 7b 0a 20 20 20 20 72 65 74 75 72 6e 20 6e 20
\n { \n r e t u r n n
0000040 2b 20 35 3b 0a 7d 0a
+ 5 ; \n } \n
0000047
コンピュータの中のデータはすべて0と1から成る
ここで大事なことを復習しましょう.
それは
「コンピュータの中のデータは,どんな種類のデータであっても,
機械語命令であっても,すべて0と1だけで表現されている」
ということです.
ですので,テキストはバイナリでもあるのです.
- テキスト=文字として表示可能な2進数だけを含むデータ
- バイナリ=文字以外の2進数も含んだデータ

注意: 本書で,テキスト(text)という言葉には2種類の意味があることに注意して下さい.
- 1つは「文字」を意味します.例:「テキストファイル」(文字が入ったファイル)
- もう1つは「機械語命令列」を意味します.例:「テキストセクション」(機械語命令列が格納されるセクション)
2進数と符号化
前節で説明した通り, コンピュータ中では全てのものを0と1の2進数で表現する必要があります. そのため,データの種類ごとに2進数での表現方法,つまり符号化 (encoding)の方法が定められています. 例えば,
- 文字
UをASCII文字として符号化すると,01010101になります. pushq %rbpをx86-64の機械語命令として符号化すると,01010101になります.
おや,どちらも同じ01010101になってしまいました.
この2進数がUなのかpushq %rbpなのか,どうやって区別すればいいでしょう?
答えは「これだけでは区別できません」です.

別の手段(情報)を使って,いま自分が注目しているデータが,
文字なのか機械語命令なのかを知る必要があります.
例えば,この後で説明する.textセクションにある
2進数のデータ列は「.textセクションに存在するから」という理由で
機械語命令として解釈されます.
fileコマンド
16進ダンプ以外の方法で,add5.oの中身を見てみます.
まずはfileコマンドです.
fileコマンドはファイルの種類の情報を教えてくれます.
$ file add5.o
add5.o: ❶ELF 64-bit ❷LSB ❸relocatable, x86-64, ❹version 1 (SYSV), ❺not stripped
これで,add5.oが64ビットの❶ELFバイナリであることが分かりました.
ELFはバイナリ形式(バイナリを格納するためのファイルフォーマット)の1つです.
Linuxを含めて多くのOSがELFをバイナリ形式として使っています.
❷LSBとは
多バイト長のデータをバイト単位で格納する順序をバイトオーダ(byte order)といいます. LSBは最下位バイトから順に格納するバイトオーダ (Least Significant Byte first), つまりリトルエンディアン を意味しています.
x86-64のバイトオーダがリトルエンディアンのため,
このELFバイナリもリトルエンディアンになっています.
ELFバイナリがビッグエンディアンかリトルエンディアンかどうかを示すデータが,
ELFバイナリのヘッダに格納されています.
これはreadelf -hコマンドで調べられます❶.
$ readelf -h a.out
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, ❶little endian
Version: 1 (current)
OS/ABI: UNIX - System V
(以下略)
リトルエンディアンでの注意は16進ダンプする時に,多バイト長データが逆順に表示されることです.
以下で多バイト長データ❶0x11223344を.textセクションに配置してアセンブルした
little.oを逆アセンブルすると,❸44 33 22 11と逆順に表示されています.
(objdump -hの出力から,.textセクションのオフセット(ファイルの先頭からのバイト数)が❷0x40バイトであることを使って,odコマンドに-j0x40オプションを使い,.textセクションの先頭付近の情報を表示しています)
$ cat little.s
.text
❶.long 0x11223344
$ gcc -c little.s
$ objdump -h little.o
foo.o: file format elf64-x86-64
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000004 0000000000000000 0000000000000000 ❷00000040 2**0
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .data 00000000 0000000000000000 0000000000000000 00000044 2**0
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000000 0000000000000000 0000000000000000 00000044 2**0
ALLOC
$ od -t x1 -j0x40 little.o | head -n1
0000100 ❸44 33 22 11 00 00 00 00 00 00 00 00 00 00 00 00
❸relocatableとは
バイナリ中のアドレスを再配置 (relocate)できるバイナリのことを 再配置可能 (relocatable)であるといいます.オブジェクトファイルはリンク時や実行時にアドレスを変更できるよう, relocatableであることが多いです.
❹version 1 (SYSV)とは
LinuxのABI(バイナリ互換規約)であるSystem V ABI に準拠していることを表しています.
❺not strippedとは
バイナリには実行に直接関係ない記号表やデバッグ情報などが
含まれていることがよくあります.
この「実行に直接関係ない情報」が削除されたバイナリのことを
stripped binaryと呼びます.
stripコマンドで「実行に直接関係ない情報」を削除できます.
削除された分,サイズが少し減っています.
$ ls -l add5.o
-rw-rw-r-- 1 gondow gondow 1368 Jul 19 10:09 add5.o
$ strip add5.o
$ ls -l add5.o
-rw-rw-r-- 1 gondow gondow 880 Jul 19 14:58 add5.o
.textセクションだけ抜き出す
GNU binutilsのobjcopyコマンドを使うと,特定のセクションだけ抜き出せます.
以下ではlittle.oから.textセクションを抜き出して,ファイルfooに書き込んでいます.
$ objcopy --dump-section .text=foo little.o
$ od -t x1 foo
0000000 44 33 22 11
0000004
objcopyはセクションの注入も可能です.
以下ではファイルfooの内容をlittle.oの新しいセクション.text2として注入しています.
新しいセクション❶.text2が出来ていることが分かります.
$ objcopy --add-section .text2=foo --set-section-flags .hoge=noload,readonly little.o
$ objdump -h little.o
little.o: file format elf64-x86-64
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000004 0000000000000000 0000000000000000 00000040 2**0
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .data 00000000 0000000000000000 0000000000000000 00000044 2**0
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000000 0000000000000000 0000000000000000 00000044 2**0
ALLOC
3 ❶.text2 00000004 0000000000000000 0000000000000000 00000044 2**0
CONTENTS, READONLY
なお,fileコマンドはバイナリ以外のファイルにも使えます.
$ file add5.c
add5.c: ASCII text
$ file add5.s
add5.s: assembler source, ASCII text
$ file .
.: directory
$ file /dev/null
/dev/null: character special (1/3)
セクションとobjdump -hコマンド
バイナリファイルの構造はざっくり以下の図のようになっています.

