前書き
言い訳
本書はほぼ執筆終了し,講義で使用しながら微修正しています. 不完全な部分があることをお許しください.
しかしながら,誤りの指摘や改善のためのコメントは歓迎いたします. 本書のGithubリポジトリはこちらです.
本書の目的
本書は筆者(権藤克彦)が東京科学大学の 情報工学系で 長年担当したアセンブリ言語の授業の資料をオンライン資料として まとめ直したものです. Intel x86-64,Linux,GNUアセンブラを前提として「アセンブリ言語とは何か」 「具体的にどうプログラミングすればいいのか」を分かりやすくお伝えすることが目的です.
ただし,本書では以下は扱っていません.
- 浮動小数点命令
- (デバイスドライバの実装に必要な)I/O命令
- (OSの実装に必要な)特権命令
- MMX/SSE/AVXなどの拡張命令
いや,書いてもいいのですが分量が膨大になるので面倒くさいんです. もしOS自作に興味があるなら書籍ゼロからのOS自作入門を強くお勧めします.
本書で使う環境
本書では以下の環境を使用しています.皆さんの環境がLinuxであれば多少違っても大丈夫なはずです.
- Ubuntu 22.04 LTS (OS)
- GNU gcc-11.3.0 (コンパイラ)
- GNU binutils-2.38 (バイナリ・ユーティリティ,GNUアセンブラ
asを含む) - GNU gdb-12.1 (デバッガ)
デバッガはアセンブリ言語の実行結果を確認するために便利ですので,ぜひ準備して下さい.
しかし,WindowsやmacOSの場合は,本書の内容と大きく異なってしまいます. アセンブリ言語は環境への依存度が高く,そのため移植性がとても低いからです.
皆さんのパソコンがWindowsやmacOSだった場合,Linux環境を導入する方法として以下のようないろいろな方法があります.筆者のお勧めは
- WindowsならWSL2を使う
- Intel Macなら仮想マシンVirtualBoxをインストールして,Ubuntu Desktopをインストールする (Apple Silicon Mac用のVirtualBoxは2023/12/6時点でベータ版です)
- Apple Silicon Macなら仮想マシンUTM/QEMUをインストールして, (仮想化ではなく)エミュレートでUbuntu Serverをインストールする. なお,Rosettaを使う方法もありますが,もうすぐサポート終了のようです (詳細はこちら).
Linux環境を導入する方法:
- WSL2 (Windows Subsystem for Linux 2)を使えるように設定する.
- VirtualBoxや VMWare Fusion などの仮想マシンをインストールして,その仮想マシン上にUbuntuなどのLinuxをインストールする. Apple Silicon Mac上では,Intel Linuxのイメージは動作不可(2024/3現在).
- UTM/QEMUの仮想マシンに,
(仮想化ではなく)エミュレートでUbuntu ServerなどのLinuxをインストールする.
動作が遅いので,Ubuntu Desktop ではなく Ubuntu Server が良いです.
Ubuntu Serverのコンソールではコピペもできないので,sshでホストマシンからログインできるようにすると便利.
Apple Silicon Mac上で,Intel Linuxのイメージが動作可能.
ただし,仮想環境では
gdbの一部のコマンド(watchなど)が使えないことがあります. - Dockerなどのコンテナ実行環境をインストールして,その上でUbuntuなどのLinuxをインストールする.既存のイメージを使っても良い.Apple Silicon Mac上のDockerで,Intel Linuxのイメージが動作可能です.
gdbを使うには,例えば以下のようにQEMUユーザモード(qemu-x86_64-static)と遠隔デバッグ(target remote :1234)を使う必要があります.この場合,runではなくcontinueで実行を開始する必要があります.
$ qemu-x86_64-static -g 1234 ./a.out &
$ gdb -q -ex "target remote :1234" ./a.out
- オンライン環境(例えばGithub Codespaces)を使う.
Linux環境の導入方法を書くと切りが無いので,皆さん自身でググって下さい.
私が使った Ubuntu 22.04 LTSにはgccなどが未インストールなので,
以下のコマンドでインストールしました.
$ sudo apt install build-essential
$ sudo apt install gdb
本書のライセンス
Copyright (C) 2023 Katsuhiko Gondow
本書はクリエイティブ・コモンズ4.0表示(CC-BY-NC 4.0)で提供します.
本書の作成・公開環境
- マークダウン環境 (v0.4.32) mdbook
- バージョンを上げるとビルドが通らなくなります (pagetoc周りで)
- お絵かきツール draw.io
- 公開環境 Github Pages
本書のお約束
メモリの図では0番地が常に上
本書ではメモリの図を書く時,必ず0番地(低位アドレス)が上, 高位アドレスが下になるようにします.

その結果,本書の図では「スタックは上に成長」,「ヒープは下に成長」することになります (メモリレイアウト).
❶❷などの黒丸数字は説明用
実行結果中の❶や❷などの黒丸数字は,説明のために私が追加したものです.
実行結果の出力ではありません.
例えば,以下が例で,fileコマンドの出力例です.
本文中の説明と実行結果のどこが対応しているのかを明示するために使います.
$ file add5.o
add5.o: ❶ELF 64-bit ❷LSB ❸relocatable, x86-64, ❹version 1 (SYSV), ❺not stripped
Practical Binary Analysis という書籍がこうしていて便利なので真似させてもらっています.
一部を隠してます.
「細かい説明」「演習問題の答え」などはdetailsタグを使って隠しています.
最初は読み飛ばして構いません.読む場合は▶ボタンを押して下さい.
←このボタン(またはこの行)を押してみて下さい
これが隠されていた内容です.
一部の図はタブ表示にしています
一部の図はタブ切り替えでパラパラ漫画のように表示しています. 一度に全部を表示するとゴチャゴチャする場合などに使います. 以下はタブ表示の例です.
サンプルコードがあります
サンプルコード には2種類のファイルがあります.
*.sアセンブリコード*.txtgdbのコマンド列が書かれたファイル
これらのファイルとデバッガgdbを使って機械語命令を実行・確認する方法は,
こちらに説明があります.
(サンプルコードの準備,めっちゃ大変だったので活用して頂けるととても嬉しいです).
(説明せず)擬似コードを使っている部分があります
例えば,mov命令の説明では
movq %rax, %rbxの動作の説明として,%rbx = %raxと書いています.
%rbx = %raxはアセンブリ言語でも無くC言語でも無い,
C言語風の擬似コード(psuedo code)です.
「%raxレジスタの値を%rbxレジスタに格納する」という動作を
簡潔に表現する手段として使わせて下さい.
本書のお断り
2023/10/5現在,日本語検索に対応しました.
「ですます」調と「だである」調がまざってる
すみません,自覚してますがとりあえず放置です. 後で統一するかも知れませんし,しないかも知れません.
サンプルコードのインデントがおかしい
すみません,インデントしたコードブロック中でmdbookの#include機能を使うと 表示が狂ってしまうため,意図的にインデントしていない箇所が多々あります.
Todo
-
Intel CET対応のtigerlakeでサンプルコードを試していない.
デフォルトのビルドで(endbr64が無い)サンプルコードがこけるとまずい どなたか tigerlakeのパソコンを貸して下さい😁
アセンブリ言語の概要
機械語とアセンブリ言語とは何か?(短い説明)
機械語(マシン語):
- CPUが直接実行できる唯一の言語.
- 機械語命令を2進数(バイナリ,数字の列)で表現.
アセンブリ言語:
- 機械語を記号で表現したプログラミング言語.
- 例1:機械語命令
01010101をアセンブリ言語ではpushq %rbpという記号(ニモニック,mnemonic)で表す(x86-64の場合,以下同様). - 例2:メモリのアドレス
1000番地をアセンブリ言語ではadd5などの記号(ラベル)で表す.

pushq %rbpとは
「レジスタ%rbp中の値をスタックにプッシュする」という命令です.
ここで説明します.
2進数の機械語命令と,機械語命令のニモニックは概ね,1対1に対応しており, 機械的に変換できます.ただし,その変換方法を覚える必要はありません. アセンブルや逆アセンブルしてくれる コマンド(プログラム)にやってもらえばいいのです.
ただ,アセンブリ言語の仕組みを理解するには,オブジェクトファイル*.oや
実行可能ファイルa.outの中身や仕組みを理解する必要があるため,
バイナリファイルの節では説明が多くなっています.
機械語とアセンブリ言語の具体例(逆アセンブル)
まず以下の簡単なCのプログラムadd5.cを用意して下さい.
// add5.c
int add5 (int n)
{
return n + 5;
}
add5.cをgcc -cで処理すると,
オブジェクトファイルadd5.oができます.
このadd5.oに対してobjdump -dを実行すると,
逆アセンブル(disassemble)した結果が表示されます.
$ gcc -c add5.c
$ ls
add5.c add5.o
$ objdump -d add5.o
./add5.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <add5>:
0: f3 0f 1e fa endbr64
4: 55 push %rbp
5: 48 89 e5 mov %rsp,%rbp
8: 89 7d fc mov %edi,-0x4(%rbp)
b: 8b 45 fc mov -0x4(%rbp),%eax
e: 83 c0 05 add $0x5,%eax
11: 5d pop %rbp
12: c3 ret
逆アセンブルとは,a.outや*.o中の機械語命令を
アセンブリ言語のニモニック表現に変換することです.
上の実行例で,左側に機械語命令,右側にニモニックが表示されています.
(一番左側の数字は,.textセクションの先頭からのバイト数(16進表記)です).
例えば,4バイト目にある55は機械語命令(を16進数で表記したもの),
55の右側のpush %rbpが,55に対応するニモニックです.
16進数を使っているのは,2進数で表記すると長くなるからです.
Cコードをアセンブリコードにコンパイルする
add5.cに対して,
以下のコマンドを実行して,add5.sを作成して下さい.
これで「アセンブリ言語で書かれたプログラム(アセンブリコード)」がどんなものかを見れます.
$ gcc -S add5.c
$ ls
add5.c add5.s

-Sオプションをつけて処理すると,
gccはCのプログラム(add5.c)からアセンブリコード(add5.s)を生成します.
この処理を「狭義のコンパイル」と呼びます
(広義のコンパイルはCのプログラムから実行可能ファイル(a.out)を
生成する処理を指します).
gcc -Sは「コンパイラ」と呼ばれます.コンパイルするコマンドだからです.
add5.sの中身は例えば以下となります.
注意: gccのバージョンの違いにより,同じLinuxでも
add5.sの中身が以下と異なることがあります.
以下では表示が長いので省略しています.
全てを表示するには右にあるボタンを押して下さい.
(ここではadd5.sの中身は理解できなくてOKです).
$ cat add5.s
.file "add5.c"
.text
.globl add5
.type add5, @function
add5:
.LFB0:
.cfi_startproc
endbr64
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movl %edi, -4(%rbp)
movl -4(%rbp), %eax
addl $5, %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size add5, .-add5
.ident "GCC: (Ubuntu 11.3.0-1ubuntu1~22.04.1) 11.3.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:
このうち実行に関係する部分だけを残したアセンブリコードが以下になります.
# add5.s
.text
.globl add5
.type add5, @function
add5:
pushq %rbp
movq %rsp, %rbp
movl %edi, -4(%rbp)
movl -4(%rbp), %eax
addl $5, %eax
popq %rbp
ret
.size add5, .-add5
各行の意味は次の次の節で説明しますが, ちょっとだけ説明します.
.textなどドット.で始まる命令はアセンブラ命令ですadd5:など名前の後ろにコロン:があるものはラベルの定義です%rbpなど,パーセント%で始まるものはレジスタです$5など,ドル$で始まるものは定数(即値)です.addl $5, %eaxは「レジスタ%eaxの値と定数の5を足し算した結果を%eaxレジスタに格納する」という動作を行う機械語命令です#から行末まではコメントです
AT&T形式とIntel形式とは
x86-64用のアセンブラには本書で扱うGNUアセンブラ以外にも, NASM (netwide assembler)などいくつかあり, 困ったことにアセンブリ言語の表記が異なります. この表記方法には大きく2種類:AT&T形式とIntel形式があります. 本書で扱うGNUアセンブラはAT&T形式,NASMやIntelのマニュアルはIntel形式を使っています.
一番大きな違いは機械語命令の引数(オペランドといいます)の順番です.
- AT&T形式は「左から右へ」,つまり代入先のオペランドを右に書きます
- Intel形式は「右から左へ」,つまり代入先のオペランドを左に書きます