- 最初のヘッダ以外の四角をセクション(section)と呼びます.
- バイナリはセクションという単位で区切られていて,それぞれ別の目的でデータが格納されます.
- ヘッダは目次の役割で「どこにどんなセクションがあるか」という情報を保持しています.
ヘッダの情報はobjdump -hで表示できます.
$ objdump -h add5.o
add5.o: file format elf64-x86-64
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000013 0000000000000000 0000000000000000 00000040 2**0
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .data 00000000 0000000000000000 0000000000000000 00000053 2**0
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000000 0000000000000000 0000000000000000 00000053 2**0
ALLOC
(以下略)
ここでは「.text,.data,.bssという3つのセクションがある」ことを
見ればOKです.
VMAとLMAとは
VMAはvirtual memory addressの略で「メモリ上で実行される時の
このセクションのメモリアドレス」です.
一方,LMAはload memory addressの略で「メモリ上にロード(コピー,配置)する時の
このセクションのメモリアドレス」です.
通常,セクションをメモリにロードした後で,移動せずにそのまま実行するため,VMAとLMAは同じアドレスになります.
add5.oではアドレスが決まってないので,VMAもLMAもゼロになっています.
File offとは
File offはファイルオフセットを表しています.このセクションがバイナリファイルの先頭から何バイト目から始まっているかを16進表記で表しています.
Algnとは
Algnはアラインメント(alignment)を表しています.
例えば「このセクションをメモリ上に配置する時,その先頭アドレスが8の倍数になるようにしてほしい」という状況の時,この部分が2**3となります(2の3乗=8).
CONTENTS, ALLOC, LOAD, READONLY, CODEとは
これらはセクションフラグと呼ばれるセクションの属性値です.
- CONTENTS このセクションには中身がある (例えば,
.bssはCONTENTSが無いので(ファイル中では)中身が空のセクションです) - ALLOC ロード時にこのセクションのためにメモリを割り当てる必要がある
- LOAD このセクションは実行するためにメモリ上にロードする必要がある
- READONLY メモリ上では「読み込みのみ許可(書き込み禁止)」と設定する必要がある
- CODE このセクションは実行可能な機械語命令を含んでいる
3つのセクション .text ,.data,.bss の役割は以下の通りです:
.textセクションは機械語命令を格納します.例えば,pushq %rbpを表す0x55は.textセクションに格納されます..dataセクションは初期化済みの静的変数の値を格納します.例えば,大域変数int x=999;があったとき,999の2進数表現が.dataセクションに格納されます..bssセクションは未初期化の静的変数の値を格納します.例えば,大域変数int y;があったとき,(概念的には)初期値0の2進数表現が.bssセクションに格納されます.
なぜ概念的
実はファイル中では.bssセクションにはサイズ情報などごくわずかの情報しか持っていません.実行時にメモリ上に.bssセクションを作る際に,実際に必要なメモリを確保して,そのメモリ領域をすべてゼロで初期化すれば十分だからです(ファイル中に大量のゼロの並びを保持する必要はありません).
// bss.c
int a [1024];
int main (void)
{
return a[0];
}
例えば,bss.cのint a[1024]; の変数aは未初期化なので,
変数aの実体は.bssセクションに置かれます.アセンブリコードを見てみると,
$ gcc -S bss.c
$ cat bss.s
(関係する箇所以外は削除)
❶ .bss # 以下を.bssセクションに出力
.align 32 # 次の出力アドレスを32の倍数にせよ
.type a, @object # ラベルaの型はオブジェクト(関数ではなくデータ)
.size a, 4096 # ラベルaのサイズは4096バイト
a: # ラベルaの定義
❷ .zero 4096 # 4096バイト分のゼロを出力せよ
❶.bssセクションに❷4096バイト分のゼロを出力するように見えますが,
ヘッダを見てみると,ファイル中の.bssセクションの中身は0バイトだと分かります.
$ gcc -g bss.c
$ objdump -h ./a.out
Sections:
Idx Name Size VMA LMA File off Algn
(中略)
23 ❸.bss ❹ 00001020 0000000000004020 0000000000004020 ❺ 00003010 2**5
❼ALLOC
24 .comment 0000002b 0000000000000000 0000000000000000 ❻ 00003010 2**0
CONTENTS, READONLY
❸.bssセクションのサイズは16進数で❹ 0x1020バイト(10進数では4128バイト)ですが,
ファイルオフセットを比較してみると,❺と❻が同じ値(000033010)なので,
ファイル中での.bssセクションのサイズは0バイトだと分かります.
また,セクション属性が❼ALLOCのみで,
CONTENTS(中身がある)が無いことからも0バイトと分かります.
さらに代表的なセクションである.rodataも説明します.
.rodataセクションは読み込みのみ(read-only)なデータの値を格納します.例えば,C言語の文字列定数"hello"は書き込み禁止なので,"hello"の2進数表現が.rodataセクションに格納されます.
バイナリファイルには上記以外のセクションも数多く使われますが,
まずはこの基本の4種類 (.text, .data, .bss, .rodata) を覚えましょう.
記号表の中身を表示させる(nmコマンド)
バイナリファイル中には記号表(symbol table)があることが多いです.
記号表とは「変数名や関数名がバイナリ中では何番地のアドレスになっているか」という情報です.
nmコマンドでバイナリファイル中の記号表を表示できます.
まず,以下のfoo.cを準備して下さい.
// foo.c
int g1 = 999;
int g2;
static int s1 = 888;
static int s2;
int main ()
{
static int s3 = 777;
static int s4;
int ❼i1 = 666;
int ❼i2;
}
そしてコンパイルして,nmコマンドで記号表の中身を表示させます.
$ gcc -c foo.c
$ nm foo.o
0000000000000000 ❶D g1
0000000000000000 ❸B g2
0000000000000000 ❺T main
0000000000000004 ❷d s1
0000000000000004 ❹b s2
0000000000000008 ❷d ❻s3.0
0000000000000008 ❹b ❻s4.1
この出力の読み方は以下の通りです.
- ❶
Dと❷dは.dataセクションのシンボル,❸Bと❹bは.bssセクションのシンボル,❺Tとtは.textセクションのシンボルであることを表す - 大文字はグローバル(ファイルをまたがって有効なシンボル),小文字はファイルローカルなシンボルであることを表す
static付きの局所変数を表すシンボルは 他の関数中の同名のシンボルと区別するために, ❻.0や.1などが付加されることがある.- 左側の
00,04,08がシンボルに対応するアドレスですが,再配置前(relocation前)なので仮のアドレス(各セクションの先頭からのオフセット) - (
staticのついてない)局所変数❼は記号表には含まれていない. 局所変数(自動変数)は実行時にスタック上に実体が確保されます.
ASLRとPIE(ちょっと脱線)
オブジェクトファイルのセクションごとの仮のアドレスは,
リンク後のa.outでは具体的なアドレスになります
$ gcc foo.c
$ nm ./a.out | egrep g1
0000000000004010 D g1
$ nm ./a.out | egrep main
U __libc_start_main@@GLIBC_2.34
0000000000001129 T main
U __libc_start_main@@GLIBC_2.34とは
バイナリ中で参照されているけど定義がないシンボルがあると,
nmコマンドはundefinedを意味するUを表示します.
実はa.outはmain関数を呼び出す前に__libc_start_mainという
GLIBC中の関数を(動的リンクした上で)呼び出します.
__libc_start_mainは
様々な初期化を行った後,(その名の通り)main関数を呼び出すのが主な役割です.
ちなみに__libc_start_mainは_startが呼び出します.
$ readelf -h ./a.out | egrep Entry
Entry point address: ❶ 0x1040
$ objdump -d ./a.out | egrep 1040
0000000000001040 ❷ <_start>:
1040: f3 0f 1e fa endbr64
a.outのエントリポイント(最初に実行するアドレス)は
❶ 0x1040番地です.この番地には❷_startがあるので,
a.outを実行すると最初に実行される関数は_startと分かります.
出力が長くなるので,g1とmainのアドレスだけ載せています.
g1のアドレスは0x4010番地,mainのアドレスは0x1129番地となりました.
ただし,このまま実行すると,g1やmainのアドレスはこれらのアドレスにはならず,
実行するたびに変わります.
これはASLRやPIEというセキュリティ対策機能のためです.
確かめてみましょう.
以下のfoo2.cを普通にコンパイルして実行してみます.
// foo2.c
#include <stdio.h>
int g1 = 999;
int main ()
{
printf ("%p, %p\n", &g1, main);
}
以下の通り,g1やmainのアドレスは実行するたびに変わりますし,
nmが出力したアドレスとも異なります.
$ gcc foo2.c
$ ./a.out
0x557f2361e010, 0x557f2361b149
$ ./a.out
0x55a40e6f5010, 0x55a40e6f2149
$ ./a.out
0x562750663010, 0x562750660149
$
ここではASLRとPIEの機能を無効にして,アドレスが変わらなくなることを確認します.
$ sudo sysctl -w kernel.randomize_va_space=0 # ASLRをオフ
$ gcc -no-pie foo2.c # PIEをオフ
$ nm ./a.out | egrep main
U __libc_start_main@@GLIBC_2.34
0000000000401136 T main
$ nm ./a.out | egrep g1
0000000000404030 D g1
$ ./a.out
&g1=0x404030, main=0x401136
$ ./a.out
&g1=0x404030, main=0x401136
$ ./a.out
&g1=0x404030, main=0x401136
ASLRとPIEの機能をオフにすることで,アドレスが変わらなくなり,
かつnmが出力するアドレスと同じになることが確認できました.
注意: 不用意なASLRとPIEの無効化はセキュリティ機能を下げるので避けるべきです. しかしデバッグ作業ではアドレスが変わらなくなるので ASLRとPIEの無効化が有用な場合もあります. なお,デバッガ中ではASLRは無効化されていることが多いです.
ASLRとは
ASLR (address space layout randomizationの略)は, アドレス空間の配置をランダム化する機能です. テキスト(実行コード),ライブラリ,スタック,ヒープなどをメモリ上に 配置するアドレスを実行するたびにランダムに変化させます. 以下を実行するとASLRは無効化され,
$ sudo sysctl -w kernel.randomize_va_space=0
以下を実行するとASLRは有効化されます.
$ sudo sysctl -w kernel.randomize_va_space=1
PIEとは
PIE (position independent executableの略)は位置独立実行可能ファイルを意味します.
通常,動的ライブラリは位置独立コードPIC (position independent code)としてコンパイルされます.
動的ライブラリはメモリ上で共有されるため,どのアドレスに配置してもそのまま再配置せずに,実行したいからです.
PIEは動的ライブラリだけでなく,a.outも位置独立にした実行可能ファイルを指します.
-no-pieオプションでコンパイルすると,PIEを無効化できます.
$ gcc -no-pie foo2.c
逆アセンブル再び
逆アセンブルで説明した通り,
objdump -d ./a.outで逆アセンブル結果が表示されます(再掲).
$ objdump -d add5.o
add5.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <add5>:
0: f3 0f 1e fa endbr64
4: 55 push %rbp
5: 48 89 e5 mov %rsp,%rbp
8: 89 7d fc mov %edi,-0x4(%rbp)
b: 8b 45 fc mov -0x4(%rbp),%eax
e: 83 c0 05 add $0x5,%eax
11: 5d pop %rbp
12: c3 retq
objdumpコマンドはadd5.oの.textセクションを抽出し,
そのデータを機械語命令として解釈して,対応するニモニックを出力しています.
この出力によれば,.textセクションの先頭4バイトはF3 0F 1E FAで,
この4バイトがendbr64命令になります
(x86-64の命令長は可変長で,1バイト〜15バイトです).
以下では.textセクションの先頭4バイトがF3 0F 1E FAであることを確認します.
セクションのヘッダを出力するコマンドobjdump -hの出力を再掲します.
$ objdump -h add5.o
add5.o: file format elf64-x86-64
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000013 0000000000000000 0000000000000000 ❶00000040 2**0
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .data 00000000 0000000000000000 0000000000000000 00000053 2**0
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000000 0000000000000000 0000000000000000 00000053 2**0
ALLOC
.textセクションのFile offの欄を見ると❶00000040とあります.
これは.textセクションがadd5.oの先頭から16進数で40バイト
目(以後,0x40と表記)にあることを意味しています.
odコマンドの-jオプションを使うと,指定したバイト数だけ,
先頭をスキップしてくれます.
この-jオプションを使って,0x40バイトスキップして,
.textセクションの最初だけを16進ダンプします
(head -n3は先頭の3行だけ表示します).
$ od -t x1 -j0x40 add5.o | head -n3
0000100 ❶f3 0f 1e fa 55 48 89 e5 89 7d fc 8b 45 fc 83 c0
0000120 05 5d c3 00 47 43 43 3a 20 28 55 62 75 6e 74 75
0000140 20 39 2e 34 2e 30 2d 31 75 62 75 6e 74 75 31 7e
この結果❶を見ると,.textセクションの最初の4バイトは
F3 0F 1E FAであることが分かります.
これは上の逆アセンブルの結果の先頭4バイトと一致しており,
endbr64命令が,add5.oの先頭から0x40バイト目に存在することが分かりました.
広義のコンパイルとリンク
ここでは広義のコンパイル,つまりCのプログラムfoo.cから
実行可能ファイルa.outを生成する処理の中身を見ていきます.
いちばん大事なのは最後のリンク(link)です.

- ❶ Cの前処理,すなわち
#includeや#defineなどの前処理命令の処理と,マクロ(例えば<stdio.h>が定義するNULLやEOF)の展開を行います.gcc -Eコマンドで実行できますが,内部的にはカッコ内のcppやcc1コマンドが実行されています(現在はcc1). - ❷ 狭義のコンパイル処理で,Cのプログラムをアセンブリコードに変換します.
- ❸ アセンブラ(
asコマンド)によるアセンブル処理で,オブジェクトファイルfoo.oを生成します.foo.o中にはバイナリの機械語命令が入っています. - ❹
foo.oだけでは実行可能ファイルは作れません.例えば,printfなどのライブラリ関数の実体は,libc.a(静的ライブラリ)やlibc.so(動的ライブラリ)の中にあるからです. また,main関数を呼び出すためのCスタートアップルーチン(多くの場合,crt*.oというファイル名)も必要です. また,分割コンパイルの機能を使った結果,foo.oは他のC言語のプログラムをアセンブルしたオブジェクトファイル*.oが必要なことがよくあります. 「このような他のバイナリとfoo.oを合体させてa.outを生成する処理」のことをリンク(link)と呼びます.
広義のコンパイルで具体的にどのような処理が行われてるのかを見るには,
-vをつけてgcc -vとコンパイルすれば表示されます.
(以下では表示を省略しています.全てを表示するにはボタンを押して下さい).
$ gcc -v main.c add5.s |& tee out
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/lib/gcc/x86_64-linux-gnu/11/lto-wrapper
OFFLOAD_TARGET_NAMES=nvptx-none:amdgcn-amdhsa
OFFLOAD_TARGET_DEFAULT=1
Target: x86_64-linux-gnu
Configured with: ../src/configure -v --with-pkgversion='Ubuntu 11.3.0-1ubuntu1~22.04.1' --with-bugurl=file:///usr/share/doc/gcc-11/README.Bugs --enable-languages=c,ada,c++,go,brig,d,fortran,objc,obj-c++,m2 --prefix=/usr --with-gcc-major-version-only --program-suffix=-11 --program-prefix=x86_64-linux-gnu- --enable-shared --enable-linker-build-id --libexecdir=/usr/lib --without-included-gettext --enable-threads=posix --libdir=/usr/lib --enable-nls --enable-bootstrap --enable-clocale=gnu --enable-libstdcxx-debug --enable-libstdcxx-time=yes --with-default-libstdcxx-abi=new --enable-gnu-unique-object --disable-vtable-verify --enable-plugin --enable-default-pie --with-system-zlib --enable-libphobos-checking=release --with-target-system-zlib=auto --enable-objc-gc=auto --enable-multiarch --disable-werror --enable-cet --with-arch-32=i686 --with-abi=m64 --with-multilib-list=m32,m64,mx32 --enable-multilib --with-tune=generic --enable-offload-targets=nvptx-none=/build/gcc-11-aYxV0E/gcc-11-11.3.0/debian/tmp-nvptx/usr,amdgcn-amdhsa=/build/gcc-11-aYxV0E/gcc-11-11.3.0/debian/tmp-gcn/usr --without-cuda-driver --enable-checking=release --build=x86_64-linux-gnu --host=x86_64-linux-gnu --target=x86_64-linux-gnu --with-build-config=bootstrap-lto-lean --enable-link-serialization=2
Thread model: posix
Supported LTO compression algorithms: zlib zstd
gcc version 11.3.0 (Ubuntu 11.3.0-1ubuntu1~22.04.1)
COLLECT_GCC_OPTIONS='-v' '-mtune=generic' '-march=x86-64' '-dumpdir' 'a-'
/usr/lib/gcc/x86_64-linux-gnu/11/cc1 -quiet -v -imultiarch x86_64-linux-gnu main.c -quiet -dumpdir a- -dumpbase main.c -dumpbase-ext .c -mtune=generic -march=x86-64 -version -fasynchronous-unwind-tables -fstack-protector-strong -Wformat -Wformat-security -fstack-clash-protection -fcf-protection -o /tmp/ccTw9Mym.s
GNU C17 (Ubuntu 11.3.0-1ubuntu1~22.04.1) version 11.3.0 (x86_64-linux-gnu)
compiled by GNU C version 11.3.0, GMP version 6.2.1, MPFR version 4.1.0, MPC version 1.2.1, isl version isl-0.24-GMP
GGC heuristics: --param ggc-min-expand=100 --param ggc-min-heapsize=131072
ignoring nonexistent directory "/usr/local/include/x86_64-linux-gnu"
ignoring nonexistent directory "/usr/lib/gcc/x86_64-linux-gnu/11/include-fixed"
ignoring nonexistent directory "/usr/lib/gcc/x86_64-linux-gnu/11/../../../../x86_64-linux-gnu/include"
#include "..." search starts here:
#include <...> search starts here:
/usr/lib/gcc/x86_64-linux-gnu/11/include
/usr/local/include
/usr/include/x86_64-linux-gnu
/usr/include
End of search list.
GNU C17 (Ubuntu 11.3.0-1ubuntu1~22.04.1) version 11.3.0 (x86_64-linux-gnu)
compiled by GNU C version 11.3.0, GMP version 6.2.1, MPFR version 4.1.0, MPC version 1.2.1, isl version isl-0.24-GMP
GGC heuristics: --param ggc-min-expand=100 --param ggc-min-heapsize=131072
Compiler executable checksum: e13e2dc98bfa673227c4000e476a9388
COLLECT_GCC_OPTIONS='-v' '-mtune=generic' '-march=x86-64' '-dumpdir' 'a-'
as -v --64 -o /tmp/cc5o7Jgg.o /tmp/ccTw9Mym.s
GNU assembler version 2.38 (x86_64-linux-gnu) using BFD version (GNU Binutils for Ubuntu) 2.38
COLLECT_GCC_OPTIONS='-v' '-mtune=generic' '-march=x86-64' '-dumpdir' 'a-'
as -v --64 -o /tmp/ccUs2R16.o add5.s
GNU assembler version 2.38 (x86_64-linux-gnu) using BFD version (GNU Binutils for Ubuntu) 2.38
COMPILER_PATH=/usr/lib/gcc/x86_64-linux-gnu/11/:/usr/lib/gcc/x86_64-linux-gnu/11/:/usr/lib/gcc/x86_64-linux-gnu/:/usr/lib/gcc/x86_64-linux-gnu/11/:/usr/lib/gcc/x86_64-linux-gnu/
LIBRARY_PATH=/usr/lib/gcc/x86_64-linux-gnu/11/:/usr/lib/gcc/x86_64-linux-gnu/11/../../../x86_64-linux-gnu/:/usr/lib/gcc/x86_64-linux-gnu/11/../../../../lib/:/lib/x86_64-linux-gnu/:/lib/../lib/:/usr/lib/x86_64-linux-gnu/:/usr/lib/../lib/:/usr/lib/gcc/x86_64-linux-gnu/11/../../../:/lib/:/usr/lib/
COLLECT_GCC_OPTIONS='-v' '-mtune=generic' '-march=x86-64' '-dumpdir' 'a.'
/usr/lib/gcc/x86_64-linux-gnu/11/collect2 -plugin /usr/lib/gcc/x86_64-linux-gnu/11/liblto_plugin.so -plugin-opt=/usr/lib/gcc/x86_64-linux-gnu/11/lto-wrapper -plugin-opt=-fresolution=/tmp/ccgnuv0i.res -plugin-opt=-pass-through=-lgcc -plugin-opt=-pass-through=-lgcc_s -plugin-opt=-pass-through=-lc -plugin-opt=-pass-through=-lgcc -plugin-opt=-pass-through=-lgcc_s --build-id --eh-frame-hdr -m elf_x86_64 --hash-style=gnu --as-needed -dynamic-linker /lib64/ld-linux-x86-64.so.2 -pie -z now -z relro /usr/lib/gcc/x86_64-linux-gnu/11/../../../x86_64-linux-gnu/Scrt1.o /usr/lib/gcc/x86_64-linux-gnu/11/../../../x86_64-linux-gnu/crti.o /usr/lib/gcc/x86_64-linux-gnu/11/crtbeginS.o -L/usr/lib/gcc/x86_64-linux-gnu/11 -L/usr/lib/gcc/x86_64-linux-gnu/11/../../../x86_64-linux-gnu -L/usr/lib/gcc/x86_64-linux-gnu/11/../../../../lib -L/lib/x86_64-linux-gnu -L/lib/../lib -L/usr/lib/x86_64-linux-gnu -L/usr/lib/../lib -L/usr/lib/gcc/x86_64-linux-gnu/11/../../.. /tmp/cc5o7Jgg.o /tmp/ccUs2R16.o -lgcc --push-state --as-needed -lgcc_s --pop-state -lc -lgcc --push-state --as-needed -lgcc_s --pop-state /usr/lib/gcc/x86_64-linux-gnu/11/crtendS.o /usr/lib/gcc/x86_64-linux-gnu/11/../../../x86_64-linux-gnu/crtn.o
COLLECT_GCC_OPTIONS='-v' '-mtune=generic' '-march=x86-64' '-dumpdir' 'a.'
バイナリファイルの種類
実行可能ファイルa.outに関連するバイナリファイルには
以下の4種類があります:
- オブジェクトファイル(
*.o) - 実行可能ファイル(
a.out) - 静的ライブラリファイル(
lib*.a) - 動的ライブラリファイル(
lib*.so)
オブジェクトファイル(*.o)
オブジェクトファイルとはLinuxでファイル名の拡張子が.oなファイルです.
オブジェクトファイルは機械語命令を含んでいますが,
このオブジェクトファイル単体では実行することができません.
実行を可能にするにはリンク(link)処理を経て,
実行可能ファイル
を作成する必要があります.
オブジェクトファイルは再配置可能オブジェクトファイル (relocatable object file)と呼ばれることもあります. オブジェクトファイルはリンク時に再配置(アドレス調整)が可能だからです.
実行可能ファイル(a.out)
実行可能ファイル(executable file)はその名前の通り,OSに実行を依頼すればそのままで実行できるバイナリファイルのことです.
例えば,hello wordの実行可能ファイルa.outはシェル上で以下のように実行できます.
$ ./a.out
hello, world
シェルとは
シェル (shell)とは「ユーザが入力したコマンドを解釈実行するプログラム」です.
例えば,bash, zsh, csh, sh, ksh, tcshなどはすべてシェルです.
Linux上ではユーザが自由にどのシェルを使うかを選ぶことができます.
シェルという名前は(OSの実体をカーネル(核)と呼ぶのに対して)
シェルがユーザに最も近い位置,つまりコンピュータシステムの外殻にあることに
由来してます(シェルの英語の意味は貝殻の殻(から)です).
シェルは,ユーザが指定したa.outなどのプログラムの実行を,
システムコールexecve等を使ってOS(カーネル)に依頼します.
ちなみにターミナル (端末,terminal),あるいはターミナルエミュレータは, ユーザの入出力処理を行うプログラムであり,ターミナル上でシェルは動作しています.
lsなどのシェル上で実行可能なコマンドも実行可能ファイルです.
$ which ls
/usr/bin/ls
$ file /usr/bin/ls
/usr/bin/ls: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, ❶interpreter /lib64/ld-linux-x86-64.so.2, ❷BuildID[sha1]=2f15ad836be3339dec0e2e6a3c637e08e48aacbd, for GNU/Linux 3.2.0, stripped
$ ls
a.out add5.c add5.o add5.s
ELFバイナリの動的リンカのことを(なぜか)interpreterと呼びます.
プログラミング言語処理系のインタプリタとは何の関係もありません.
ELFバイナリでは動的リンカのフルパスを指定することができ,
そのフルパス名をバイナリに埋め込みます.
この場合は 逆アセンブルすると
❶interpreterとは
/lib64/ld-linux-x86-64.so.2 が埋め込まれています.
OSがa.outを実行する際に,
OSはまず動的リンカ(interpreter)をメモリにロードして,
ロードした動的リンカに制御を渡します.
動的リンカはa.out中の他の部分や,動的ライブラリをメモリにロードし,
動的リンクを行ってから,a.outのエントリポイント
(最初に実行を開始するアドレス)にジャンプします.
その後,いくつかの初期化を行ってから,main関数が呼び出されます.a.outのエントリポイントはreadelf -hコマンドで確認できます.
エントリポイントは0x401050番地でした❶.$ readelf -h ./a.out
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: EXEC (Executable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
❶Entry point address: 0x401050
Start of program headers: 64 (bytes into file)
Start of section headers: 16832 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 13
Size of section headers: 64 (bytes)
Number of section headers: 36
Section header string table index: 35
0x401050番地は_startという関数がありました❷.
a.outは_start関数から実行が始まることが分かりました.$ objdump -d ./a.out | egrep 401050 -A 5
0000000000401050 ❷ <_start>:
401050: f3 0f 1e fa endbr64
401054: 31 ed xor %ebp,%ebp
401056: 49 89 d1 mov %rdx,%r9
401059: 5e pop %rsi
40105a: 48 89 e2 mov %rsp,%rdx
40105d: 48 83 e4 f0 and $0xfffffffffffffff0,%rsp
❷BuildID[sha1]とは
BuildIDはバイナリファイルが同じかどうかを識別するユニークな番号(背番号)です.
ここでは2f15で始まる40桁の16進数が /usr/bin/lsのBuildIDです.
BuildIDはLinux ELF特有の機能です.
stripしてもBuildIDは変化しないので,strip前後のファイルが同じかの確認に使えます.
$ gcc hello.c
$ cp a.out a.out.stripped
$ strip a.out.stripped
$ file a.out a.out.stripped
a.out: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=308260da4f7fb6d4116c12670adf6e503637abba, for GNU/Linux 3.2.0, not stripped
a.out.stripped: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=308260da4f7fb6d4116c12670adf6e503637abba, for GNU/Linux 3.2.0, stripped
ここでは説明しませんがコアファイル (core file)にもBuildIDが入っており,
そのコアファイルを出力したa.outを探すことができます.
ちなみにsha1はSHA-1を意味しており,SHA-1は160ビットのハッシュを生成するハッシュ関数です.
gitのハッシュはSHA-1を使っています.
sha1sumコマンドでSHA-1のハッシュを計算できます.
$ sha1sum ./a.out
ff99525ad6a48d78d35d3108401af935a6ca9bbe ./a.out
この結果から分かる通り,BuildIDのハッシュは,単純にa.outから作ったハッシュ値ではありません.
ELFバイナリのヘッダとセクションの一部からハッシュを計算しているようですが,正確な情報は見つかりませんでした(どうやら未公開のようです).
実行可能なコマンドには実行可能ファイルではなく, スクリプトなことがあります.
$ which shasum
/usr/bin/shasum
$ file /usr/bin/shasum
/usr/bin/shasum: Perl script text executable
$ head -3 /usr/bin/shasum
#!/usr/bin/perl
eval 'exec /usr/bin/perl -S $0 ${1+"$@"}'
if 0; # ^ Run only under a shell
shasumコマンドは(実行可能ファイルではなく)Perlスクリプトでした.
静的ライブラリ(lib*.a)
静的ライブラリ(static library)は静的リンク するときに使われるライブラリです. ライブラリとは複数のオブジェクトファイルを1つのファイルにまとめたもの(アーカイブ)です.
LinuxなどのUNIX系のOSでは静的ライブラリのファイル拡張子は.aが多いです.
またWindowsでは.libです.
printfの実体が入っているC標準ライブラリの
静的ライブラリのファイル名はlibc.aです.
動的ライブラリ(lib*.so)
動的ライブラリ(dynamic library)は動的リンク するときに使われるライブラリです. 動的ライブラリは共有ライブラリ(shared library)とも呼ばれます. 動的ライブラリは複数のプロセスからメモリ上で共有されるからです.
Linuxでは動的ライブラリのファイル拡張子は.soです(shared objectの略).
処理系の都合でファイル拡張子に数字がつくことがあります(例:.so.6).
動的ライブラリのファイル拡張子はUnix系のOSでも様々です.
Windowsでは.dllです.
静的リンクと動的リンク
静的ライブラリは静的リンクに使われるライブラリで, 動的ライブラリは動的リンクに使われるライブラリです.
静的リンク
静的リンクとはコンパイル時にリンクを行う手法です. 仕組みは単純ですが,ファイルやメモリの使用量が増える欠点があります. この図で説明したリンクは実は静的リンクでした.
静的リンクしたファイルa.outはリンク済みなので,
ライブラリ関数(例えばprintf)の実体もa.outの中に入っています.