他にもAT&T形式には%や$がつくなど,細かい違いがあります.
ここで詳しく説明します.
なお,gccに-S -masm=intelとオプションを設定すると,
出力されるアセンブリコードをIntel形式に変更できます.
$ gcc -S -masm=intel add5.c
.intel_syntax noprefix
.text
.globl add5
.type add5, @function
add5:
push rbp
mov rbp, rsp
mov DWORD PTR -4[rbp], edi
mov eax, DWORD PTR -4[rbp]
add eax, 5
pop rbp
ret
.size add5, .-add5
(DWORDは4バイト (double word)を意味しています)
なお,消した行の説明を以下に書きますが,読み飛ばしてOKです.
.cfi_とは
.cfiで始まるもの(アセンブラ命令)は call frame information を扱う命令です.
本書の範囲では不要です.詳細はdwarf5仕様書を参照下さい.
.fileと.identとは
.fileと.identはコメントとほぼ同じで,実行には関与しません.
.section .note.とは
以下の2つはセキュリティ上,実際には重要です(本書では消してしまいますが).
.section .note.GNU-stack,"",@progbitsはスタック上の機械語命令を実行不可と指定しています..section .note.gnu.property,"a"はIntel CETというセキュリティ技術の一部である IBT (indirect branch tracking)と SHSTK (shadow stack) のための指示です.
endbr64とは
endbr64もセキュリティ上,重要です.
間接ジャンプは脆弱性の大きな原因です.
endbr64はセキュリティ技術であるIntel CET技術の命令であり,
間接ジャンプ先の命令がendbr64以外の時は実行エラーとする,というものです.
本書の学習者としては「endbr64はセキュリティ上,重要だけど,アセンブリ言語を学習する立場では「endbr64はnop命令(何も実行しない命令)」と思えば十分です.
add5.sの各行の意味の説明の前に,説明の都合上,
アセンブルとアセンブラを説明します.
アセンブリコードをオブジェクトファイルにアセンブルする
add5.sに対して,以下のコマンドを実行すると,
add5.oが生成されます.この処理をアセンブル(assemble)といいます.
そして,アセンブルを行うプログラム(コマンド)を
アセンブラ(assembler)と呼びます.
gcc -cは内部的にアセンブラasを呼び出します.
asは本書で使用するGNUアセンブラのコマンド名です.
$ gcc -c add5.s
$ ls
add5.c add5.o add5.s

アセンブル処理は逆アセンブルとちょうど逆の関係です. (逆アセンブルは,バイナリから機械語命令のニモニックを復元しますが, アセンブラ命令やラベルやコメントは復元できません. ですので,完全な逆の関係ではありません.)

add5.oはバイナリファイルです.
また,add5.oから作成する実行可能ファイルa.outもバイナリファイルです.
バイナリ(の中身)については次の章,3節.バイナリで説明します.
アセンブリ言語の構成要素
add5.sはアセンブリ言語のプログラムであり,
アセンブリコード (assembly code)と呼びます.
アセンブリコードは以下の4つを組み合わせて書きます.
- 機械語命令 (例:
pushq %rbp) - アセンブラ命令 (例:
.text) - ラベル定義 (例:
add5:) - コメント (例:
# add5.s)
特に機械語命令(machine instruction)とアセンブラ命令(assembler directive) の違いに注意して下さい.
-
機械語命令はCPUが実行する命令です. 例えば,
pushq %rbpは機械語命令(のニモニック)です. このpushq %rbpはa.outが実行された時にCPUが実行します.一方,アセンブラがすることは例えば
add5.s中のpushq %rbpという機械語命令のニモニックを0x55という2進数(ここでは16進数表記)に変換して,add5.oに出力するだけです. アセンブラはpushq %rbpという機械語命令を実行しません. アセンブラにとって,pushq %rbpも0x55も両方とも単なるデータに過ぎないのです. -
アセンブラ命令はアセンブラが実行する命令です. 例えば,
.textはアセンブラ命令です. 本書が使用するGNUアセンブラではドット記号.で始まる命令は全てアセンブラ命令です.アセンブラは
add5.sからadd5.oを出力(アセンブル)します. そのアセンブラに対して行う指示がアセンブラ命令です. 例えば,.textは「出力先を.textセクションにせよ」を アセンブラに指示しています. アセンブラはアセンブル時に.textというアセンブラ命令を実行します (CPUがa.outを実行するときではありません).
アセンブリ言語は1行に1つが基本
アセンブリ言語は基本的に1行に1つだけ, 「機械語命令」「アセンブラ命令」「ラベル定義」「コメント」 のいずれかを書くのが基本です. ただし,複数を組み合わせて1行にできる場合もあります. 以下に可能な例を示します. (正確な定義はGNUアセンブラの文法を参照下さい).
- OK
add5: pushq %rbp(ラベル定義と機械語命令) - OK
pushq %rbp; movq %rsp, %rbp(機械語命令と機械語命令,セミコロン;で区切る) - OK
pushq %rbp # コメント(機械語命令とコメント) - OK
.text # コメント(アセンブラ命令とコメント)
add5.s中の# add5.s
# add5.sはgcc -Sの出力ではなく,私が付け加えた行です.
この行はコメントです.#から行末までがコメントとなり,
アセンブラは単にコメントを無視します.
つまりコメントは(C言語のコメントと同じで)人間が読むためだけのものです.
add5.s中の.text
.textは「出力先を.textセクションにせよ」と
アセンブラに指示しています.
セクションでも説明しますが,
add5.oやa.outなどのバイナリファイルの中身はセクションという単位で
区切られています.
このため,アセンブラが機械語やデータを2進数に変換して出力する時,
「どのセクションに出力するのか」の指定が必要となるのです.
.textセクション以外には,代表的なセクションとして,
.dataセクション,.rodataセクションがあります.
それぞれの役割は以下の通りです.
.text機械語命令(例:pushq %rbp)を置くセクション.data初期化済みの静的変数の値(例:0x1234)を置くセクション.rodata読み込みのみ(read only)の値(例:"hello\n\0")を置くセクション
例えば,以下のアセンブリコードfoo.sがあるとします
(.rodataセクションを指定する際は,.sectionが必要です).
# foo.s
.text # .textセクションに出力せよ
pushq %rbp
movq %rsp, %rbp
.data # .dataセクションに出力せよ
.long 0x11223344
.section .rodata # .rodataセクションに出力せよ
.string "hello\n"
このfoo.sをアセンブラが処理すると以下になります(以下の図を見ながら読んで下さい).
-
pushq %rbpを2進数にすると0x55,movq %rsp, %rbpを2進数にすると0x48 0x89 0xe5なので, これら合計4バイトを.textセクションに出力します. -
.dataは「.dataセクションに出力せよ」.longは「指定したデータを4バイトの2進数として出力せよ」という意味です.0x11223344を2進数にすると0x44 0x33 0x22 0x11なので これら4バイトを.dataセクションに出力します. (出力が逆順になっているように見えるのは x86-64がリトルエンディアンだからです.) -
.section .rodataは「.rodataセクションに出力せよ」.stringは「指定した文字列をASCIIコードの2進数として出力せよ」という意味です."hello\n"を2進数にすると0x68 0x65 0x6c 0x6c 0x64 0x0a 0x00なので, これら7バイトを.rodataセクションに出力します. (最後の'\0'はヌル文字です.C言語では文字列定数の最後に自動的に ヌル文字が追加されますが,アセンブリ言語では必ずしもそうではありません..stringはヌル文字を追加します. 一方,(ここでは使っていませんが).asciiはヌル文字を追加しません). ASCIIコードはman asciiで確認できます.

.bssセクションは?
.text,.data,rodataに加えて,.bssセクションも代表的なセクションですが,
ここでは説明を省略しました.
.bssセクションは未初期化の静的変数の実体を格納するセクションなのですが,
ちょっと特殊だからです.
未初期化の静的変数はゼロで初期化されることになっているので,
バイナリファイル中では(サイズの情報等をのぞいて)実体は存在しません.
プログラム実行時に初めてメモリ上で.bssセクションの実体が確保され,
その領域はゼロで初期化されます.
add5.s中のadd5:,.globl add5,.type add5, @function,.size add5, .-add5
add5:はラベルの定義
add5:はadd5というラベルを定義しています.
ラベルはアドレスを表しています.
もっと具体的には「ラベルは,そのラベル直後の機械語命令や値が,
メモリ上に配置された時のアドレス」になります.
例えば,次のアセンブリコードがあり,
add5:
pushq %rbp
このpushq %rbp命令の2進数表現0x55が0x1234番地に置かれたとします.