a.outごとにprintfのコピーが作られるので,
ファイルの使用量が無駄に増えてしまいます.
またa.out中のprintfは実行時にもメモリ上で共有されないので,
メモリの使用量も無駄に増えてしまいます.
静的リンクでコンパイルしてみる
// hello.c
#include <stdio.h>
int main (int ac, char **ag)
{
printf ("hello (%d)\n", ac);
}
静的リンクするには-staticオプションをつけます(-static無しだと動的リンクになります).
printfに第2引数を与えているのは,こうしないと,コンパイラが勝手に
printfの呼び出しをputsに変更してしまうことがあるからです.
a.outをfileコマンドで確認するとstatically linkedとあり❶,
静的リンクできたことが分かります.
$ gcc -static hello.c
$ file ./a.out
./a.out: ELF 64-bit LSB executable, x86-64, version 1 (GNU/Linux), ❶statically linked, BuildID[sha1]=40fe6c0daaf2d49fabad4d37bc34fcdd12cb8da9, for GNU/Linux 3.2.0, not stripped
$ ./a.out
hello (1)
練習問題:静的にリンクしたa.out中にprintfの実体があることを確認せよ
a.outを逆アセンブルし,❶<main>:を含む行から15行を表示させます.
(❷-A 14は「マッチした行の後ろ14行も表示する」というオプションです).
main関数は(printfではなく)❸_IO_printfを呼び出していることを確認できます.
$ objdump -d ./a.out | egrep ❷-A 14 ❶"<main>:"
0000000000401cb5 <main>:
401cb5: f3 0f 1e fa endbr64
401cb9: 55 push %rbp
401cba: 48 89 e5 mov %rsp,%rbp
401cbd: 48 83 ec 10 sub $0x10,%rsp
401cc1: 89 7d fc mov %edi,-0x4(%rbp)
401cc4: 48 89 75 f0 mov %rsi,-0x10(%rbp)
401cc8: 8b 45 fc mov -0x4(%rbp),%eax
401ccb: 89 c6 mov %eax,%esi
401ccd: 48 8d 3d 30 33 09 00 lea 0x93330(%rip),%rdi # 495004 <_IO_stdin_used+0x4>
401cd4: b8 00 00 00 00 mov $0x0,%eax
401cd9: e8 72 ec 00 00 callq 410950 ❸<_IO_printf>
401cde: b8 00 00 00 00 mov $0x0,%eax
401ce3: c9 leaveq
401ce4: c3 retq
注:ここでは
egrep -A 14としてますが,皆さんが試す時は,$ objdump -d ./a.out | lessとしてから,
/<main>:とリターンを入力して検索する方が便利でしょう.
次に同じくa.outを逆アセンブルし,`<_IO_printf>:'を含む行から数行を表示させます.
$ objdump -d ./a.out | egrep -A 5 "<_IO_printf>:"
0000000000410950 <_IO_printf>:
410950: f3 0f 1e fa endbr64
410954: 48 81 ec d8 00 00 00 sub $0xd8,%rsp
41095b: 49 89 fa mov %rdi,%r10
41095e: 48 89 74 24 28 mov %rsi,0x28(%rsp)
410963: 48 89 54 24 30 mov %rdx,0x30(%rsp)
これは_IO_printfの定義なので,a.outにprintfの実体があることを確認できました.
なお,以下のnmコマンドでも,a.outにprintfの実体があることを確認できます.
$ nm ./a.out | egrep _IO_printf
0000000000410950 T _IO_printf
実は_IO_printfもprintfも実体は同じです.処理系の都合で,
「実体は同じだけど別の名前をつける」ことがあり,それをエイリアス(別名)といいます.
0x410950番地で調べると,これを確認できます.
$ nm ./a.out | egrep 410950
0000000000410950 T _IO_printf
0000000000410950 T __printf
0000000000410950 T printf
動的リンク
動的リンクとは実行を始める際のロード時(a.outをメモリにコピーする時)
あるいは実行途中にメモリ上でリンクを行う手法です.
現在ではファイルやメモリの消費量を抑えるため,デフォルトで動的リンクが使われることが多いです.
動的リンクしたファイルa.outには
「ライブラリ関数(例えばprintf)とのリンクが必要だよ」という
小さな参照情報だけが入っており,printfの実体は入っていません.
実際のリンクは実行時にメモリ上で行います.

a.outにはprintfを含まないので,ファイルの使用量を抑えられます.
またa.out中のprintfは実行時にはメモリ上で共有されるので,
メモリの使用量も抑えられます.
ファイルサイズを比較してみると,静的リンクしたa.out-staticは約870KB,
動的リンクしたa.out-dynamicは約17KBで,50倍ものサイズ差がありました.
$ gcc -static -o a.out-static hello.c
$ gcc -o a.out-dynamic hello.c
$ ls -l a.out*
-rwxrwxr-x 1 gondow gondow 16696 Jul 20 17:52 a.out-dynamic
-rwxrwxr-x 1 gondow gondow 871832 Jul 20 17:51 a.out-static
動的リンクでコンパイルしてみる
Linuxでは-staticオプションをつけなければ動的リンクになります.
$ gcc hello.c
$ file a.out
a.out: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=308260da4f7fb6d4116c12670adf6e503637abba, for GNU/Linux 3.2.0, not stripped
$ ./a.out
hello (1)
実行時にリンクが必要な動的ライブラリの情報はlddコマンドで表示できます.
$ ldd ./a.out
❶linux-vdso.so.1 (0x00007ffd21638000)
❷libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fcfef5c1000)
❸/lib64/ld-linux-x86-64.so.2 (0x00007fcfef7d8000)
このa.outはlinux-vsdo.so.1,libc.so.6,ld-linux-x86-64.so.2という
3つの動的ライブラリと実行時にリンクする必要があることを表示しています.
libc.so.6は(LD_LIBRARY_PATHなどの設定がなければ)
絶対パス/lib/x86_64-linux-gnu/libc.so.6とリンクされます.
❶linux-vdso.so.1とは
vDSO (virtual dynamic shared objectの略)で,カーネル空間で実行する必要が無い
システムコール(例えばgettimeofday)を高速に実行するための仕組みです.
❷libc.so.6とは
C標準ライブラリが入った動的ライブラリです.
nm -Dコマンドで調べると,printfの実体が入っていることが分かります.
(-Dは共有ライブラリで使われる動的シンボルを表示させるオプションです)
$ nm -D /lib/x86_64-linux-gnu/libc.so.6 | egrep ' T printf'
0000000000061c90 T printf
0000000000061100 T printf_size
0000000000061bb0 T printf_size_info
-Dオプションをつけないと「❶シンボルが無いよ」と言われてしまいます.
(動的シンボル以外はstripされているからです)
$ nm /lib/x86_64-linux-gnu/libc.so.6
nm: /lib/x86_64-linux-gnu/libc.so.6: ❶no symbols
LD_LIBRARY_PATHとは
a.out実行時には,
動的リンカは動的ライブラリをある手順に従って検索します(詳細はman ld).
通常はデフォルトのパス(/libや/usr/libなど)にある動的ライブラリを使いますが,
環境変数LD_LIBRARY_PATHにディレクトリ(複数ある場合は
コロン:で区切る)をセットすることで検索パスを追加できます.
具体的には,
動的リンカはLD_LIBRARY_PATHで指定したディレクトリを
(デフォルトの検索パスよりも先に)検索し,
そこにある動的ライブラリを優先的に使います.
(LD_RUN_PATHも参照下さい).
練習問題:動的にリンクしたa.out中にprintfの実体が無いことを確認せよ
nmコマンドでa.outにはmainを始めごく少数の
関数しか定義しておらず,その中にprintfは入っていないことが以下で確認できます.
$ nm ./a.out | egrep ' T '
00000000000011f8 T _fini
00000000000011f0 T __libc_csu_fini
0000000000001180 T __libc_csu_init
0000000000001149 T main
0000000000001060 T _start
またnmの出力をprintfで検索すると,GLIBC中のprintfへの参照はあるが
a.out中では未定義(U)となっていることが分かります.
$ nm ./a.out | egrep 'printf'
U printf@@GLIBC_2.34
なお逆アセンブルすると<printf@plt>という小さな関数が見つかりますが,
これはprintfの実体ではありません.
$ objdump -d ./a.out | egrep -A 5 "<printf"
0000000000001050 <printf@plt>:
1050: f3 0f 1e fa endbr64
1054: f2 ff 25 75 2f 00 00 bnd jmpq ❶*0x2f75(%rip) # 3fd0 <printf@GLIBC_2.34>
105b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
<printf@plt>はprintfを呼び出す単なる踏み台で,
PLT (procedure linkage table)という仕組みです.
PLTはprintfの最初の呼び出しまでprintfのアドレス解決
(address resolution)を遅延します.具体的には次の2ステップになります.
printf@pltの間接ジャンプ先❶の初期値は「動的リンクする関数(動的リンカ)」になっているため,最初にprintf@pltが呼ばれると,動的リンクを行い,その結果,間接ジャンプ先が「printfの実体」に変更されます❷. そして動的リンカは何もなかったかのようにprintfを呼び出します. (ちなみにprintf@pltの間接ジャンプで参照するメモリ領域は GOT (global offset table)と呼ばれます)- その結果,2回目以降の以下の間接ジャンプ❶では(動的リンカを経由せずに)
printfが呼ばれます.
つまり,GOTにprintfのアドレスを格納することが,ここではアドレス解決になっています.

静的ライブラリを作成してみる
// main.c
#include <stdio.h>
int add5 (int n);
int main (void)
{
printf ("%d\n", add5 (10));
}
// add5.c
int add5 (int n)
{
return n + 5;
}
$ gcc -c add5.c
$ ar rcs libadd5.a add5.o ❶
$ ar t libadd5.a
add5.o ❷
$ file libadd5.a
libadd5.a: current ar archive
$ gcc ❸-static -o a.out-static main.c ❹-L. ❺-ladd5
$ file a.out-static
file ./a.out-static
./a.out-static: ELF 64-bit LSB executable, x86-64, version 1 (GNU/Linux), statically linked, BuildID[sha1]=1bf84a77504302513d6219e4b27316309d08ed2d, for GNU/Linux 3.2.0, not stripped
$ ./a.out-static
15 ❻
- ❶
ar rcsコマンドでadd5.oからlibadd5.aを作成します. - ❷
ar tコマンドでlibadd5.aの中身を調べます.中身はadd5.oだけでした. - ❸❹❺
gccでmain.cとlibadd5.aを静的リンクします. 静的リンクするために❸-staticオプションが必要です.libadd5.aがカレントディレクトリにあることを伝えるために❹-L.が必要です. 静的リンクする静的ライブラリがlibadd5.aであることを伝えるために ❺-ladd5が必要です.(前のlibと後の.aは自動的に付加されます) - ❻ 実行してみると,静的ライブラリ
libadd5.a中のadd5関数を呼び出せました.
動的ライブラリを作成してみる
$ gcc -c add5.c
$ gcc ❶-fPIC ❷-shared -o libadd5.so add5.o
$ file libadd5.so
libadd5.so: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, BuildID[sha1]=415ef51f32145b59c51e836a25959f0f66039768, not stripped
$ gcc main.c -ladd5 -L. ❸-Wl,-rpath .
$ file ./a.out
./a.out: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=a5d4f8ef61cef4e0b063376333f07170d312c546, for GNU/Linux 3.2.0, not stripped
$ ldd ./a.out
linux-vdso.so.1 (0x00007ffff7fcd000)
libadd5.so => ❹./libadd5.so (0x00007ffff7fbd000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007ffff7dad000)
/lib64/ld-linux-x86-64.so.2 (0x00007ffff7fcf000)
$ ./a.out
15 ❺
- ❶❷
add5.cから動的ライブラリlibadd5.soを作ります.libadd5.soを位置独立コード(PIC)にするために,❶-fPICが必要です.libadd5.soを共有オブジェクト(shared object)にするために,❷-sharedが必要です. - ❸
gccでmain.cとlibadd5.soを動的リンクします. 実行時に動的ライブラリを探索するパスを❸-Wl,-rpath .で指定しています. ここではlibadd5.soをカレントディレクトリに置いているためです. (セキュリティ上,実際に使う際は絶対パスを指定する方が安全でしょう). ちなみに-Wl,-rpath .をgccに指定すると,ldコマンド に-rpath .というオプションが渡されます . - ❹
lddコマンドで調べると,a.out中のlibadd5.soは./libadd5.soを参照していることを確認できました. - ❺ 実行してみると,動的ライブラリ
libadd5.so中のadd5関数を呼び出せました.
-rpath,LD_RUN_PATH,LD_LIBRARY_PATH
❸-Wl,-rpath .はコンパイル時に「動的ライブラリの検索パス」をa.out中に埋め込みます.
以下のコマンド等で確認できます(❻の部分).
$ readelf -d ./a.out | egrep PATH
0x000000000000001d (RUNPATH) Library runpath: ❻[.]
-Wl,-rpath .で指定する検索パスは環境変数LD_RUN_PATHでも指定できます.
(複数の検索パスはコロン:で区切ります).
$ export LD_RUN_PATH="."
$ gcc main.c -ladd5 -L.
$ readelf -d ./a.out | egrep PATH
0x000000000000001d (RUNPATH) Library runpath: [.]
LD_LIBRARY_PATHを使うと,
a.out中の検索パス以外の動的ライブラリを実行時に動的リンクできます.
例えば,以下でlddコマンドを使うと,
/tmp/libadd5.soが使われることを確認できます❼.
$ export LD_LIBRARY_PATH="/tmp"
$ cp libadd5.so /tmp
$ ldd ./a.out
libadd5.so => ❼/tmp/libadd5.so (0x00007ffffffb8000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fffffd8b000)
/lib64/ld-linux-x86-64.so.2 (0x00007ffffffc4000)
なおLD_LIBRARY_PATHは危険で強力なので,なるべく使うのは避けるべきです.
使う場合は最新の注意を払って使いましょう.
なぜならば,例えば,/tmp/libc.so.6という悪意のある動的ライブラリがあると,
/tmp/libc.so.6中のprintfが呼び出されてしまうからです.
(このprintfの中身はコンピュータウイルスかも知れません)
位置独立コードとは
位置独立コード(position independent code, PIC)とはメモリ上の どこにロードしても,そのまま実行できるコードです. 位置独立コードでは絶対アドレスは使わず(再配置が必要になってしまうから), 相対アドレスか間接アドレス参照だけを使います. 位置独立コードにすることで,メモリ上で動的ライブラリを共有できるため, メモリ使用量を抑えることができます.
デバッグ情報
デバッグ情報とは
デバッグ情報とはgccに-gオプションをつけると
バイナリに付加される情報で,
デバッグ時に有用なソースコード中の情報を含んでいます.
例えば,変数の型情報や,ソースコード中の行番号が挙げられます.
$ gcc ❶ -g main.c add5.c
$ file ./a.out
./a.out: ELF 64-bit LSB pie executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=68a01f5977ae542600062913c447a7ba7f2fad62, for GNU/Linux 3.2.0, ❷ with debug_info, not stripped
❶-gオプションをつけてコンパイルしてから,fileコマンドで調べると,
❷デバッグ情報が含まれていることを確認できます.
コンパイラは様々なデバッグ情報の形式を扱えます. LinuxのELFバイナリではDWARFデバッグ情報 が使われることが多いです.(以下,DWARFを前提として説明します)
デバッグ情報が無いと,デバッガでファイル名や行番号が表示されない
デバッグ情報無しでデバッガgdbを使うとどうなるか試してみましょう.
add5.cとmain.cは
前節と同じものを使います.
(gdbの使い方の詳細はデバッガgdbの使い方を参照下さい).
$ gcc ❶ main.c add5.c
$ gdb ./a.out
(gdb) ❷ b add5
Breakpoint 1 at 0x1175
(gdb) ❸ r
Starting program: /tmp/a.out
Breakpoint 1, 0x0000555555555175 in ❹ add5 ()
(gdb) bt
#0 ❻ 0x0000555555555175 in ❺ add5 ()
#1 0x000055555555515b in main ()
(gdb) quit
-gオプション無しで❶コンパイルしています.
add5関数にブレークポイントを設定❷します.
ブレークポイントとはプログラムの実行を一時的に停止する場所です.
関数名add5でブレークポイントを指定したので,
実行するとadd5関数の先頭で実行が一時停止します.
❸ runコマンド (rはrunコマンドの省略形)で実行した所,
add5関数でブレーク(実行を一時停止)できたのですが,
関数名add5だけが表示され,ファイル名や行番号が表示されません❹.
バックトレースを出力しても同様です❺.
バックトレースとは「main関数から現在実行中の関数までの,
関数呼び出し系列」のことです.
ここではmain関数がadd5関数を呼び出しただけなので,
バックトレースは2行しかありません.
❻0x0000555555555175はadd5関数が
0x0000555555555175番地の機械語命令を実行する直前で実行を停止していることを
示しています.
デバッグ情報があると,デバッガでファイル名や行番号が表示される
今回はデバッグ情報ありでデバッガを使ってみます.
$ gcc ❶ -g main.c add5.c
$ gdb ./a.out
(gdb) b add5
Breakpoint 1 at 0x1175: ❷ file add5.c, line 2.
(gdb) r
Starting program: /tmp/a.out
Breakpoint 1, add5 (n=10) at ❸ add5.c:2
2 {
(gdb) bt
#0 add5 (n=10) at ❹ add5.c:2
#1 0x000055555555515b in main () at main.c:5
$ gcc ❶ -g main.c add5.c
$ gdb ./a.out
(gdb) b add5
Breakpoint 1 at 0x1183: ❷ file add5.c, line 3.
(gdb) r
Breakpoint 1, add5 (n=10) at ❸ add5.c:3
3 return n + 5;
(gdb) bt
#0 add5 (n=10) at ❹ add5.c:3
#1 0x000055555555515b in main () at main.c:5
- ❶
-gをつけたので,a.outにはデバッグ情報が付加されています. - 先程とは異なり,❷❸❹ファイル名
add5.cや行番号3が付加されています.
デバッグ情報があると,行番号とアドレスを相互変換できる.
アドレス→行番号の変換
デバッグ情報があるバイナリに対しては,
addr2lineコマンドでアドレスを対応する行番号に変換できます.
$ gcc -g main.c add5.c
$ objdump -d ./a.out | egrep -A 4 "<main>:"
0000000000001149 <main>:
1149: f3 0f 1e fa endbr64
114d: 55 push %rbp
114e: 48 89 e5 mov %rsp,%rbp
1151: bf 0a 00 00 00 mov $0xa,%edi
$ addr2line -e ./a.out ❶ 0x1149
❷/tmp/main.c:4
上の実行例ではaddr2lineコマンドで,
0x1149番地の機械語命令はソースコードでは❷/tmp/main.cの4行目に
対応していることが分かりました.
デバッガ上でも確かめてみましょう.
(gdb) b main
Breakpoint 1 at 0x1151: file main.c, line 5.
(gdb) r
Breakpoint 1, main () at main.c:5
5 printf ("%d\n", add5 (10));
(gdb) ❶ disas
Dump of assembler code for function main:
0x0000555555555149 <+0>: endbr64
0x000055555555514d <+4>: push %rbp
0x000055555555514e <+5>: mov %rsp,%rbp
=> 0x0000555555555151 <+8>: mov $0xa,%edi
0x0000555555555156 <+13>: call 0x555555555178 <add5>
(以下略)
(gdb) ❷ info line *0x0000555555555149
Line 4 of "main.c" starts at address 0x555555555149 <main>
and ends at 0x555555555151 <main+8>.
(gdb) ❸ info line main.c:4
Line 4 of "main.c" starts at address 0x555555555149 <main>
and ends at 0x555555555151 <main+8>.
- (objdumpコマンドでも可能ですが)
gdb上でも逆アセンブルできます. 逆アセンブルのコマンドはdisassembleですが長いので, 短縮名disasをここでは使っています. (gdbは他のコマンドと区別できる範囲で,コマンド名を省略できます). ASLRとPIEが有効な場合, デバッガ上で逆アセンブルすると,実際のメモリのアドレスが表示されて便利です. この場合,上では0x1149番地だったのに,0x0000555555555149番地に変わっています. gdbの❷info lineコマンドを使うと,アドレスから行番号に変換できます.0x555555555149番地はmain.cの4行目に対応しており, また,この行は機械語命令では0x555555555149番地から0x555555555151に 対応していると表示されています.gdb上では❸info lineコマンドを使って, 行番号からアドレスへの変換もできます.
なお,gdbでlayout asmとすると逆アセンブル結果を常に表示できます.
ブレークポイント(左端のbやB)や次に実行する機械語命令の位置(>)が
表示されて分かりやすいです.
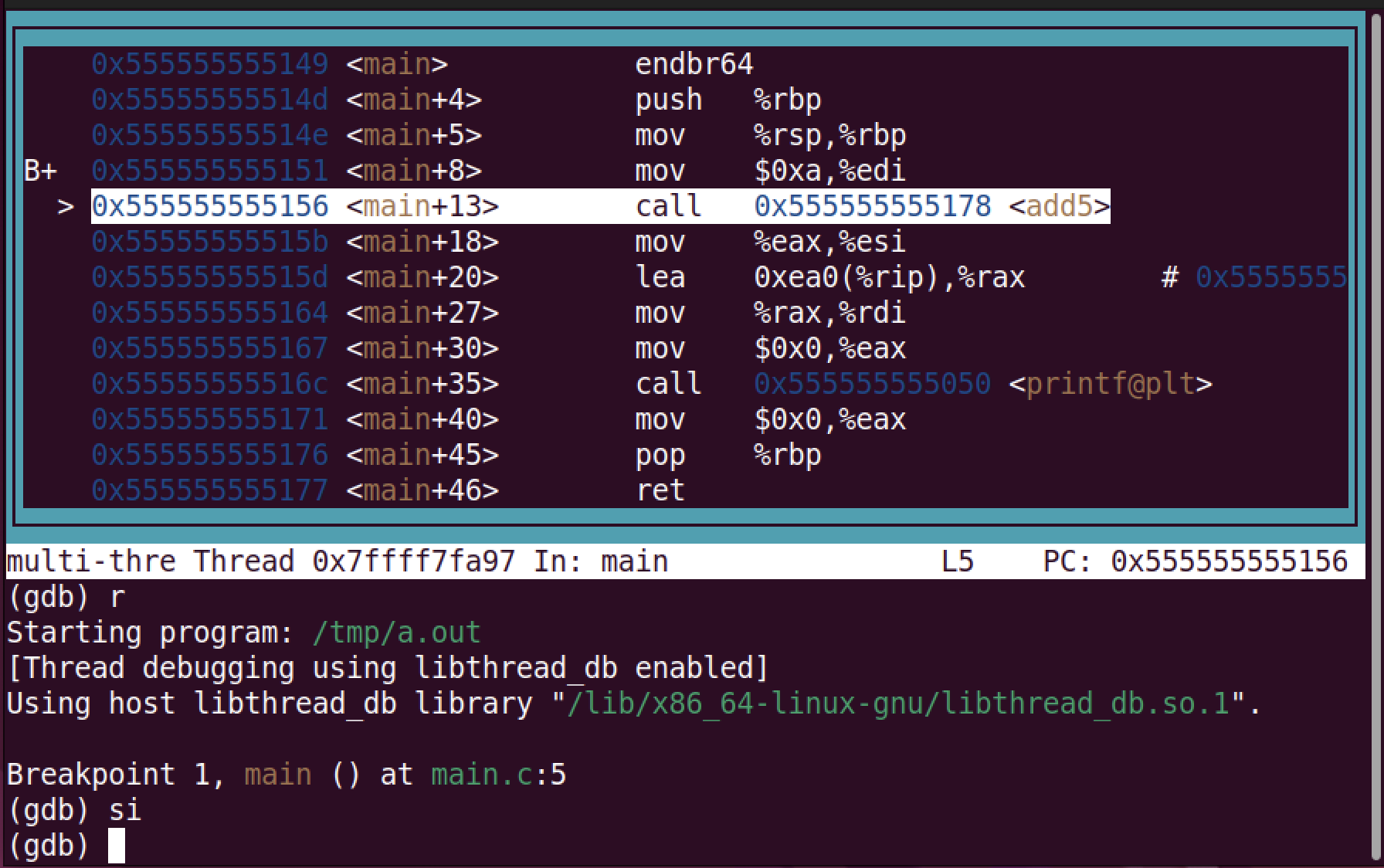
B+ってどういう意味
Bは少なくても一度はブレークしたブレークポイントbは一度もブレークしていないブレークポイント+は有効化されているブレークポイント-は無効化されているブレークポイント
行番号→アドレスの変換
コマンドライン上で,行番号をアドレスに変換するには
(コマンドがちょっと長くなりますが)以下のようにgdbを使います.
$ gdb ./a.out -ex "info line main.c:4" --batch
Line 4 of "main.c" starts at address ❶0x1149 <main> and ends at 0x1151 <main+8>.
上ではプログラムを実行せずにアドレスを取得したので,
a.outファイル中のアドレス❶0x1149が表示されています.
実行時のアドレスを表示したいなら,以下のようにします
(バッチモードで,b main,run,info line main.c:4という3つのコマンドを実行しています).
実行時のアドレス❷0x555555555149を表示できました.
$ gdb ./a.out -ex "b main" -ex "r" -ex "info line main.c:4" --batch
Breakpoint 1, main () at main.c:5
5 printf ("%d\n", add5 (10));
Line 4 of "main.c" starts at address ❷0x555555555149 <main> and ends at 0x555555555151 <main+8>.
以下のようにline2addrなどの名前でシェル関数を定義すれば,
短く書けます(が,そんなに頻繁には使わないかも).
$ function line2addr () {
> command gdb $1 -ex "info line $2" --batch
> }
$ line2addr ./a.out main.c:4
Line 4 of "main.c" starts at address 0x1149 <main> and ends at 0x1151 <main+8>.
デバッグ情報があると,逆アセンブル時にソースコードも表示できる
デバッグ情報がある場合,
(objdump -dではなく)objdump -Sで逆アセンブルすると
ソースコードも表示できます.
❶関数add5の定義部分であること,
❷return n + 5;の行のコンパイル結果であること,
などが見やすくなります.
$ gcc -g -c add5.c
$ objdump -S ./add5.o
./add5.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <add5>:
❶ int add5 (int n)
{
0: f3 0f 1e fa endbr64
4: 55 push %rbp
5: 48 89 e5 mov %rsp,%rbp
8: 89 7d fc mov %edi,-0x4(%rbp)
❷ return n + 5;
b: 8b 45 fc mov -0x4(%rbp),%eax
e: 83 c0 05 add $0x5,%eax
}
11: 5d pop %rbp
12: c3 ret
デバッガでレジスタの値を確認する
デバッガでレジスタの値を確認できます.
$ gcc -g main.c add5.c
$ gdb ./aout
(gdb) b add5
Breakpoint 1 at 0x1183: file add5.c, line 3.
(gdb) r
Breakpoint 1, add5 (n=10) at add5.c:3
3 return n + 5;
(gdb) p ❶ $rdi
$1 = 10
(gdb) ❷ info reg
Undefined info command: "regs". Try "help info".
(gdb) info reg
rax 0x555555555149 93824992235849
rbx 0x0 0
rcx 0x555555557dc0 93824992247232
rdx 0x7fffffffe048 140737488347208
rsi 0x7fffffffe038 140737488347192
rdi 0xa 10
(以下略,qを押して表示を停止)
- ❶
gdbでは%ではなく$をつけてレジスタ名を指定します.pはprintコマンドの省略名です.%rdiの値が10であることが分かりました. 16進数で表示したい場合は,p/x $rdiと/xをつけます - ❷ レジスタの値一覧は
info regで表示できます.ページャが起動されるので,qを押して表示を停止します.
gdbでlayout regsとすると,レジスタの値を常に表示できます.
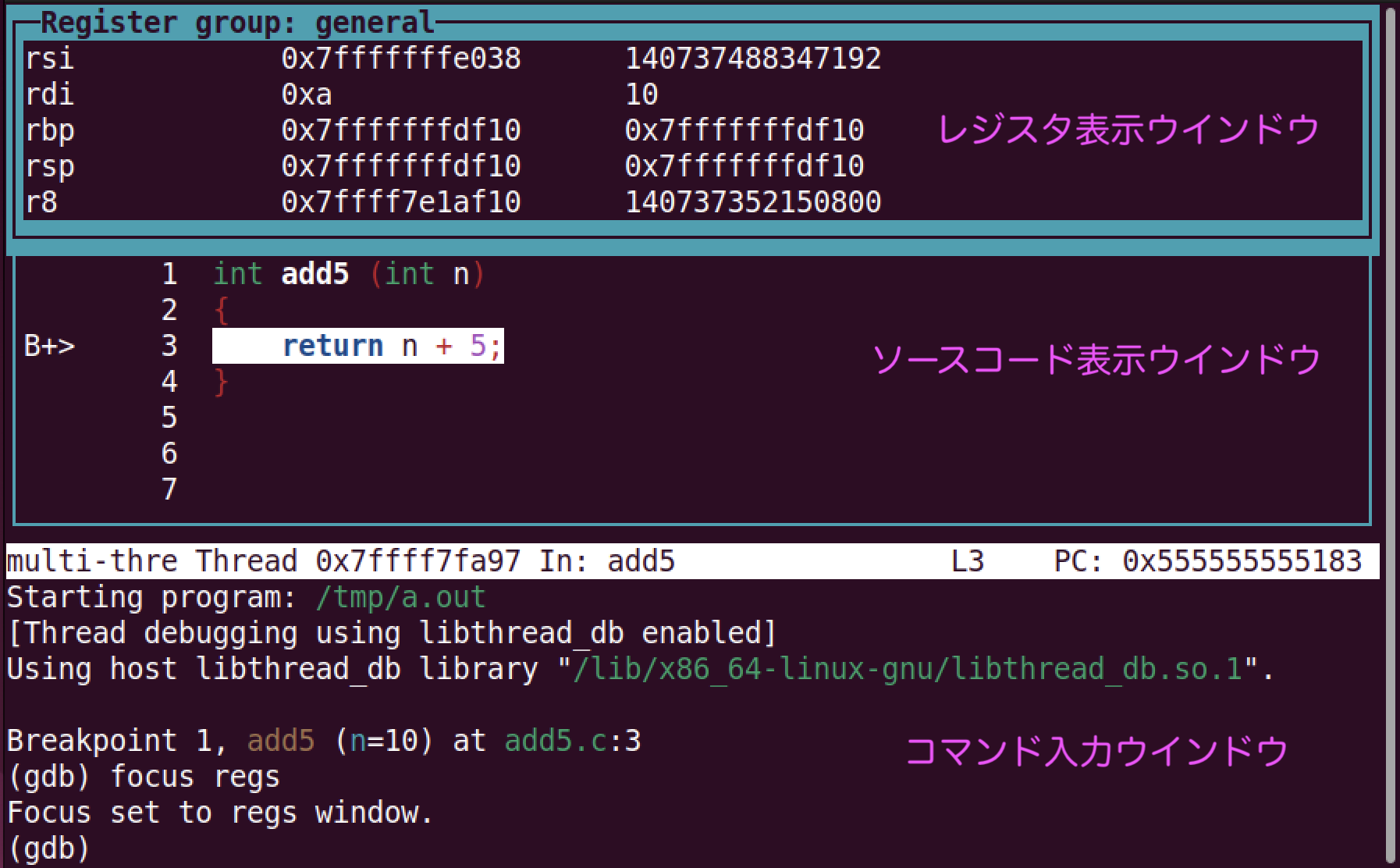
layout regsするとレジスタの値一覧が表示されます. 上から「レジスタ表示」「ソースコード表示」「コマンド入力」のためのウィンドウです.focus regsや,ctrl-x oなどを入力すると,レジスタ表示ウィンドウが選択されます. この状態で↓キーを押すと(あるいはマウスでスクロールされると) レジスタ表示ウィンドウの表示をスクロールできます.ctrl-x aを入力すると,元の表示方法に戻ります.
デバッガでメモリの値を確認する
add5.cとmain.cを
を実行し,add5関数のスタックフレームが作成された直後は
以下の図(ここで使った図の再掲)
になっています.