この時,ラベルadd5の値は0x1234になります.
(ここでは話を単純化しています.ラベルの値が最終的に決まるまで,
再配置(relocation)などの処理が入ります)
ラベルの参照
で,大事なラベルの使い方(参照)です.
機械語命令のニモニック中で,アドレスを書ける場所にはラベルも書けるのです.
例えば,関数をコールする命令call命令でadd5関数を呼び出す時,
以下の2行はどちらも同じ意味になります.
ラベルadd5の値は0x1234になるからです.
(ここでも話を単純化しています.関数や変数のアドレスは
絶対アドレスではなく,相対アドレスなどが使われることがあるからです).
call 0x1234
call add5
どちらの書き方でも,アセンブラのアセンブル結果は同じになります. (もちろん通常はラベルを使います.具体的なアドレスを使って アセンブリコードを書くのは人間にとってはつらいからです).
記号表がラベルを管理する
アセンブラはラベルのアドレスが何番地になるかを管理するために, アセンブル時に記号表(symbol table)を作ります. 記号表中の情報は割と単純で,主に以下の6つです.
| アドレス | 配置される セクション | グローバル か否か | 型 | サイズ | ラベル名 (シンボル名) |
|---|---|---|---|---|---|
0x1234 | .text | グローバル | 関数 | 15 | add5 |
ここで,add5.sのラベルadd5が
- 配置されるセクションが
.textなのは,ラベルの定義add5:の前に.textが指定されているから - グローバルなのは,
.globl add5と指定されているから - 関数という型なのは,
.type add5, @functionと指定されているから - サイズが15バイトなのは,
.size add5, .-add5と指定されているから (サイズ15バイトは.-add5から自動計算されます)
です. ここでグローバルの意味は,C言語のグローバル関数やグローバル変数と(ほぼ)同じです. グローバルなシンボルは他のファイルからも参照できます.
ラベル or シンボル?
アセンブラが扱うシンボルのうち,アドレスを表すシンボルのことをラベルと呼んでいます.
シンボルはアドレス以外の値も保持できます.
つまりシンボルの一部がラベルであり,add5は関数add5の先頭アドレスを表すシンボルなのでラベルです.
.-add5 とは
.-add5はアドレスの引き算をしています..は特別なラベルで「この行のアドレス」を意味します.add5はadd5:のアドレスを意味します.
ですので,.-add5は「最後のret命令の次のアドレスから,
最初のpushq %rbp命令のアドレスを引いた値」になります.
つまり引き算の結果は「関数add5中の機械語命令の合計サイズ(単位はバイト)」です.
nmコマンドを使うと記号表の中身を表示できます.
$ nm ./a.out |egrep add5
0000000000001234 T add5
大文字Tは「.text中のグローバルシンボル」であることを意味しています.
(小文字tだと「.text中のグローバルではないシンボル」という意味になります).
このnmの出力では「add5が関数」という情報とサイズが表示できていません.
readelfコマンドを使うと,❶関数であることとサイズが❷15バイトであることを表示できます.
$ readelf -s ./a.out | egrep add5
1: 0000000000001234 ❷15 ❶FUNC GLOBAL DEFAULT 1 add5
readelfコマンドとは
objdumpは汎用のコマンド(ELFバイナリ以外のバイナリにも使える)ため,
ELF特有の情報を表示できないことがあります.
ELF専用のコマンドであるreadelfを使えば,ELF特有の情報も表示できます.
例えば,以下ではreadelfを使って記号表(❶.symtab)のセクションがあることを確認できました.
$ readelf -S add5.o セクションヘッダを表示
There are 12 section headers, starting at offset 0x258:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .text PROGBITS 0000000000000000 00000040
0000000000000013 0000000000000000 AX 0 0 1
[ 2] .data PROGBITS 0000000000000000 00000053
0000000000000000 0000000000000000 WA 0 0 1
[ 3] .bss NOBITS 0000000000000000 00000053
0000000000000000 0000000000000000 WA 0 0 1
(中略)↓これが記号表 (symbol table)
[ 9]❶.symtab SYMTAB 0000000000000000 000000d8
00000000000000f0 0000000000000018 10 9 8
add5.s中のpushq %rbp,movq %rsp, %rbp,popq %rbp
movq %rsp, %rbp
%rspと%rbpはどちらもレジスタです.
(GNUアセンブラではレジスタの名前の先頭に必ず%が付きます).
レジスタはCPU内の高速なメモリです.CPUはメモリにアクセスするよりも,
はるかに高速にレジスタにアクセスできます.
%rspと%rbpはどちらも8バイト長のデータを格納できます.
movq %rsp, %rbpという機械語命令は
「%rspレジスタの値を%rbpにコピーする」という命令です.
movqのmovは「move (移動)」,qは「処理するサイズが8バイト」であることを意味しています.
(moveといいつつ,実行内容はコピーです.%rspに古い値が残るからです.)
なぜqが8バイト?
qはクアッドワード(quad word)の略だからです. 以下の通り,クワッドワードは「ワード2バイトの4個分」なので8バイトになります.
- ワード(word)はバイト(byte)と同様に情報量の単位ですが, ワードが何バイトかはCPUごとに異なります. x86-64ではワードは2バイトです. x86の元祖であるIntel 8086が16ビットCPUだったことに由来します.
- クアッド(quad)は4を意味します. 例えば,quadrupleは「4倍の」,quad bikeは「4輪バイク」を意味します.
仮にmovq %rsp, %rbpを実行する前に,
%rspの値が0x11223344,%rbpの値が0x55667788とします.
movq %rsp, %rbpを実行すると,
%rspの値が%rbpにコピーされるので,
%rspの値も%rbpの値も0x11223344になります.
要するに,movq命令はC言語の代入文と同じです.

pushq %rbpとpopq %rbp
pushq %rbpは「スタックに%rbpの値をプッシュする」機械語命令です.
以下の図のように,%rbp中の値をスタックの一番上にコピーします.
スタックはコピー先の部分を含めて上に成長します(赤枠の部分がスタック全体).

popq %rbpは「スタックからポップした値を%rbpに格納する」という機械語命令です.
以下の図のように,スタックの一番上の値を%rbpにコピーします.
スタックはコピー元の部分だけ下に縮みます(赤枠の部分がスタック全体).

これだけだと,pushq %rbpやpopq %rbpの役割がよく分かりませんね.
実はこの2つの命令は以下で説明するスタックフレームの処理に関係しています.
データ構造としてのスタック
スタック(stack)は超基本的なデータ構造であり, 以下の図の通り,プッシュ操作とポップ操作でデータの格納と取り出しを行います.
- プッシュはスタックの一番上にデータを格納します
- ポップはスタックの一番上からデータを取り出します

最後に格納したデータが,取り出す時は先に取り出されるので, 後入れ先出し方式(LIFO: last in first out)とも呼ばれます.
スタックは関数呼び出しの実装に便利なデータ構造です. 関数呼び出しからリターンするときは,呼び出された順番とは逆順にリターンするからです.
キューqueueは?
ちなみに超基本的なデータ構造としてキュー(queue)も重要です. こちらは先に格納したデータが,先に取り出されるので 先入れ先出し方式(FIFO: first in first out)になります.
スタックとスタックフレーム
スタックとはプロセス(実行中のプログラム)が使用するメモリの領域の1つです. ここでのスタックは関数呼び出しのためのスタックなので, コールスタック(call stack)と呼ぶのが正式名称なのですが, 慣習に習って本書でも単にスタックと呼びます.

関数を呼び出すと,スタックフレームというデータがスタックに追加(プッシュ)されて, スタックは上に成長します.その関数からリターンすると, そのスタックフレームはスタックから削除(ポップ)されて縮みます. スタックフレームは関数呼び出し1回分のデータで, 局所変数,引数,返り値,戻り番地(リターンアドレス),退避したレジスタの値などを含みます.
例えば,main関数がadd5関数を呼び出して,add5からリターンすると以下の図になります.

%rspと%rbpは一番上のスタックフレームの上下を指す
さて,ここでようやく%rspレジスタと%rbpレジスタの出番です.
実は%rspと%rbpは以下の図のように,
スタック上の一番上のスタックフレームの上下を指す役割を担っています.

「レジスタがスタックを指す」というのは具体的に以下の図の状態です.
つまり,
スタックフレームの一番上のアドレス(例えば0x11223344)が
%rspに入っていて,%rspの値をそのアドレスとして使う意図がある場合,
「%rspはスタックフレームの一番上を指す」と言い,
上の図のように矢印で図表現します.
(%rbpも同様です)

%rspは常にスタックの一番上を指す
pushq命令で
プッシュすると%rspはプッシュしたデータの一番上を指すようにずれるので,
%rspは常にスタックの一番上(スタックトップ)を指します.
また,%rbpをプッシュしたので下図のように
プッシュした値もスタックフレームの一番下を指しています.

同様にpopq命令でポップした時はポップで取り出したデータ分だけ
%rspが指す先は下にずれて,やはり%rspはスタックトップを指します.
下図では保存した%rbpの値をポップして%rbpに格納したので,
この時だけ「ひとつ下のスタックフレームの一番下」を%rbpは指しています
(が,通常,この直後にリターンして一番上のスタックフレームは破棄されます.
ですので,すぐに「%rspと%rbpは常に一番上のスタックフレームの上下を指す」
という状態に戻ります.)

pushq %rbp と movq %rsp, %rbp は新しいスタックフレームを作る
関数を呼び出すと,その関数のための新しくスタックフレームを作る必要があります. 誰が作るのかというと「呼び出された関数自身」が作ります(これはABIが定める事項です).
ここでは関数mainが関数add5をcall命令で呼び出すとして説明します.
main:
...
call add5
add5:
pushq %rbp
movq %rsp, %rbp
これらの命令を実行した時のスタックの様子は以下の図のとおりです.
(「call前」等のボタンを押して,図を切り替えて下さい)
一つずつ説明していきます.
call命令実行前はmain関数が一番上のスタックフレームです. その上下を%rspと%rbpが指しています.call命令を実行してadd5関数に実行を移す際に,call命令はスタック上に戻り番地(リターンアドレス)をプッシュします. 戻り番地とは「関数からリターンした時にどのアドレスに実行を戻せばよいか」 を表す番地です.この場合ではcall add5命令の次のアドレスが戻り番地になります.push %rbp命令を実行すると,今の%rbpレジスタの値をスタック上にプッシュします. 上の説明と見比べて下さい. 新しいスタックフレームを作る際に,%rbpに新しい値を設定する必要があるために, 今の%rbpの値をスタック上に退避(保存)するため,pushq %rbpが必要となります.- 次に
movq %rsp, %rbpを実行します. 実はadd5のスタックフレームはとても小さくて「古い%rbp」しか入っていません. ですので,%rspの値を%rbpにコピーすれば, 「add5のスタックフレームの上下を%rspと%rspが指している」という状態にできます. この動作も上で説明したので見比べて下さい.
以上で,add5のための新しいスタックフレームを作れました.
popq %rbpは今のスタックフレームを捨てる
これは前節での説明のちょうど逆になります.
popq %rbp
ret
を実行すると,スタックフレームは以下の図になります.
-
popq %rbpの実行前は,スタックトップ付近はこの図の状態になっています. (コンパイラがこの図の状態になるようにアセンブリコードを出力します. 自分でアセンブリコードを書く場合は,この図の状態になるように正しくプログラムする必要があります) 「この図の状態」をもう少し説明すると以下になります.- スタックトップには 古い
%rbpが格納されていて, その 古い%rbpは1つ前のスタックフレームの一番下を指している. - スタックトップのひとつ下には戻り番地が格納されている.
- さらにその下には
add5を呼び出した関数(ここではmain)のスタックフレームがある.
- スタックトップには 古い
-
popq %rbpを実行すると,%rbpはmain関数のスタックフレームの一番下を 指すようになります.(上の説明と合わせて読んで下さい.) また,ポップの結果,%rspが指す先が下にずれて,戻り番地を指すように変わりました. -
ret命令はスタックトップから戻り番地をポップして,次に実行する命令のアドレスをポップした戻り番地に設定します.スタックの状態はadd5を呼び出す前の状態に戻りました.
「この図の状態」の例外
全てのスタックフレームは「古い`%rbp`」で数珠つなぎ
実は下の図のように全てのスタックフレームは「古い%rbp」で数珠つなぎ,
つまり線形リスト(linked list)になっています

戻り番地とプログラムカウンタ
一般的にCPUはプログラムカウンタと呼ばれる特別な役割を持つレジスタを備えています.
プログラムカウンタは「次に実行する機械語命令のアドレス」を保持します.
そして,ret命令などでプログラムカウンタ中のアドレスを変更すると,
「次に実行する機械語命令のアドレス」を変更できるのです.
x86-64では%ripレジスタがプログラムカウンタです.
ret命令はスタックをポップして取り出した戻り番地を
プログラムカウンタ%ripに格納することで,「関数からリターンする」
(つまり,call add5命令の直後の命令を次に実行する)という動作を実現しています.
add5.s中の movl %edi, -4(%rbp), movl -4(%rbp), %eax, addl $5, %eax
ここでは以下の3命令を説明します.
直感的にはこの3命令で「n + 5」を計算しています.
movl %edi, -4(%rbp)
movl -4(%rbp), %eax
addl $5, %eax
-
まず
-4(%rbp)を説明します. これは「%rbp中のアドレスから4を引いた数」をアドレスとしてメモリを 読み書きすることを意味しています.以下の図はスタックをより正確に描いています.- メモリは1バイトごとにアドレスが付いています.
古い
%rbpや戻り番地のデータはそれぞれ8バイトなので, アドレス8つ分(つまり8バイト)の場所を占めています. - 多バイト長のデータはそのデータが占めている先頭のアドレスを使って
メモリを読み書きします.(本書の図ではメモリの0番地が常に上にあることを思い出してください).
ですので,1バイトごとのアドレスで考えると,
%rbpはスタックフレームの 一番下を指していません. - そして,
-4(%rbp)は「%rbpから4を引いたアドレスのメモリ」ですので, 以下の図で-4(%rbp)が指している場所を先頭とするメモリ領域になります.
- メモリは1バイトごとにアドレスが付いています.
古い