これをデバッガで確認しましょう.
$ gcc -g main.c add5.c
$ gdb ./a.out
(gdb) b add5
Breakpoint 1 at 0x1183: file add5.c, line 3.
(gdb) r
Breakpoint 1, add5 (n=10) at add5.c:3
3 return n + 5;
(gdb) disas
Dump of assembler code for function add5:
0x0000555555555178 <+0>: endbr64
0x000055555555517c <+4>: push %rbp
0x000055555555517d <+5>: mov %rsp,%rbp
0x0000555555555180 <+8>: mov %edi,-0x4(%rbp)
=> 0x0000555555555183 <+11>: mov -0x4(%rbp),%eax
0x0000555555555186 <+14>: add $0x5,%eax
0x0000555555555189 <+17>: pop %rbp
0x000055555555518a <+18>: ret
(gdb) ❶ p/x $rsp
$1 = 0x7fffffffdf10
(gdb) ❷ p/x $rbp
$2 = 0x7fffffffdf10
(gdb) ❸ x/1gx 0x7fffffffdf10
0x7fffffffdf10: 0x00007fffffffdf20
(gdb) ❹ x/1gx $rsp
0x7fffffffdf10: 0x00007fffffffdf20
(gdb) ❺ x/8bx $rsp
0x7fffffffdf10: 0x20 0xdf 0xff 0xff 0xff 0x7f 0x00 0x00
-
❶❷
%rspと%rbpレジスタの値を調べると,どちらも0x7fffffffdf10番地でした. -
❸
x/1gx 0x7fffffffdf10はメモリの中身を表示するコマンドです.xのコマンド名は examine memory から来ています./1gxは出力形式を指定しています. この場合は「8バイトのデータを16進表記で1つ表示」という意味です.
xコマンドの表示オプション
xコマンドの表示オプションには以下があります(他にもあります).
x16進数d符号あり10進数u符号なし10進数t2進数c文字s文字列
データのサイズ指定には以下があります.
b1バイト (byte)h2バイト (halfword)w4バイト (word)g8バイト (giant)
サイズの用語がバラバラ過ぎる!
以下の通り,GNUアセンブラ(AT&T形式),Intel形式,gdbで各サイズに対する
用語がバラバラです.混乱しやすいので要注意です.
| 1バイト | 2バイト | 4バイト | 8バイト | |
|---|---|---|---|---|
| GNUアセンブラ | byte (b) | short (s) | long (l) | quad (q) |
| Intel形式 | byte | word | double word (dword) | quad word (qword) |
gdb | byte (b) | halfword (h) | word (w) | giant (g) |
- ❹ 具体的なアドレス(ここでは
0x7fffffffdf10)ではなく, レジスタ名 (ここでは$rsp)を指定して, そのレジスタが指しているメモリの中身を表示できます. - ❺
/1gxではなく/8bxと表示形式を指定すると, 「1バイトのデータを16進表記で8個表示」という意味になります.0x7FFFFFFFDF10から0x7FFFFFFFDF17までの各番地には,それぞれ, 以下の図の通り,0x20,0xDF,0xFF,0xFF,0xFF,0x7F,0x00,0x00という値が メモリ中に入っていることが分かります. この格納されている8バイトのデータ0x00007fffffffdf20はアドレスであり, 以下の図の一番下のアドレス(赤字の部分)を指しています.

(上のデバッグの続き)
(gdb) ❻ x/1gx $rsp+8
0x7fffffffdf18: 0x000055555555515b
(gdb) ❼ x/8bx $rsp+8
0x7fffffffdf18: 0x5b 0x51 0x55 0x55 0x55 0x55 0x00 0x00
(gdb) ❽ disas 0x000055555555515b
Dump of assembler code for function main:
0x0000555555555149 <+0>: endbr64
0x000055555555514d <+4>: push %rbp
0x000055555555514e <+5>: mov %rsp,%rbp
0x0000555555555151 <+8>: mov $0xa,%edi
0x0000555555555156 <+13>: call 0x555555555178 <add5>
❾ 0x000055555555515b <+18>: mov %eax,%esi
0x000055555555515d <+20>: lea 0xea0(%rip),%rax # 0x555555556004
0x0000555555555164 <+27>: mov %rax,%rdi
0x0000555555555167 <+30>: mov $0x0,%eax
0x000055555555516c <+35>: call 0x555555555050 <printf@plt>
0x0000555555555171 <+40>: mov $0x0,%eax
0x0000555555555176 <+45>: pop %rbp
0x0000555555555177 <+46>: ret
End of assembler dump.
- ❻
x/1gxを使って,上の図の8(%rsp)のアドレスの中身を表示させています.8(%rsp)の意味は「%rspの値に8を足したアドレス」です.gdb中では「$rsp + 8」と入力します. - ❼
x/8bxを使って,上の図の8(%rsp)のアドレスを1バイトごとに表示しました. 上記の図の通り,0x7FFFFFFFDF18から0x7FFFFFFFDF1Fまでの各番地には,それぞれ,0x5B,0x51,0x55,0x55,0x55,0x55,0x00,0x00が 格納されていることが分かりました. - ❻の結果で得た
0x000055555555515b番地を使って❽逆アセンブルしてみると, ❾この番地は「call add5」の次の命令 (この場合はmov %eax, %esi)であることが 分かりました. このように,戻り番地 (return address)は通常, 「その関数を呼び出したcall命令の次の命令のアドレス」になります.
戻り番地が通常ではない場合って?
末尾コール最適化 (tail-call optimization; TCO)が起こった時が該当します.
- 上の「末尾コール最適化の前」の図では
main関数がAを呼び, 関数AがBを呼んでいます.また逆の順番でリターンします. しかし,call Bの次の命令がret(次の命令❷)になっているため, 関数Bからリターンした後,関数Aでは何もせず,mainにリターンしています. - そこで「末尾コール最適化の後」の図のように,関数
A中のcall命令を 無条件ジャンプ命令jmpに書き換えて,関数Bからは(Aを経由せず) 直接,main関数のリターンするように書き換えて無駄なリターンを省くことができます. これが末尾コール最適化です. - その結果,関数
Bのリターンアドレスは,関数A中のcall命令の次のアドレス (次の命令❷)ではなく,関数main中の「次の命令❶」となってしまいました. これが戻り番地が通常ではない場合の一例です.
デバッグ情報を直接見る
objdump,readelf,llvm_dwarfdumpコマンドを使うと,
デバッグ情報の中身を直接見ることができます.
objdump -W
デバッグ情報には例えば,以下のものがあります
- デバッグ情報 (
.debug_info) - 行情報 (
.debug_line) - アドレス情報 (
.debug_aranges) - フレーム情報 (
.eh_frame) - 省略情報 (
.debug_abbrev)
objdump -W add5.o とすると,add5.o中のデバッグ情報を全て表示します
-Wi, -Wl, -Wr, -Wf,-Waとすると,
それぞれ,デバッグ情報,行情報,アドレス情報,フレーム情報,
省略情報だけを表示できます.
$ objdump -W add5.o | less
add5.o: file format elf64-x86-64
Contents of the .debug_info section:
Compilation Unit @ offset 0x0:
Length: 0x62 (32-bit)
Version: 5
Unit Type: DW_UT_compile (1)
Abbrev Offset: 0x0
Pointer Size: 8
<0><c>: Abbrev Number: 1 (DW_TAG_compile_unit)
<d> DW_AT_producer : (indirect string, offset: 0x5): GNU C17 11.3.0 -mtune=generic -march=x86-64 -g -fasynchronous-unwind-tables -fstack-protector-strong -fstack-clash-protection -fcf-protection
<11> DW_AT_language : 29 (C11)
<12> DW_AT_name : (indirect line string, offset: 0x5): add5.c
(以下略)
上記の出力例では例えば「ファイル名add5.cを省略番号1とします」という情報を含んでいます(詳細は省略し.
コンパイル単位 (compile unit)とはファイルのことです.
例えば,以下の部分は
仮引数の情報として「変数名は❻n,
❷add5.cの❸1行目❹15カラム目で宣言されていて,
型は❺<0x5e>を見てね.変数の場所は❻(DW_OP_fbreg: -20)」となってます.
<2><50>: Abbrev Number: 3 (DW_TAG_formal_parameter)
<51> DW_AT_name : ❶ n
<53> DW_AT_decl_file : ❷ 1
<54> DW_AT_decl_line : ❸ 1
<55> DW_AT_decl_column : ❹ 15
<56> DW_AT_type : ❺ <0x5e>
<5a> DW_AT_location : 2 byte block: 91 6c ❻ (DW_OP_fbreg: -20)
❻DW_OP_fbreg: -20とは
「CFA (canonical frame address)から -20バイトのオフセットの位置」を意味しています.
CFAはDWARFデバッグ情報が定める仮想的なレジスタでCPUごとに異なります.
x86-64の場合は「call命令を実行する直前の%rspの値」なので,以下になります.
(call命令が戻り番地をスタックにプッシュすることを思い出しましょう).
引数n(下図で赤い部分)の先頭アドレスは,
CFAからちょうど-20バイトの場所にあることが確認できました.