-
次に
%ediと%eaxについて説明します.- 以下の図のようにx86-64には8バイト長の
%rdiと%raxという 汎用レジスタがあります(他にも汎用レジスタはありますがここでは割愛). その右半分にそれぞれ%ediと%eaxという名前が付いています.%ediと%eaxは4バイト長です. %rdiレジスタは関数呼び出しでは第1引数を渡すために使われます.add5の第1引数nはint型で,この場合は4バイト長だったため,%ediにnの値が入っています.%raxレジスタは関数呼び出しでは返り値を返すために使われます.add5の返り値の方がint型なので,%eaxに値を入れてから 関数をリターンすれば,返り値が返せることになります.
- 以下の図のようにx86-64には8バイト長の

- 次に以下の2つの命令を説明します.
movl %edi, -4(%rbp)
movl -4(%rbp), %eax
movlのlは4バイトのデータをコピーすることを表しています.ですので, 例えば,movl %edi, -4(%rbp)は%edi中の4バイトデータを 先頭アドレスが-4(%rbp)から4バイト分の領域 (この図で一番上の赤い部分) にコピーする命令になります.
なぜl(エル)が4バイト
l(エル)はlongの略で,GNUアセンブラでは以下の通り,longが4バイトを意味するからです. Intelマニュアルなどでは4バイトのことをdouble wordと呼びます.
| 2バイト | 4バイト | 8バイト | |
|---|---|---|---|
| GNUアセンブラ | short | long | quad |
| Intelマニュアル | word | double word | quad word |
-
この2つの命令で「
%edi中の4バイトを-4(%rbp)にコピー」して,次に 「-4(%rbp)中の4バイトを%eaxにコピー」しています. 「%ediから%eaxに直接コピーすればいいんじゃね?」と思った方,正解です. 実はこの場合は(-4(%rbp)に格納しても使われないので)不要なのですが, コンパイラは 「引数nの実体の場所を-4(%rbp)としたので,-4(%rbp)にもnの値を格納する」という判断をしたようです. -
addl $5, %eax命令を説明します.- この命令は
%eaxの値と定数5の値を足し算した結果を%eaxに格納します. - つまり,
n + 5の結果がこの命令の実行後に%eaxに入ります. - GNUアセンブラでは定数の先頭にはドルマーク
$が付きます. ただし,-4(%rbp)の-4など,ドルマークが付かないこともあります.
- この命令は
以上でadd5.sの説明が終わりました(お疲れ様でした).
即値とは
上で$5は定数と説明しましたが,アセンブラ用語では
即値(immediate value)と呼びます.
それは機械語命令の2進数の中に
即値の値が埋め込まれており,即座に(つまりメモリやレジスタにアクセスすることなく)
値を取り出せることに由来しています.
x86-64のマニュアルなどで imm32 などが出てきます.imm32は「32ビット長の即値」を意味しています.
%rspより上のメモリ領域に勝手に書き込んで良いのか(レッドゾーン)
LinuxのABI System V ABIではOKです.
LinuxのABIでは%rspレジスタの上,128バイトの領域をレッドゾーンと呼び,
この領域には好きに読み書きして良いことになっています.
(ABIが「割り込みハンドラやシグナルハンドラが実行されても,
レッドゾーンの値は破壊されない」ことを保証しています.)
もちろん,自分自身で関数を呼び出すとレッドゾーン中の値は壊れるので,
レッドゾーンは葉関数(leaf function),つまり関数を呼び出さない関数
が使うのが一般的です.
レッドゾーンのおかげで,%rspをずらさずにメモリの読み書きができるので,
その分だけ実行が高速になります.

バイナリファイル
バイナリファイルの中身を見る
16進ダンプ
add5.cやadd5.sはテキストファイルですが,
2節のアセンブリ言語で作成した
add5.oはバイナリファイルです.
バイナリファイルなので,lessコマンドでは中身を読めません.
$ less add5.o
^?❶ELF^B^A^A^@^@^@^@^@^@^@^@^@^A^@>^@^A^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@X^B
^@^@^@^@^@^@^@^@^@^@@^@^@^@^@^@@^@^L^@^K^@<F3>^O^^<FA>UH<89><E5><89>}<FC><8B>E
(長いので省略)
❶ELFとは
上のlessコマンドの結果にELFという文字が見える理由を説明します.
ELFはLinuxが採用しているバイナリ形式(binary format)です.
このELFのバイナリファイルの先頭4バイトにはマジックナンバーという
バイナリファイルを識別する特別な数値が入っています.
ELFバイナリのマジックナンバーは 7F 45 4C 46です.
45 4C 46はASCII文字で E L F なので,lessコマンドがELFと表示したわけです.
バイナリファイルの中身を読むには例えばodコマンドを使います.
$ od -t x1 add5.o
0000000 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
0000020 01 00 3e 00 01 00 00 00 00 00 00 00 00 00 00 00
(長いので省略)
一番左の数字が「先頭からのバイト数(16進表記)」,
その右側に並んでいるのが「1バイトごとに16進表記したファイルの中身」です.
(1バイトのデータは2桁の16進数で表せることを思い出しましょう.
例えば,add5.oの中身の先頭4バイトの値は7F 45 4C 46です).
-t x1というオプションは「1バイトごとに16進数で表示せよ」という意味です.
このような出力を16進ダンプ(hex dump)と言います.
他に16進ダンプするコマンドとして,xxdやhexdumpなどがあります.
ちなみに,add5.cはテキストファイルですが,内容は2進数で保存されて
いますので,odコマンドで中身を表示できます.
$ od -t x1 add5.c
0000000 69 6e 74 20 61 64 64 35 20 28 69 6e 74 20 6e 29
0000020 0a 7b 0a 20 20 20 20 72 65 74 75 72 6e 20 6e 20
0000040 2b 20 35 3b 0a 7d 0a
0000047
先頭の69はASCII文字iの文字コード,
同様に,次の6eは文字n,その次の74は文字tなので,
add5.cの先頭3文字がintであることを確認できます.
ASCIIコード表はman asciiコマンドで閲覧できます.
(例えば,16進数の0x69は10進数の105です.
ASCIIコード表の105番目の文字はiです.)
manコマンドとは
manコマンドはLinux上でマニュアルを表示するコマンドです.
例えばman asciiを実行すると以下のように表示されます.
$ man ascii
ASCII(7) Linux Programmer's Manual ASCII(7)
NAME
ascii - ASCII character set encoded in octal, decimal, and hexadecimal
DESCRIPTION
ASCII is the American Standard Code for Information Interchange. It is
a 7-bit code. Many 8-bit codes (e.g., ISO 8859-1) contain ASCII as
their lower half. The international counterpart of ASCII is known as
ISO 646-IRV.
The following table contains the 128 ASCII characters.
C program '\X' escapes are noted.
Oct Dec Hex Char Oct Dec Hex Char
────────────────────────────────────────────────────────────────────────
000 0 00 NUL '\0' (null character) 100 64 40 @
001 1 01 SOH (start of heading) 101 65 41 A
002 2 02 STX (start of text) 102 66 42 B
(以下略)
デフォルトではlessコマンドで1ページずつ表示されるので,
スペースキーで次のページが,bを押せば前のページが表示されます.
終了するにはqを押します.hを押せばヘルプを表示し,/で検索もできます.
例えば,/backspaceと入力してリターンを押すと,backspaceを検索してくれます.
manコマンドは章ごとに分かれています.例えば
- 1章はコマンド (例:
ls) - 2章はシステムコール (例:
open) - 3章はライブラリ関数 (例:
printf)
となっています.
printfというコマンドがあるので,
man printfとすると(ライブラリ関数ではなく)コマンドのprintfの
マニュアルが表示されてしまいます.
ライブラリ関数のprintfを見たい場合は
man 3 printfと章番号も指定します.
なお,odコマンドに-cオプションをつけると,
(文字として表示可能なバイトは)文字が表示されます.
$ od -t x1 -c add5.c
0000000 69 6e 74 20 61 64 64 35 20 28 69 6e 74 20 6e 29
i n t a d d 5 ( i n t n )
0000020 0a 7b 0a 20 20 20 20 72 65 74 75 72 6e 20 6e 20
\n { \n r e t u r n n
0000040 2b 20 35 3b 0a 7d 0a
+ 5 ; \n } \n
0000047
コンピュータの中のデータはすべて0と1から成る
ここで大事なことを復習しましょう.
それは
「コンピュータの中のデータは,どんな種類のデータであっても,
機械語命令であっても,すべて0と1だけで表現されている」
ということです.
ですので,テキストはバイナリでもあるのです.
- テキスト=文字として表示可能な2進数だけを含むデータ
- バイナリ=文字以外の2進数も含んだデータ

注意: 本書で,テキスト(text)という言葉には2種類の意味があることに注意して下さい.
- 1つは「文字」を意味します.例:「テキストファイル」(文字が入ったファイル)
- もう1つは「機械語命令列」を意味します.例:「テキストセクション」(機械語命令列が格納されるセクション)
2進数と符号化
前節で説明した通り, コンピュータ中では全てのものを0と1の2進数で表現する必要があります. そのため,データの種類ごとに2進数での表現方法,つまり符号化 (encoding)の方法が定められています. 例えば,
- 文字
UをASCII文字として符号化すると,01010101になります. pushq %rbpをx86-64の機械語命令として符号化すると,01010101になります.
おや,どちらも同じ01010101になってしまいました.
この2進数がUなのかpushq %rbpなのか,どうやって区別すればいいでしょう?
答えは「これだけでは区別できません」です.

別の手段(情報)を使って,いま自分が注目しているデータが,
文字なのか機械語命令なのかを知る必要があります.
例えば,この後で説明する.textセクションにある
2進数のデータ列は「.textセクションに存在するから」という理由で
機械語命令として解釈されます.
fileコマンド
16進ダンプ以外の方法で,add5.oの中身を見てみます.
まずはfileコマンドです.
fileコマンドはファイルの種類の情報を教えてくれます.
$ file add5.o
add5.o: ❶ELF 64-bit ❷LSB ❸relocatable, x86-64, ❹version 1 (SYSV), ❺not stripped
これで,add5.oが64ビットの❶ELFバイナリであることが分かりました.
ELFはバイナリ形式(バイナリを格納するためのファイルフォーマット)の1つです.
Linuxを含めて多くのOSがELFをバイナリ形式として使っています.
❷LSBとは
多バイト長のデータをバイト単位で格納する順序をバイトオーダ(byte order)といいます. LSBは最下位バイトから順に格納するバイトオーダ (Least Significant Byte first), つまりリトルエンディアン を意味しています.
x86-64のバイトオーダがリトルエンディアンのため,
このELFバイナリもリトルエンディアンになっています.
ELFバイナリがビッグエンディアンかリトルエンディアンかどうかを示すデータが,
ELFバイナリのヘッダに格納されています.
これはreadelf -hコマンドで調べられます❶.
$ readelf -h a.out
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, ❶little endian
Version: 1 (current)
OS/ABI: UNIX - System V
(以下略)
リトルエンディアンでの注意は16進ダンプする時に,多バイト長データが逆順に表示されることです.
以下で多バイト長データ❶0x11223344を.textセクションに配置してアセンブルした
little.oを逆アセンブルすると,❸44 33 22 11と逆順に表示されています.
(objdump -hの出力から,.textセクションのオフセット(ファイルの先頭からのバイト数)が❷0x40バイトであることを使って,odコマンドに-j0x40オプションを使い,.textセクションの先頭付近の情報を表示しています)
$ cat little.s
.text
❶.long 0x11223344
$ gcc -c little.s
$ objdump -h little.o
foo.o: file format elf64-x86-64
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000004 0000000000000000 0000000000000000 ❷00000040 2**0
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .data 00000000 0000000000000000 0000000000000000 00000044 2**0
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000000 0000000000000000 0000000000000000 00000044 2**0
ALLOC
$ od -t x1 -j0x40 little.o | head -n1
0000100 ❸44 33 22 11 00 00 00 00 00 00 00 00 00 00 00 00
❸relocatableとは
バイナリ中のアドレスを再配置 (relocate)できるバイナリのことを 再配置可能 (relocatable)であるといいます.オブジェクトファイルはリンク時や実行時にアドレスを変更できるよう, relocatableであることが多いです.
❹version 1 (SYSV)とは
LinuxのABI(バイナリ互換規約)であるSystem V ABI に準拠していることを表しています.
❺not strippedとは
バイナリには実行に直接関係ない記号表やデバッグ情報などが
含まれていることがよくあります.
この「実行に直接関係ない情報」が削除されたバイナリのことを
stripped binaryと呼びます.
stripコマンドで「実行に直接関係ない情報」を削除できます.
削除された分,サイズが少し減っています.
$ ls -l add5.o
-rw-rw-r-- 1 gondow gondow 1368 Jul 19 10:09 add5.o
$ strip add5.o
$ ls -l add5.o
-rw-rw-r-- 1 gondow gondow 880 Jul 19 14:58 add5.o
.textセクションだけ抜き出す
GNU binutilsのobjcopyコマンドを使うと,特定のセクションだけ抜き出せます.
以下ではlittle.oから.textセクションを抜き出して,ファイルfooに書き込んでいます.
$ objcopy --dump-section .text=foo little.o
$ od -t x1 foo
0000000 44 33 22 11
0000004
objcopyはセクションの注入も可能です.
以下ではファイルfooの内容をlittle.oの新しいセクション.text2として注入しています.
新しいセクション❶.text2が出来ていることが分かります.
$ objcopy --add-section .text2=foo --set-section-flags .hoge=noload,readonly little.o
$ objdump -h little.o
little.o: file format elf64-x86-64
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000004 0000000000000000 0000000000000000 00000040 2**0
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .data 00000000 0000000000000000 0000000000000000 00000044 2**0
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000000 0000000000000000 0000000000000000 00000044 2**0
ALLOC
3 ❶.text2 00000004 0000000000000000 0000000000000000 00000044 2**0
CONTENTS, READONLY
なお,fileコマンドはバイナリ以外のファイルにも使えます.
$ file add5.c
add5.c: ASCII text
$ file add5.s
add5.s: assembler source, ASCII text
$ file .
.: directory
$ file /dev/null
/dev/null: character special (1/3)
セクションとobjdump -hコマンド
バイナリファイルの構造はざっくり以下の図のようになっています.

- 最初のヘッダ以外の四角をセクション(section)と呼びます.
- バイナリはセクションという単位で区切られていて,それぞれ別の目的でデータが格納されます.
- ヘッダは目次の役割で「どこにどんなセクションがあるか」という情報を保持しています.
ヘッダの情報はobjdump -hで表示できます.
$ objdump -h add5.o
add5.o: file format elf64-x86-64
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000013 0000000000000000 0000000000000000 00000040 2**0
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .data 00000000 0000000000000000 0000000000000000 00000053 2**0
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000000 0000000000000000 0000000000000000 00000053 2**0
ALLOC
(以下略)
ここでは「.text,.data,.bssという3つのセクションがある」ことを
見ればOKです.
VMAとLMAとは
VMAはvirtual memory addressの略で「メモリ上で実行される時の
このセクションのメモリアドレス」です.
一方,LMAはload memory addressの略で「メモリ上にロード(コピー,配置)する時の
このセクションのメモリアドレス」です.
通常,セクションをメモリにロードした後で,移動せずにそのまま実行するため,VMAとLMAは同じアドレスになります.
add5.oではアドレスが決まってないので,VMAもLMAもゼロになっています.
File offとは
File offはファイルオフセットを表しています.このセクションがバイナリファイルの先頭から何バイト目から始まっているかを16進表記で表しています.
Algnとは
Algnはアラインメント(alignment)を表しています.
例えば「このセクションをメモリ上に配置する時,その先頭アドレスが8の倍数になるようにしてほしい」という状況の時,この部分が2**3となります(2の3乗=8).
CONTENTS, ALLOC, LOAD, READONLY, CODEとは
これらはセクションフラグと呼ばれるセクションの属性値です.
- CONTENTS このセクションには中身がある (例えば,
.bssはCONTENTSが無いので(ファイル中では)中身が空のセクションです) - ALLOC ロード時にこのセクションのためにメモリを割り当てる必要がある
- LOAD このセクションは実行するためにメモリ上にロードする必要がある
- READONLY メモリ上では「読み込みのみ許可(書き込み禁止)」と設定する必要がある
- CODE このセクションは実行可能な機械語命令を含んでいる
3つのセクション .text ,.data,.bss の役割は以下の通りです:
.textセクションは機械語命令を格納します.例えば,pushq %rbpを表す0x55は.textセクションに格納されます..dataセクションは初期化済みの静的変数の値を格納します.例えば,大域変数int x=999;があったとき,999の2進数表現が.dataセクションに格納されます..bssセクションは未初期化の静的変数の値を格納します.例えば,大域変数int y;があったとき,(概念的には)初期値0の2進数表現が.bssセクションに格納されます.
なぜ概念的
実はファイル中では.bssセクションにはサイズ情報などごくわずかの情報しか持っていません.実行時にメモリ上に.bssセクションを作る際に,実際に必要なメモリを確保して,そのメモリ領域をすべてゼロで初期化すれば十分だからです(ファイル中に大量のゼロの並びを保持する必要はありません).
// bss.c
int a [1024];
int main (void)
{
return a[0];
}
例えば,bss.cのint a[1024]; の変数aは未初期化なので,
変数aの実体は.bssセクションに置かれます.アセンブリコードを見てみると,
$ gcc -S bss.c
$ cat bss.s
(関係する箇所以外は削除)
❶ .bss # 以下を.bssセクションに出力
.align 32 # 次の出力アドレスを32の倍数にせよ
.type a, @object # ラベルaの型はオブジェクト(関数ではなくデータ)
.size a, 4096 # ラベルaのサイズは4096バイト
a: # ラベルaの定義
❷ .zero 4096 # 4096バイト分のゼロを出力せよ
❶.bssセクションに❷4096バイト分のゼロを出力するように見えますが,
ヘッダを見てみると,ファイル中の.bssセクションの中身は0バイトだと分かります.
$ gcc -g bss.c
$ objdump -h ./a.out
Sections:
Idx Name Size VMA LMA File off Algn
(中略)
23 ❸.bss ❹ 00001020 0000000000004020 0000000000004020 ❺ 00003010 2**5
❼ALLOC
24 .comment 0000002b 0000000000000000 0000000000000000 ❻ 00003010 2**0
CONTENTS, READONLY
❸.bssセクションのサイズは16進数で❹ 0x1020バイト(10進数では4128バイト)ですが,
ファイルオフセットを比較してみると,❺と❻が同じ値(000033010)なので,
ファイル中での.bssセクションのサイズは0バイトだと分かります.
また,セクション属性が❼ALLOCのみで,
CONTENTS(中身がある)が無いことからも0バイトと分かります.
さらに代表的なセクションである.rodataも説明します.
.rodataセクションは読み込みのみ(read-only)なデータの値を格納します.例えば,C言語の文字列定数"hello"は書き込み禁止なので,"hello"の2進数表現が.rodataセクションに格納されます.
バイナリファイルには上記以外のセクションも数多く使われますが,
まずはこの基本の4種類 (.text, .data, .bss, .rodata) を覚えましょう.
記号表の中身を表示させる(nmコマンド)
バイナリファイル中には記号表(symbol table)があることが多いです.
記号表とは「変数名や関数名がバイナリ中では何番地のアドレスになっているか」という情報です.
nmコマンドでバイナリファイル中の記号表を表示できます.
まず,以下のfoo.cを準備して下さい.
// foo.c
int g1 = 999;
int g2;
static int s1 = 888;
static int s2;
int main ()
{
static int s3 = 777;
static int s4;
int ❼i1 = 666;
int ❼i2;
}
そしてコンパイルして,nmコマンドで記号表の中身を表示させます.
$ gcc -c foo.c
$ nm foo.o
0000000000000000 ❶D g1
0000000000000000 ❸B g2
0000000000000000 ❺T main
0000000000000004 ❷d s1
0000000000000004 ❹b s2
0000000000000008 ❷d ❻s3.0
0000000000000008 ❹b ❻s4.1
この出力の読み方は以下の通りです.
- ❶
Dと❷dは.dataセクションのシンボル,❸Bと❹bは.bssセクションのシンボル,❺Tとtは.textセクションのシンボルであることを表す - 大文字はグローバル(ファイルをまたがって有効なシンボル),小文字はファイルローカルなシンボルであることを表す
static付きの局所変数を表すシンボルは 他の関数中の同名のシンボルと区別するために, ❻.0や.1などが付加されることがある.- 左側の
00,04,08がシンボルに対応するアドレスですが,再配置前(relocation前)なので仮のアドレス(各セクションの先頭からのオフセット) - (
staticのついてない)局所変数❼は記号表には含まれていない. 局所変数(自動変数)は実行時にスタック上に実体が確保されます.
ASLRとPIE(ちょっと脱線)
オブジェクトファイルのセクションごとの仮のアドレスは,
リンク後のa.outでは具体的なアドレスになります
$ gcc foo.c
$ nm ./a.out | egrep g1
0000000000004010 D g1
$ nm ./a.out | egrep main
U __libc_start_main@@GLIBC_2.34
0000000000001129 T main
U __libc_start_main@@GLIBC_2.34とは
バイナリ中で参照されているけど定義がないシンボルがあると,
nmコマンドはundefinedを意味するUを表示します.
実はa.outはmain関数を呼び出す前に__libc_start_mainという
GLIBC中の関数を(動的リンクした上で)呼び出します.
__libc_start_mainは
様々な初期化を行った後,(その名の通り)main関数を呼び出すのが主な役割です.
ちなみに__libc_start_mainは_startが呼び出します.
$ readelf -h ./a.out | egrep Entry
Entry point address: ❶ 0x1040
$ objdump -d ./a.out | egrep 1040
0000000000001040 ❷ <_start>:
1040: f3 0f 1e fa endbr64
a.outのエントリポイント(最初に実行するアドレス)は
❶ 0x1040番地です.この番地には❷_startがあるので,
a.outを実行すると最初に実行される関数は_startと分かります.
出力が長くなるので,g1とmainのアドレスだけ載せています.
g1のアドレスは0x4010番地,mainのアドレスは0x1129番地となりました.
ただし,このまま実行すると,g1やmainのアドレスはこれらのアドレスにはならず,
実行するたびに変わります.
これはASLRやPIEというセキュリティ対策機能のためです.
確かめてみましょう.
以下のfoo2.cを普通にコンパイルして実行してみます.
// foo2.c
#include <stdio.h>
int g1 = 999;
int main ()
{
printf ("%p, %p\n", &g1, main);
}
以下の通り,g1やmainのアドレスは実行するたびに変わりますし,
nmが出力したアドレスとも異なります.
$ gcc foo2.c
$ ./a.out
0x557f2361e010, 0x557f2361b149
$ ./a.out
0x55a40e6f5010, 0x55a40e6f2149
$ ./a.out
0x562750663010, 0x562750660149
$
ここではASLRとPIEの機能を無効にして,アドレスが変わらなくなることを確認します.
$ sudo sysctl -w kernel.randomize_va_space=0 # ASLRをオフ
$ gcc -no-pie foo2.c # PIEをオフ
$ nm ./a.out | egrep main
U __libc_start_main@@GLIBC_2.34
0000000000401136 T main
$ nm ./a.out | egrep g1
0000000000404030 D g1
$ ./a.out
&g1=0x404030, main=0x401136
$ ./a.out
&g1=0x404030, main=0x401136
$ ./a.out
&g1=0x404030, main=0x401136
ASLRとPIEの機能をオフにすることで,アドレスが変わらなくなり,
かつnmが出力するアドレスと同じになることが確認できました.
注意: 不用意なASLRとPIEの無効化はセキュリティ機能を下げるので避けるべきです. しかしデバッグ作業ではアドレスが変わらなくなるので ASLRとPIEの無効化が有用な場合もあります. なお,デバッガ中ではASLRは無効化されていることが多いです.
ASLRとは
ASLR (address space layout randomizationの略)は, アドレス空間の配置をランダム化する機能です. テキスト(実行コード),ライブラリ,スタック,ヒープなどをメモリ上に 配置するアドレスを実行するたびにランダムに変化させます. 以下を実行するとASLRは無効化され,
$ sudo sysctl -w kernel.randomize_va_space=0
以下を実行するとASLRは有効化されます.
$ sudo sysctl -w kernel.randomize_va_space=1
PIEとは
PIE (position independent executableの略)は位置独立実行可能ファイルを意味します.
通常,動的ライブラリは位置独立コードPIC (position independent code)としてコンパイルされます.
動的ライブラリはメモリ上で共有されるため,どのアドレスに配置してもそのまま再配置せずに,実行したいからです.
PIEは動的ライブラリだけでなく,a.outも位置独立にした実行可能ファイルを指します.
-no-pieオプションでコンパイルすると,PIEを無効化できます.
$ gcc -no-pie foo2.c
逆アセンブル再び
逆アセンブルで説明した通り,
objdump -d ./a.outで逆アセンブル結果が表示されます(再掲).
$ objdump -d add5.o
add5.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <add5>:
0: f3 0f 1e fa endbr64
4: 55 push %rbp
5: 48 89 e5 mov %rsp,%rbp
8: 89 7d fc mov %edi,-0x4(%rbp)
b: 8b 45 fc mov -0x4(%rbp),%eax
e: 83 c0 05 add $0x5,%eax
11: 5d pop %rbp
12: c3 retq
objdumpコマンドはadd5.oの.textセクションを抽出し,
そのデータを機械語命令として解釈して,対応するニモニックを出力しています.
この出力によれば,.textセクションの先頭4バイトはF3 0F 1E FAで,
この4バイトがendbr64命令になります
(x86-64の命令長は可変長で,1バイト〜15バイトです).
以下では.textセクションの先頭4バイトがF3 0F 1E FAであることを確認します.
セクションのヘッダを出力するコマンドobjdump -hの出力を再掲します.
$ objdump -h add5.o
add5.o: file format elf64-x86-64
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000013 0000000000000000 0000000000000000 ❶00000040 2**0
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .data 00000000 0000000000000000 0000000000000000 00000053 2**0
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000000 0000000000000000 0000000000000000 00000053 2**0
ALLOC
.textセクションのFile offの欄を見ると❶00000040とあります.
これは.textセクションがadd5.oの先頭から16進数で40バイト
目(以後,0x40と表記)にあることを意味しています.
odコマンドの-jオプションを使うと,指定したバイト数だけ,
先頭をスキップしてくれます.
この-jオプションを使って,0x40バイトスキップして,
.textセクションの最初だけを16進ダンプします
(head -n3は先頭の3行だけ表示します).
$ od -t x1 -j0x40 add5.o | head -n3
0000100 ❶f3 0f 1e fa 55 48 89 e5 89 7d fc 8b 45 fc 83 c0
0000120 05 5d c3 00 47 43 43 3a 20 28 55 62 75 6e 74 75
0000140 20 39 2e 34 2e 30 2d 31 75 62 75 6e 74 75 31 7e
この結果❶を見ると,.textセクションの最初の4バイトは
F3 0F 1E FAであることが分かります.
これは上の逆アセンブルの結果の先頭4バイトと一致しており,
endbr64命令が,add5.oの先頭から0x40バイト目に存在することが分かりました.
広義のコンパイルとリンク
ここでは広義のコンパイル,つまりCのプログラムfoo.cから
実行可能ファイルa.outを生成する処理の中身を見ていきます.
いちばん大事なのは最後のリンク(link)です.