-fomit-frame-pointerでコンパイルされていなければ,
(通常は関数の先頭でpush %rbpするので)以下の式が成り立ちます.
CFA == %rbp + 16
なお,fbreg は frame base registerの略だと思います.
Abbrev Number (省略番号)とは
例えば,以下のDIE(デバッグ情報の部品)で Abbrev Number は ❶4となっています.
$ objdump -Wi add5.o
(一部略)
<1><5e>: Abbrev Number: ❶4 (DW_TAG_base_type)
<5f> DW_AT_byte_size : 4
<60> DW_AT_encoding : 5 (signed)
<61> DW_AT_name : int
objdump -Waで.debug_abbrevを表示すると4番目のエントリは
以下となっています.つまり,
- ❷4番のAbbrev Number (省略番号)を持つDIEは ❸DW_TAG_base_type である
- DW_TAG_base_typeには例えば,❹変数名の情報があり,その型は❺DW_FORM_stringである
と分かります.
$ objdump -Wa add5.o
(一部略)
❷4 ❸DW_TAG_base_type [no children]
DW_AT_byte_size DW_FORM_data1
DW_AT_encoding DW_FORM_data1
❹DW_AT_name ❺DW_FORM_string
DW_AT value: 0 DW_FORM value: 0
要するに.debug_abbrevの情報は.debug_infoのメタ情報(型情報)であり,
この場合,4という数字を保持するだけで,
「このDIEはDW_TAG_base_typeである.その内容は…(以下略)」
という情報を持てるのです.
これによりサイズの圧縮が可能になっています.
objdump -Wはある程度は散っている情報をまとめて表示していて親切です.
LEB128とは
LEB128 (little endian base 128)は任意の大きさの整数を扱える 可変長の符号化方式です.直感的にはLEB128はUTF-8の整数版です.
LEB128はDWARFやWebAssemblyなどで使われています. (ですので,DWARFデバッグ情報にはLEB128の符号化が使われている箇所があります. デバッグ情報の16進ダンプを解析する際は注意しましょう).
LEB128には符号ありと符号なしの2種類がありますが,以下では符号なしで説明します.
ここでは123456を符号なしLEB128形式に変換します.
結果は最下位バイトから,0xC0,0xC4,0x07の3バイトになります.
まずbcコマンドで2進数にします❶.
$ bc
obase=2
123456
❶ 11110001001000000
次に以下のステップを踏みます.
ステップ4の結果をbcコマンドで16進数にします❷.
$ bc
obase=16
ibase=2
000001111100010011000000
❷ 7C4C0
結果の16進数❷0x7C4C0 を1バイトごとに最下位バイトから出力すると,
最終的な結果は0xC0,0xC4,0x07となります.
LEB128の最上位バイトの最上位ビットは必ず0で,
それ以外のバイトはの最上位ビットは1なので,
サイズ情報がなくても,
元の整数に戻す際,どのバイトまで処理すればよいかが分かります.
型の情報<0x5e>は以下にありました.
「サイズは❼ 4バイト,❽符号あり,型名は❾int」です.
<1><5e>: Abbrev Number: 4 (DW_TAG_base_type)
<5f> DW_AT_byte_size : ❼ 4
<60> DW_AT_encoding : 5 ❽ (signed)
<61> DW_AT_name : ❾ int
上記の.debug_info中の情報である,
DW_TAG_formal_parameterやDW_TAG_base_typeなどは
DIE (debug information entry)というデバッグ情報の単位の1つです.
DIEは全体で木構造になっています.

またデバッグ情報情報があちこちに散っています. 例えば,❷「ファイル1」の情報はどこにあるかというと
<53> ❷ DW_AT_decl_file : 1
行情報にありました.
以下でエントリ1の情報を見ると,add5.cと分かりました.
$ objdump -Wl add5.o | less
(中略)
The File Name Table (offset 0x2c, lines 2, columns 2):
Entry Dir Name
0 0 (indirect line string, offset: 0x11): add5.c
1 0 (indirect line string, offset: 0x18): add5.c
readelf
readelfコマンドでもobjdumpと同様にDWARFデバッグ情報を表示できます.
以下は実行例です.
$ readelf -wi ./add5.o
Contents of the .debug_info section:
Compilation Unit @ offset 0x0:
Length: 0x62 (32-bit)
Version: 5
Unit Type: DW_UT_compile (1)
Abbrev Offset: 0x0
Pointer Size: 8
<0><c>: Abbrev Number: 1 (DW_TAG_compile_unit)
<d> DW_AT_producer : (indirect string, offset: 0x5): GNU C17 11.3.0 -mtune=generic -march=x86-64 -g -fasynchronous-unwind-tables -fstack-protector-strong -fstack-clash-protection -fcf-protection
<11> DW_AT_language : 29 (C11)
<12> DW_AT_name : (indirect line string, offset: 0x5): add5.c
<16> DW_AT_comp_dir : (indirect line string, offset: 0x0): /tmp
<1a> DW_AT_low_pc : 0x0
<22> DW_AT_high_pc : 0x13
<2a> DW_AT_stmt_list : 0x0
(以下略)
メモリマップを見る
pmapコマンドでメモリマップを見る
pmapコマンドを使うと,
実行中のプログラム(プロセス)がどのメモリ領域を使用しているか
(メモリマップ)を調べられます.
(この出力は/procファイルシステムの /proc/プロセス番号/mapsの内容から作られています).
$ cat
❶ ^Z
[1]+ Stopped cat
$ ps | egrep cat
❷ 7687 pts/0 00:00:00 cat
$ ❸ pmap 7687
7687: cat
❼000055f74daf2000 8K r---- cat
❼000055f74daf4000 16K r-x-- cat
❼000055f74daf8000 8K r---- cat
❼000055f74dafa000 4K r---- cat
❼000055f74dafb000 4K rw--- cat
000055f74dafc000 132K rw--- [ anon ]
00007f63a7e00000 6628K r---- locale-archive
00007f63a8600000 160K r---- libc.so.6
00007f63a8628000 1620K r-x-- libc.so.6
00007f63a87bd000 352K r---- libc.so.6
00007f63a8815000 16K r---- libc.so.6
00007f63a8819000 8K rw--- libc.so.6
00007f63a881b000 52K rw--- [ anon ]
00007f63a8829000 148K rw--- [ anon ]
00007f63a885d000 8K rw--- [ anon ]
00007f63a885f000 8K r---- ld-linux-x86-64.so.2
00007f63a8861000 168K r-x-- ld-linux-x86-64.so.2
00007f63a888b000 44K r---- ld-linux-x86-64.so.2
00007f63a8897000 8K r---- ld-linux-x86-64.so.2
00007f63a8899000 8K rw--- ld-linux-x86-64.so.2
❹ 00007fff86f9f000 132K ❺rw--- ❻[ stack ]
00007fff86ff8000 16K r---- [ anon ]
00007fff86ffc000 8K r-x-- [ anon ]
ffffffffff600000 4K --x-- [ anon ]
total 9560K
$ fg
❽ ^D
-
まず
catコマンドを起動します.ファイル名を指定していないので, 標準入力からの入力待ちになります. ここで❶ ctrl-z を入力して,catコマンドの実行を中断 (suspend)します.pmapコマンドは実行中のプロセスにしか実行できないため,catコマンドが実行中のまま終了しないように,こうしています. -
次に
psコマンドでcatコマンドのプロセス番号を調べます. ❷7687がプロセス番号と分かりました. -
❸プロセス番号7687を引数として
pmapコマンドを実行します. -
出力の各行が使用中のメモリ領域の情報を示しています.例えば,❹の行は次を意味しています.
❹ 00007fff86f9f000 132K ❺rw--- ❻[ stack ]- ❹アドレス`00007fff86f9f000'からサイズ132KBの領域を使用している.
- このメモリ領域の❻アクセス権限は読み書きが可能で,実行は不可.
r読み込み可能w書き込み可能x実行可能
- このメモリ領域は❻スタックとして使用している
-
catコマンド自身は以下の5つのメモリ領域を使用しています.❼000055f74daf2000 8K r---- cat ❼000055f74daf4000 16K r-x-- cat ❼000055f74daf8000 8K r---- cat ❼000055f74dafa000 4K r---- cat ❼000055f74dafb000 4K rw--- cat- アクセス権限が
r-x--のものは,.textセクションでしょう. (.textセクションは通常,実行可能かつ書き込み禁止にするからです) - アクセス権限が
rw----のものは,.dataセクションでしょう. (.dataセクションは通常,実行禁止かつ書き込み可能にするからです) - 残りの3つのアクセス権限が
r----のものは,.rodataセクションなどでしょう. (詳細は調べていません) - 使用しているサイズが4KBの倍数なのは,x86-64でよくある
ページ(page)サイズが4KBだからです.
(ページとは仮想記憶方式の1つであるページングで使われる,
固定長(例えば4KB)に区切ったメモリ領域のことです).
プロセスは
mmapシステムコールを使って,OSからページ単位でメモリを割り当ててもらい,その際にページごとにアクセス権限を設定できます.
- アクセス権限が
-
最後に❽で,中断していた
catコマンドをfgコマンドで実行を再開し,ctrl-Dを入力してcatコマンドの実行を終了しています.
gdbでメモリマップを見る
gdbでもメモリマップを見ることができます
$ gdb /usr/bin/cat
(gdb) r
ctrl-z
Program received signal SIGTSTP, Stopped (user).
(gdb) info proc map
process 7821
Mapped address spaces:
Start Addr End Addr Size Offset Perms objfile
0x555555554000 0x555555556000 0x2000 0x0 r--p /usr/bin/cat
0x555555556000 0x55555555a000 0x4000 0x2000 ❶r-xp /usr/bin/cat
0x55555555a000 0x55555555c000 0x2000 0x6000 r--p /usr/bin/cat
0x55555555c000 0x55555555d000 0x1000 0x7000 r--p /usr/bin/cat
0x55555555d000 0x55555555e000 0x1000 0x8000 rw-p /usr/bin/cat
0x55555555e000 0x55555557f000 0x21000 0x0 rw-p [heap]
0x7ffff7400000 0x7ffff7a79000 0x679000 0x0 r--p /usr/lib/locale/locale-archive
0x7ffff7c00000 0x7ffff7c28000 0x28000 0x0 r--p /usr/lib/x86_64-linux-gnu/libc.so.6
0x7ffff7c28000 0x7ffff7dbd000 0x195000 0x28000 r-xp /usr/lib/x86_64-linux-gnu/libc.so.6
0x7ffff7dbd000 0x7ffff7e15000 0x58000 0x1bd000 r--p /usr/lib/x86_64-linux-gnu/libc.so.6
0x7ffff7e15000 0x7ffff7e19000 0x4000 0x214000 r--p /usr/lib/x86_64-linux-gnu/libc.so.6
0x7ffff7e19000 0x7ffff7e1b000 0x2000 0x218000 rw-p /usr/lib/x86_64-linux-gnu/libc.so.6
0x7ffff7e1b000 0x7ffff7e28000 0xd000 0x0 rw-p
0x7ffff7f87000 0x7ffff7fac000 0x25000 0x0 rw-p
0x7ffff7fbb000 0x7ffff7fbd000 0x2000 0x0 rw-p
0x7ffff7fbd000 0x7ffff7fc1000 0x4000 0x0 r--p [vvar]
0x7ffff7fc1000 0x7ffff7fc3000 0x2000 0x0 r-xp [vdso]
0x7ffff7fc3000 0x7ffff7fc5000 0x2000 0x0 r--p /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
0x7ffff7fc5000 0x7ffff7fef000 0x2a000 0x2000 r-xp /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
0x7ffff7fef000 0x7ffff7ffa000 0xb000 0x2c000 r--p /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
0x7ffff7ffb000 0x7ffff7ffd000 0x2000 0x37000 r--p /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
0x7ffff7ffd000 0x7ffff7fff000 0x2000 0x39000 rw-p /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
0x7ffffffde000 0x7ffffffff000 0x21000 0x0 rw-p [stack]
0xffffffffff600000 0xffffffffff601000 0x1000 0x0 --xp [vsyscall]
アクセス権限rwxpの❶pとは
mmapでメモリ領域をマップする際に,
フラグとしてMAP_PRIVATEを指定するとp,
MAP_SHAREDを指定するとsと表示されます.
-
MAP_PRIVATEマップした領域への変更はプロセス間で共有されません. このマップはcopy-on-writeなので,書き込まれるまで自分専用のコピーは発生せず,共有されます. (copy-on-writeとは「書き込みが起こるまでコピーを遅延する」というテクニックです). -
MAP_SHAREDマップした領域への変更はプロセス間で共有されます. すなわちマップした領域に書き込みを行うと, その変更は他のプロセスにも見えます. ただし,msyncを使う必要があります.
❶.textセクションの共有設定もpとなっています.
これは.textセクションもmmapのMAP_PRIVATEでマップしているからです.
動的リンクした実行可能ファイルの.textセクションは
物理メモリ上で共有されていますが,
その共有とMAP_SHAREDは関係ないのです.
再配置情報
再配置情報の概要
再配置情報(relocation information)とは「後でアドレス調整する時のために,
機械語命令中のどの場所をどんな方法で書き換えればよいか」を表す情報です.
オブジェクトファイル*.oは一般的に再配置情報を含んでいます.
// asm/reloc-main.c
#include <stdio.h>
extern int x;
int main ()
{
printf ("%d\n", x);
}
// asm/reloc-sub.c
int x = 999;
例えば,上のreloc-main.cと
reloc-sub.cを見て下さい.
reloc-main.c中で参照している変数xの実体はreloc-main.c中には無く,
実体はreloc-sub.c中にあります.