- ❶ Cの前処理,すなわち
#includeや#defineなどの前処理命令の処理と,マクロ(例えば<stdio.h>が定義するNULLやEOF)の展開を行います.gcc -Eコマンドで実行できますが,内部的にはカッコ内のcppやcc1コマンドが実行されています(現在はcc1). - ❷ 狭義のコンパイル処理で,Cのプログラムをアセンブリコードに変換します.
- ❸ アセンブラ(
asコマンド)によるアセンブル処理で,オブジェクトファイルfoo.oを生成します.foo.o中にはバイナリの機械語命令が入っています. - ❹
foo.oだけでは実行可能ファイルは作れません.例えば,printfなどのライブラリ関数の実体は,libc.a(静的ライブラリ)やlibc.so(動的ライブラリ)の中にあるからです. また,main関数を呼び出すためのCスタートアップルーチン(多くの場合,crt*.oというファイル名)も必要です. また,分割コンパイルの機能を使った結果,foo.oは他のC言語のプログラムをアセンブルしたオブジェクトファイル*.oが必要なことがよくあります. 「このような他のバイナリとfoo.oを合体させてa.outを生成する処理」のことをリンク(link)と呼びます.
広義のコンパイルで具体的にどのような処理が行われてるのかを見るには,
-vをつけてgcc -vとコンパイルすれば表示されます.
(以下では表示を省略しています.全てを表示するにはボタンを押して下さい).
$ gcc -v main.c add5.s |& tee out
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/lib/gcc/x86_64-linux-gnu/11/lto-wrapper
OFFLOAD_TARGET_NAMES=nvptx-none:amdgcn-amdhsa
OFFLOAD_TARGET_DEFAULT=1
Target: x86_64-linux-gnu
Configured with: ../src/configure -v --with-pkgversion='Ubuntu 11.3.0-1ubuntu1~22.04.1' --with-bugurl=file:///usr/share/doc/gcc-11/README.Bugs --enable-languages=c,ada,c++,go,brig,d,fortran,objc,obj-c++,m2 --prefix=/usr --with-gcc-major-version-only --program-suffix=-11 --program-prefix=x86_64-linux-gnu- --enable-shared --enable-linker-build-id --libexecdir=/usr/lib --without-included-gettext --enable-threads=posix --libdir=/usr/lib --enable-nls --enable-bootstrap --enable-clocale=gnu --enable-libstdcxx-debug --enable-libstdcxx-time=yes --with-default-libstdcxx-abi=new --enable-gnu-unique-object --disable-vtable-verify --enable-plugin --enable-default-pie --with-system-zlib --enable-libphobos-checking=release --with-target-system-zlib=auto --enable-objc-gc=auto --enable-multiarch --disable-werror --enable-cet --with-arch-32=i686 --with-abi=m64 --with-multilib-list=m32,m64,mx32 --enable-multilib --with-tune=generic --enable-offload-targets=nvptx-none=/build/gcc-11-aYxV0E/gcc-11-11.3.0/debian/tmp-nvptx/usr,amdgcn-amdhsa=/build/gcc-11-aYxV0E/gcc-11-11.3.0/debian/tmp-gcn/usr --without-cuda-driver --enable-checking=release --build=x86_64-linux-gnu --host=x86_64-linux-gnu --target=x86_64-linux-gnu --with-build-config=bootstrap-lto-lean --enable-link-serialization=2
Thread model: posix
Supported LTO compression algorithms: zlib zstd
gcc version 11.3.0 (Ubuntu 11.3.0-1ubuntu1~22.04.1)
COLLECT_GCC_OPTIONS='-v' '-mtune=generic' '-march=x86-64' '-dumpdir' 'a-'
/usr/lib/gcc/x86_64-linux-gnu/11/cc1 -quiet -v -imultiarch x86_64-linux-gnu main.c -quiet -dumpdir a- -dumpbase main.c -dumpbase-ext .c -mtune=generic -march=x86-64 -version -fasynchronous-unwind-tables -fstack-protector-strong -Wformat -Wformat-security -fstack-clash-protection -fcf-protection -o /tmp/ccTw9Mym.s
GNU C17 (Ubuntu 11.3.0-1ubuntu1~22.04.1) version 11.3.0 (x86_64-linux-gnu)
compiled by GNU C version 11.3.0, GMP version 6.2.1, MPFR version 4.1.0, MPC version 1.2.1, isl version isl-0.24-GMP
GGC heuristics: --param ggc-min-expand=100 --param ggc-min-heapsize=131072
ignoring nonexistent directory "/usr/local/include/x86_64-linux-gnu"
ignoring nonexistent directory "/usr/lib/gcc/x86_64-linux-gnu/11/include-fixed"
ignoring nonexistent directory "/usr/lib/gcc/x86_64-linux-gnu/11/../../../../x86_64-linux-gnu/include"
#include "..." search starts here:
#include <...> search starts here:
/usr/lib/gcc/x86_64-linux-gnu/11/include
/usr/local/include
/usr/include/x86_64-linux-gnu
/usr/include
End of search list.
GNU C17 (Ubuntu 11.3.0-1ubuntu1~22.04.1) version 11.3.0 (x86_64-linux-gnu)
compiled by GNU C version 11.3.0, GMP version 6.2.1, MPFR version 4.1.0, MPC version 1.2.1, isl version isl-0.24-GMP
GGC heuristics: --param ggc-min-expand=100 --param ggc-min-heapsize=131072
Compiler executable checksum: e13e2dc98bfa673227c4000e476a9388
COLLECT_GCC_OPTIONS='-v' '-mtune=generic' '-march=x86-64' '-dumpdir' 'a-'
as -v --64 -o /tmp/cc5o7Jgg.o /tmp/ccTw9Mym.s
GNU assembler version 2.38 (x86_64-linux-gnu) using BFD version (GNU Binutils for Ubuntu) 2.38
COLLECT_GCC_OPTIONS='-v' '-mtune=generic' '-march=x86-64' '-dumpdir' 'a-'
as -v --64 -o /tmp/ccUs2R16.o add5.s
GNU assembler version 2.38 (x86_64-linux-gnu) using BFD version (GNU Binutils for Ubuntu) 2.38
COMPILER_PATH=/usr/lib/gcc/x86_64-linux-gnu/11/:/usr/lib/gcc/x86_64-linux-gnu/11/:/usr/lib/gcc/x86_64-linux-gnu/:/usr/lib/gcc/x86_64-linux-gnu/11/:/usr/lib/gcc/x86_64-linux-gnu/
LIBRARY_PATH=/usr/lib/gcc/x86_64-linux-gnu/11/:/usr/lib/gcc/x86_64-linux-gnu/11/../../../x86_64-linux-gnu/:/usr/lib/gcc/x86_64-linux-gnu/11/../../../../lib/:/lib/x86_64-linux-gnu/:/lib/../lib/:/usr/lib/x86_64-linux-gnu/:/usr/lib/../lib/:/usr/lib/gcc/x86_64-linux-gnu/11/../../../:/lib/:/usr/lib/
COLLECT_GCC_OPTIONS='-v' '-mtune=generic' '-march=x86-64' '-dumpdir' 'a.'
/usr/lib/gcc/x86_64-linux-gnu/11/collect2 -plugin /usr/lib/gcc/x86_64-linux-gnu/11/liblto_plugin.so -plugin-opt=/usr/lib/gcc/x86_64-linux-gnu/11/lto-wrapper -plugin-opt=-fresolution=/tmp/ccgnuv0i.res -plugin-opt=-pass-through=-lgcc -plugin-opt=-pass-through=-lgcc_s -plugin-opt=-pass-through=-lc -plugin-opt=-pass-through=-lgcc -plugin-opt=-pass-through=-lgcc_s --build-id --eh-frame-hdr -m elf_x86_64 --hash-style=gnu --as-needed -dynamic-linker /lib64/ld-linux-x86-64.so.2 -pie -z now -z relro /usr/lib/gcc/x86_64-linux-gnu/11/../../../x86_64-linux-gnu/Scrt1.o /usr/lib/gcc/x86_64-linux-gnu/11/../../../x86_64-linux-gnu/crti.o /usr/lib/gcc/x86_64-linux-gnu/11/crtbeginS.o -L/usr/lib/gcc/x86_64-linux-gnu/11 -L/usr/lib/gcc/x86_64-linux-gnu/11/../../../x86_64-linux-gnu -L/usr/lib/gcc/x86_64-linux-gnu/11/../../../../lib -L/lib/x86_64-linux-gnu -L/lib/../lib -L/usr/lib/x86_64-linux-gnu -L/usr/lib/../lib -L/usr/lib/gcc/x86_64-linux-gnu/11/../../.. /tmp/cc5o7Jgg.o /tmp/ccUs2R16.o -lgcc --push-state --as-needed -lgcc_s --pop-state -lc -lgcc --push-state --as-needed -lgcc_s --pop-state /usr/lib/gcc/x86_64-linux-gnu/11/crtendS.o /usr/lib/gcc/x86_64-linux-gnu/11/../../../x86_64-linux-gnu/crtn.o
COLLECT_GCC_OPTIONS='-v' '-mtune=generic' '-march=x86-64' '-dumpdir' 'a.'
バイナリファイルの種類
実行可能ファイルa.outに関連するバイナリファイルには
以下の4種類があります:
- オブジェクトファイル(
*.o) - 実行可能ファイル(
a.out) - 静的ライブラリファイル(
lib*.a) - 動的ライブラリファイル(
lib*.so)
オブジェクトファイル(*.o)
オブジェクトファイルとはLinuxでファイル名の拡張子が.oなファイルです.
オブジェクトファイルは機械語命令を含んでいますが,
このオブジェクトファイル単体では実行することができません.
実行を可能にするにはリンク(link)処理を経て,
実行可能ファイル
を作成する必要があります.
オブジェクトファイルは再配置可能オブジェクトファイル (relocatable object file)と呼ばれることもあります. オブジェクトファイルはリンク時に再配置(アドレス調整)が可能だからです.
実行可能ファイル(a.out)
実行可能ファイル(executable file)はその名前の通り,OSに実行を依頼すればそのままで実行できるバイナリファイルのことです.
例えば,hello wordの実行可能ファイルa.outはシェル上で以下のように実行できます.
$ ./a.out
hello, world
シェルとは
シェル (shell)とは「ユーザが入力したコマンドを解釈実行するプログラム」です.
例えば,bash, zsh, csh, sh, ksh, tcshなどはすべてシェルです.
Linux上ではユーザが自由にどのシェルを使うかを選ぶことができます.
シェルという名前は(OSの実体をカーネル(核)と呼ぶのに対して)
シェルがユーザに最も近い位置,つまりコンピュータシステムの外殻にあることに
由来してます(シェルの英語の意味は貝殻の殻(から)です).
シェルは,ユーザが指定したa.outなどのプログラムの実行を,
システムコールexecve等を使ってOS(カーネル)に依頼します.
ちなみにターミナル (端末,terminal),あるいはターミナルエミュレータは, ユーザの入出力処理を行うプログラムであり,ターミナル上でシェルは動作しています.
lsなどのシェル上で実行可能なコマンドも実行可能ファイルです.
$ which ls
/usr/bin/ls
$ file /usr/bin/ls
/usr/bin/ls: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, ❶interpreter /lib64/ld-linux-x86-64.so.2, ❷BuildID[sha1]=2f15ad836be3339dec0e2e6a3c637e08e48aacbd, for GNU/Linux 3.2.0, stripped
$ ls
a.out add5.c add5.o add5.s
ELFバイナリの動的リンカのことを(なぜか)interpreterと呼びます.
プログラミング言語処理系のインタプリタとは何の関係もありません.
ELFバイナリでは動的リンカのフルパスを指定することができ,
そのフルパス名をバイナリに埋め込みます.
この場合は 逆アセンブルすると
❶interpreterとは
/lib64/ld-linux-x86-64.so.2 が埋め込まれています.
OSがa.outを実行する際に,
OSはまず動的リンカ(interpreter)をメモリにロードして,
ロードした動的リンカに制御を渡します.
動的リンカはa.out中の他の部分や,動的ライブラリをメモリにロードし,
動的リンクを行ってから,a.outのエントリポイント
(最初に実行を開始するアドレス)にジャンプします.
その後,いくつかの初期化を行ってから,main関数が呼び出されます.a.outのエントリポイントはreadelf -hコマンドで確認できます.
エントリポイントは0x401050番地でした❶.$ readelf -h ./a.out
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: EXEC (Executable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
❶Entry point address: 0x401050
Start of program headers: 64 (bytes into file)
Start of section headers: 16832 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 13
Size of section headers: 64 (bytes)
Number of section headers: 36
Section header string table index: 35
0x401050番地は_startという関数がありました❷.
a.outは_start関数から実行が始まることが分かりました.$ objdump -d ./a.out | egrep 401050 -A 5
0000000000401050 ❷ <_start>:
401050: f3 0f 1e fa endbr64
401054: 31 ed xor %ebp,%ebp
401056: 49 89 d1 mov %rdx,%r9
401059: 5e pop %rsi
40105a: 48 89 e2 mov %rsp,%rdx
40105d: 48 83 e4 f0 and $0xfffffffffffffff0,%rsp
❷BuildID[sha1]とは
BuildIDはバイナリファイルが同じかどうかを識別するユニークな番号(背番号)です.
ここでは2f15で始まる40桁の16進数が /usr/bin/lsのBuildIDです.
BuildIDはLinux ELF特有の機能です.
stripしてもBuildIDは変化しないので,strip前後のファイルが同じかの確認に使えます.
$ gcc hello.c
$ cp a.out a.out.stripped
$ strip a.out.stripped
$ file a.out a.out.stripped
a.out: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=308260da4f7fb6d4116c12670adf6e503637abba, for GNU/Linux 3.2.0, not stripped
a.out.stripped: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=308260da4f7fb6d4116c12670adf6e503637abba, for GNU/Linux 3.2.0, stripped
ここでは説明しませんがコアファイル (core file)にもBuildIDが入っており,
そのコアファイルを出力したa.outを探すことができます.
ちなみにsha1はSHA-1を意味しており,SHA-1は160ビットのハッシュを生成するハッシュ関数です.
gitのハッシュはSHA-1を使っています.
sha1sumコマンドでSHA-1のハッシュを計算できます.
$ sha1sum ./a.out
ff99525ad6a48d78d35d3108401af935a6ca9bbe ./a.out
この結果から分かる通り,BuildIDのハッシュは,単純にa.outから作ったハッシュ値ではありません.
ELFバイナリのヘッダとセクションの一部からハッシュを計算しているようですが,正確な情報は見つかりませんでした(どうやら未公開のようです).
実行可能なコマンドには実行可能ファイルではなく, スクリプトなことがあります.
$ which shasum
/usr/bin/shasum
$ file /usr/bin/shasum
/usr/bin/shasum: Perl script text executable
$ head -3 /usr/bin/shasum
#!/usr/bin/perl
eval 'exec /usr/bin/perl -S $0 ${1+"$@"}'
if 0; # ^ Run only under a shell
shasumコマンドは(実行可能ファイルではなく)Perlスクリプトでした.
静的ライブラリ(lib*.a)
静的ライブラリ(static library)は静的リンク するときに使われるライブラリです. ライブラリとは複数のオブジェクトファイルを1つのファイルにまとめたもの(アーカイブ)です.
LinuxなどのUNIX系のOSでは静的ライブラリのファイル拡張子は.aが多いです.
またWindowsでは.libです.
printfの実体が入っているC標準ライブラリの
静的ライブラリのファイル名はlibc.aです.
動的ライブラリ(lib*.so)
動的ライブラリ(dynamic library)は動的リンク するときに使われるライブラリです. 動的ライブラリは共有ライブラリ(shared library)とも呼ばれます. 動的ライブラリは複数のプロセスからメモリ上で共有されるからです.
Linuxでは動的ライブラリのファイル拡張子は.soです(shared objectの略).
処理系の都合でファイル拡張子に数字がつくことがあります(例:.so.6).
動的ライブラリのファイル拡張子はUnix系のOSでも様々です.
Windowsでは.dllです.
静的リンクと動的リンク
静的ライブラリは静的リンクに使われるライブラリで, 動的ライブラリは動的リンクに使われるライブラリです.
静的リンク
静的リンクとはコンパイル時にリンクを行う手法です. 仕組みは単純ですが,ファイルやメモリの使用量が増える欠点があります. この図で説明したリンクは実は静的リンクでした.
静的リンクしたファイルa.outはリンク済みなので,
ライブラリ関数(例えばprintf)の実体もa.outの中に入っています.

a.outごとにprintfのコピーが作られるので,
ファイルの使用量が無駄に増えてしまいます.
またa.out中のprintfは実行時にもメモリ上で共有されないので,
メモリの使用量も無駄に増えてしまいます.
静的リンクでコンパイルしてみる
// hello.c
#include <stdio.h>
int main (int ac, char **ag)
{
printf ("hello (%d)\n", ac);
}
静的リンクするには-staticオプションをつけます(-static無しだと動的リンクになります).
printfに第2引数を与えているのは,こうしないと,コンパイラが勝手に
printfの呼び出しをputsに変更してしまうことがあるからです.
a.outをfileコマンドで確認するとstatically linkedとあり❶,
静的リンクできたことが分かります.
$ gcc -static hello.c
$ file ./a.out
./a.out: ELF 64-bit LSB executable, x86-64, version 1 (GNU/Linux), ❶statically linked, BuildID[sha1]=40fe6c0daaf2d49fabad4d37bc34fcdd12cb8da9, for GNU/Linux 3.2.0, not stripped
$ ./a.out
hello (1)
練習問題:静的にリンクしたa.out中にprintfの実体があることを確認せよ
a.outを逆アセンブルし,❶<main>:を含む行から15行を表示させます.
(❷-A 14は「マッチした行の後ろ14行も表示する」というオプションです).
main関数は(printfではなく)❸_IO_printfを呼び出していることを確認できます.
$ objdump -d ./a.out | egrep ❷-A 14 ❶"<main>:"
0000000000401cb5 <main>:
401cb5: f3 0f 1e fa endbr64
401cb9: 55 push %rbp
401cba: 48 89 e5 mov %rsp,%rbp
401cbd: 48 83 ec 10 sub $0x10,%rsp
401cc1: 89 7d fc mov %edi,-0x4(%rbp)
401cc4: 48 89 75 f0 mov %rsi,-0x10(%rbp)
401cc8: 8b 45 fc mov -0x4(%rbp),%eax
401ccb: 89 c6 mov %eax,%esi
401ccd: 48 8d 3d 30 33 09 00 lea 0x93330(%rip),%rdi # 495004 <_IO_stdin_used+0x4>
401cd4: b8 00 00 00 00 mov $0x0,%eax
401cd9: e8 72 ec 00 00 callq 410950 ❸<_IO_printf>
401cde: b8 00 00 00 00 mov $0x0,%eax
401ce3: c9 leaveq
401ce4: c3 retq
注:ここでは
egrep -A 14としてますが,皆さんが試す時は,$ objdump -d ./a.out | lessとしてから,
/<main>:とリターンを入力して検索する方が便利でしょう.
次に同じくa.outを逆アセンブルし,`<_IO_printf>:'を含む行から数行を表示させます.
$ objdump -d ./a.out | egrep -A 5 "<_IO_printf>:"
0000000000410950 <_IO_printf>:
410950: f3 0f 1e fa endbr64
410954: 48 81 ec d8 00 00 00 sub $0xd8,%rsp
41095b: 49 89 fa mov %rdi,%r10
41095e: 48 89 74 24 28 mov %rsi,0x28(%rsp)
410963: 48 89 54 24 30 mov %rdx,0x30(%rsp)
これは_IO_printfの定義なので,a.outにprintfの実体があることを確認できました.
なお,以下のnmコマンドでも,a.outにprintfの実体があることを確認できます.
$ nm ./a.out | egrep _IO_printf
0000000000410950 T _IO_printf
実は_IO_printfもprintfも実体は同じです.処理系の都合で,
「実体は同じだけど別の名前をつける」ことがあり,それをエイリアス(別名)といいます.
0x410950番地で調べると,これを確認できます.
$ nm ./a.out | egrep 410950
0000000000410950 T _IO_printf
0000000000410950 T __printf
0000000000410950 T printf
動的リンク
動的リンクとは実行を始める際のロード時(a.outをメモリにコピーする時)
あるいは実行途中にメモリ上でリンクを行う手法です.
現在ではファイルやメモリの消費量を抑えるため,デフォルトで動的リンクが使われることが多いです.
動的リンクしたファイルa.outには
「ライブラリ関数(例えばprintf)とのリンクが必要だよ」という
小さな参照情報だけが入っており,printfの実体は入っていません.
実際のリンクは実行時にメモリ上で行います.