ですので,reloc-main.s中の
movq x(%rip), %eaxをアセンブルしてreloc-main.oを作っても,
この時点ではxのアドレスが不明なので,仮のアドレス(上図では00 00 00 00)
にするしかありません.
そこで,このmovq x(%rip), %eax命令に対する再配置情報として
「この命令の2バイト目から4バイトを4バイト長の%rip相対アドレスで埋める」
という情報(R_X86_64_PC32,後述)を
reloc-main.o中に保持しておき,リンク時に正しいアドレスを埋め込むのです.

$ gcc -c reloc-main.c
$ gcc -c reloc-sub.c
$ gcc reloc-main.o reloc-sub.o
なんでgccを3回?
通常はgcc reloc-main.c reloc-sub.cと,gccを一回実行して
a.outを作ります.が,ここではreloc-main.oの中の再配置情報を
見たいので,わざわざ別々にreloc-main.oとreloc-sub.oを作り,
最後にリンクしてa.outを作っています.
reloc-main.oとreloc-sub.oをリンクしてa.outを作ると,
(様々な*.o中のセクションを一列に並べることで)
変数xのアドレスが0x4010に決まり,
上図の「次の命令」のアドレスも0x1157に決まりました.
仮のアドレスに埋めたかったのは,%rip相対番地でしたので,
0x4010-0x1157=0x2EB9と計算した0x2EB9番地を仮のアドレスの部分に埋めました.
これが再配置です.
様々な*.o中のセクションを一列に並べることで,とは

例えば上図でfoo2.o中の変数xのアドレスは仮アドレス0x1000ですが,
foo1.oとfoo2.o中のセクションを1列に並べると,
リンク後は「a.outの先頭アドレスが(例えば)0x4000なので,先頭から数えると,
(0x4000 + 0x0500 + 0x1000 = 0x5500という計算をして)
変数xのアドレスは0x5500に決まりますよね」という話です.
objdump -dr で再配置情報を見てみる
$ gcc -g -c reloc-main.c
$ objdump -dr reloc-main.o
./reloc-main.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
0: f3 0f 1e fa endbr64
4: 55 push %rbp
5: 48 89 e5 mov %rsp,%rbp
8: 8b 05 ❶ 00 00 00 00 mov 0x0(%rip),%eax # e <main+0xe>
❷ a: R_X86_64_PC32 x-0x4
e: 89 c6 mov %eax,%esi
10: 48 8d 05 ❸ 00 00 00 00 lea 0x0(%rip),%rax # 17 <main+0x17>
❹ 13: R_X86_64_PC32 .rodata-0x4
17: 48 89 c7 mov %rax,%rdi
1a: b8 00 00 00 00 mov $0x0,%eax
1f: e8 00 00 00 00 call 24 <main+0x24>
20: R_X86_64_PLT32 printf-0x4
24: b8 00 00 00 00 mov $0x0,%eax
29: 5d pop %rbp
2a: c3 ret
前節の説明を,実際に再配置情報を見ることで確かめます.
上の実行例はobjdump -drでreloc-main.oの逆アセンブルの結果と
再配置情報の両方を表示させたものです.
- ❶を見ると図の通り,仮のアドレス
00 00 00 00を確認できます. - ❷の
a: R_X86_64_PC32 x-0x4が再配置情報です.aは仮のアドレスを書き換える場所(.textセクションの先頭からのオフセット)です. 命令mov 0x0(%rip), %eaxの先頭のオフセットが0x8なので,0x8に2を足した値が0xaとなっています (このmov命令の最初の2バイトはオペコード).R_X86_64_PC32は再配置の方法を表しています. 「%rip相対アドレスで4バイト(32ビット)としてアドレスを埋める」ことを意味しています. (PCはプログラムカウンタ,つまり%ripを使うことを意味しています).x-0x4は「変数xのアドレスを使って埋める値を計算せよ. その際に-0x4を足して調整せよ」を意味しています.
-4はどう使うのか
R_X86_64_PC32はSystem V ABIが
定めており,埋めるアドレスのサイズは4バイト(32ビット),
埋めるアドレスの計算方法はS + A - Pと定めています.
Sはそのシンボルのアドレス (上の例では0x4010)Aは調整用の値 (addend と呼びます.上の例では-4)Pは仮アドレスを書き換える場所 (上の例では0x1157 - 4番地)
なので,計算すると
0x4010 + (-4) - (0x1157 - 4) = 0x2EB9
となります.
- ❸は"%d\n"という文字列の仮アドレス,❹はその仮アドレスの再配置情報です. ❶❷と同様です.
readelf -rで再配置情報を見てみる
$ readelf -r reloc-main.o | less
Relocation section '.rela.text' at offset 0x5b0 contains 3 entries:
Offset Info Type Sym. Value Sym. Name + Addend
00000000000a 000a00000002 R_X86_64_PC32 0000000000000000 x - 4
000000000013 000300000002 R_X86_64_PC32 0000000000000000 .rodata - 4
000000000020 000b00000004 R_X86_64_PLT32 0000000000000000 printf - 4
(略)
readelf -rでもobjdump -drと同様の結果が得られます.
PLTの再配置情報
printfの再配置情報も見てみましょう.

$ objdump -dr ./reloc-main.o
./reloc-main.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
0: f3 0f 1e fa endbr64
4: 55 push %rbp
5: 48 89 e5 mov %rsp,%rbp
8: 8b 05 00 00 00 00 mov 0x0(%rip),%eax # e <main+0xe>
a: R_X86_64_PC32 x-0x4
e: 89 c6 mov %eax,%esi
10: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # 17 <main+0x17>
13: R_X86_64_PC32 .rodata-0x4
17: 48 89 c7 mov %rax,%rdi
1a: b8 00 00 00 00 mov $0x0,%eax
1f: e8 ❶ 00 00 00 00 call 24 <main+0x24>
❷ 20: R_X86_64_PLT32 printf-0x4
24: b8 00 00 00 00 mov $0x0,%eax
29: 5d pop %rbp
2a: c3 ret
$ objdump -d ./a.out
0000000000001149 <main>:
1149: f3 0f 1e fa endbr64
114d: 55 push %rbp
114e: 48 89 e5 mov %rsp,%rbp
1151: 8b 05 b9 2e 00 00 mov 0x2eb9(%rip),%eax # 4010 <x>
1157: 89 c6 mov %eax,%esi
1159: 48 8d 05 a4 0e 00 00 lea 0xea4(%rip),%rax # 2004 <_IO_stdin_used+0x4>
1160: 48 89 c7 mov %rax,%rdi
1163: b8 00 00 00 00 mov $0x0,%eax
1168: ❸e8 e3 fe ff ff call 1050 <printf@plt>
116d: b8 00 00 00 00 mov $0x0,%eax
1172: 5d pop %rbp
1173: c3 ret
先程のxの場合とほぼ同じです.
- ❶を見ると図の左側の通り,仮のアドレス
00 00 00 00を確認できます. - ❷の
20: R_X86_64_PLT32 printf-0x4が再配置情報です.20は仮のアドレスを書き換える場所(オフセット)です.R_X86_64_PLT32は再配置の方法を表しており 「printf@pltへの%rip相対アドレス (4バイト(32ビット))を埋める」ことを意味しています.printf-0x4は「変数printf@pltのアドレスを使って埋める値を計算せよ. その際に-0x4を足して調整せよ」を意味しています.
-4はどう使うのか
R_X86_64_PLT32はSystem V ABIが
定めており,埋めるアドレスのサイズは4バイト(32ビット),
埋めるアドレスの計算方法はL + A - Pと定めています.
LはそのシンボルのPLTエントリのアドレス (上の例ではprintf@pltのアドレス0x1050)Aは調整用のaddend (上の例では-4)Pは仮アドレスを書き換える場所 (上の例では0x116D - 4番地)
なので,計算すると
0x1050 + (-4) - (0x116D - 4) = -0x11D = 0xFFFFFEE3
となります.
a.out中では「次の命令」が0x116D番地,printf@pltが0x1050番地と決まったので,0x1050 - 0x116D = -0x11D = 0xFFFFFEE3番地が ❸の部分に埋め込まれました.
ここでも説明した通り,
printfの実体はCライブラリの中にあり,
(gccのデフォルト動作である)動的リンクの場合,
PLTとGOTの仕組みを使って,printfを呼び出します.
これは先程のxの場合は
「(main関数中の)次の命令と変数xの相対アドレスは固定で決まる」のに対して,
printfの場合は固定で決まらないからです
(Cライブラリが実行時に何番地にロードされるか不明だから).

そこで,
main関数中では(printfを直接呼ぶのではなく), (printfのための踏み台である)printf@pltを呼び出す.printf@pltはGOT領域に実行時に書き込まれるprintfのアドレスを使い, 間接ジャンプ (上図ではbnd jmp *0x2f75(%rip))して, 本物のprintfを呼び出す.
という仕組みになっています.
ABI と API
ABIとAPIはどちらも互換性のための規格(お約束)ですが, 対象がそれぞれ,バイナリ,ソースコード,と異なります.
ABI
- ABI = Application Binary Interface
- バイナリコードのためのインタフェース規格.
- 同じABIをサポートするシステム上では再コンパイル無しで 同じバイナリを使ったり実行できる.
- ABIはコーリングコンベンション(関数呼び出し規約, calling convention), バイトオーダ,アラインメント,バイナリ形式などを定める
- Linux AMD64のABI はSystem V ABI (AMD64)
API
- API = Application Programming Interface
- ソースコードのためのインタフェース規格
- 同じAPIをサポートするシステム上では再コンパイルすれば 同じソースコードを実行できる.
- 例えば,POSIXはUNIXのAPIであり,LinuxはPOSIXにほぼ準拠している.
POSIXはシステムコール,ライブラリ関数,マクロなどの形式や意味を定めている- POSIXはここに書いてあるとおり,opengroup.orgに登録することで無料で入手可能