a.outにはprintfを含まないので,ファイルの使用量を抑えられます.
またa.out中のprintfは実行時にはメモリ上で共有されるので,
メモリの使用量も抑えられます.
ファイルサイズを比較してみると,静的リンクしたa.out-staticは約870KB,
動的リンクしたa.out-dynamicは約17KBで,50倍ものサイズ差がありました.
$ gcc -static -o a.out-static hello.c
$ gcc -o a.out-dynamic hello.c
$ ls -l a.out*
-rwxrwxr-x 1 gondow gondow 16696 Jul 20 17:52 a.out-dynamic
-rwxrwxr-x 1 gondow gondow 871832 Jul 20 17:51 a.out-static
動的リンクでコンパイルしてみる
Linuxでは-staticオプションをつけなければ動的リンクになります.
$ gcc hello.c
$ file a.out
a.out: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=308260da4f7fb6d4116c12670adf6e503637abba, for GNU/Linux 3.2.0, not stripped
$ ./a.out
hello (1)
実行時にリンクが必要な動的ライブラリの情報はlddコマンドで表示できます.
$ ldd ./a.out
❶linux-vdso.so.1 (0x00007ffd21638000)
❷libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fcfef5c1000)
❸/lib64/ld-linux-x86-64.so.2 (0x00007fcfef7d8000)
このa.outはlinux-vsdo.so.1,libc.so.6,ld-linux-x86-64.so.2という
3つの動的ライブラリと実行時にリンクする必要があることを表示しています.
libc.so.6は(LD_LIBRARY_PATHなどの設定がなければ)
絶対パス/lib/x86_64-linux-gnu/libc.so.6とリンクされます.
❶linux-vdso.so.1とは
vDSO (virtual dynamic shared objectの略)で,カーネル空間で実行する必要が無い
システムコール(例えばgettimeofday)を高速に実行するための仕組みです.
❷libc.so.6とは
C標準ライブラリが入った動的ライブラリです.
nm -Dコマンドで調べると,printfの実体が入っていることが分かります.
(-Dは共有ライブラリで使われる動的シンボルを表示させるオプションです)
$ nm -D /lib/x86_64-linux-gnu/libc.so.6 | egrep ' T printf'
0000000000061c90 T printf
0000000000061100 T printf_size
0000000000061bb0 T printf_size_info
-Dオプションをつけないと「❶シンボルが無いよ」と言われてしまいます.
(動的シンボル以外はstripされているからです)
$ nm /lib/x86_64-linux-gnu/libc.so.6
nm: /lib/x86_64-linux-gnu/libc.so.6: ❶no symbols
LD_LIBRARY_PATHとは
a.out実行時には,
動的リンカは動的ライブラリをある手順に従って検索します(詳細はman ld).
通常はデフォルトのパス(/libや/usr/libなど)にある動的ライブラリを使いますが,
環境変数LD_LIBRARY_PATHにディレクトリ(複数ある場合は
コロン:で区切る)をセットすることで検索パスを追加できます.
具体的には,
動的リンカはLD_LIBRARY_PATHで指定したディレクトリを
(デフォルトの検索パスよりも先に)検索し,
そこにある動的ライブラリを優先的に使います.
(LD_RUN_PATHも参照下さい).
練習問題:動的にリンクしたa.out中にprintfの実体が無いことを確認せよ
nmコマンドでa.outにはmainを始めごく少数の
関数しか定義しておらず,その中にprintfは入っていないことが以下で確認できます.
$ nm ./a.out | egrep ' T '
00000000000011f8 T _fini
00000000000011f0 T __libc_csu_fini
0000000000001180 T __libc_csu_init
0000000000001149 T main
0000000000001060 T _start
またnmの出力をprintfで検索すると,GLIBC中のprintfへの参照はあるが
a.out中では未定義(U)となっていることが分かります.
$ nm ./a.out | egrep 'printf'
U printf@@GLIBC_2.34
なお逆アセンブルすると<printf@plt>という小さな関数が見つかりますが,
これはprintfの実体ではありません.
$ objdump -d ./a.out | egrep -A 5 "<printf"
0000000000001050 <printf@plt>:
1050: f3 0f 1e fa endbr64
1054: f2 ff 25 75 2f 00 00 bnd jmpq ❶*0x2f75(%rip) # 3fd0 <printf@GLIBC_2.34>
105b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
<printf@plt>はprintfを呼び出す単なる踏み台で,
PLT (procedure linkage table)という仕組みです.
PLTはprintfの最初の呼び出しまでprintfのアドレス解決
(address resolution)を遅延します.具体的には次の2ステップになります.
printf@pltの間接ジャンプ先❶の初期値は「動的リンクする関数(動的リンカ)」になっているため,最初にprintf@pltが呼ばれると,動的リンクを行い,その結果,間接ジャンプ先が「printfの実体」に変更されます❷. そして動的リンカは何もなかったかのようにprintfを呼び出します. (ちなみにprintf@pltの間接ジャンプで参照するメモリ領域は GOT (global offset table)と呼ばれます)- その結果,2回目以降の以下の間接ジャンプ❶では(動的リンカを経由せずに)
printfが呼ばれます.
つまり,GOTにprintfのアドレスを格納することが,ここではアドレス解決になっています.

静的ライブラリを作成してみる
// main.c
#include <stdio.h>
int add5 (int n);
int main (void)
{
printf ("%d\n", add5 (10));
}
// add5.c
int add5 (int n)
{
return n + 5;
}
$ gcc -c add5.c
$ ar rcs libadd5.a add5.o ❶
$ ar t libadd5.a
add5.o ❷
$ file libadd5.a
libadd5.a: current ar archive
$ gcc ❸-static -o a.out-static main.c ❹-L. ❺-ladd5
$ file a.out-static
file ./a.out-static
./a.out-static: ELF 64-bit LSB executable, x86-64, version 1 (GNU/Linux), statically linked, BuildID[sha1]=1bf84a77504302513d6219e4b27316309d08ed2d, for GNU/Linux 3.2.0, not stripped
$ ./a.out-static
15 ❻
- ❶
ar rcsコマンドでadd5.oからlibadd5.aを作成します. - ❷
ar tコマンドでlibadd5.aの中身を調べます.中身はadd5.oだけでした. - ❸❹❺
gccでmain.cとlibadd5.aを静的リンクします. 静的リンクするために❸-staticオプションが必要です.libadd5.aがカレントディレクトリにあることを伝えるために❹-L.が必要です. 静的リンクする静的ライブラリがlibadd5.aであることを伝えるために ❺-ladd5が必要です.(前のlibと後の.aは自動的に付加されます) - ❻ 実行してみると,静的ライブラリ
libadd5.a中のadd5関数を呼び出せました.
動的ライブラリを作成してみる
$ gcc -c add5.c
$ gcc ❶-fPIC ❷-shared -o libadd5.so add5.o
$ file libadd5.so
libadd5.so: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, BuildID[sha1]=415ef51f32145b59c51e836a25959f0f66039768, not stripped
$ gcc main.c -ladd5 -L. ❸-Wl,-rpath .
$ file ./a.out
./a.out: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=a5d4f8ef61cef4e0b063376333f07170d312c546, for GNU/Linux 3.2.0, not stripped
$ ldd ./a.out
linux-vdso.so.1 (0x00007ffff7fcd000)
libadd5.so => ❹./libadd5.so (0x00007ffff7fbd000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007ffff7dad000)
/lib64/ld-linux-x86-64.so.2 (0x00007ffff7fcf000)
$ ./a.out
15 ❺
- ❶❷
add5.cから動的ライブラリlibadd5.soを作ります.libadd5.soを位置独立コード(PIC)にするために,❶-fPICが必要です.libadd5.soを共有オブジェクト(shared object)にするために,❷-sharedが必要です. - ❸
gccでmain.cとlibadd5.soを動的リンクします. 実行時に動的ライブラリを探索するパスを❸-Wl,-rpath .で指定しています. ここではlibadd5.soをカレントディレクトリに置いているためです. (セキュリティ上,実際に使う際は絶対パスを指定する方が安全でしょう). ちなみに-Wl,-rpath .をgccに指定すると,ldコマンド に-rpath .というオプションが渡されます . - ❹
lddコマンドで調べると,a.out中のlibadd5.soは./libadd5.soを参照していることを確認できました. - ❺ 実行してみると,動的ライブラリ
libadd5.so中のadd5関数を呼び出せました.
-rpath,LD_RUN_PATH,LD_LIBRARY_PATH
❸-Wl,-rpath .はコンパイル時に「動的ライブラリの検索パス」をa.out中に埋め込みます.
以下のコマンド等で確認できます(❻の部分).
$ readelf -d ./a.out | egrep PATH
0x000000000000001d (RUNPATH) Library runpath: ❻[.]
-Wl,-rpath .で指定する検索パスは環境変数LD_RUN_PATHでも指定できます.
(複数の検索パスはコロン:で区切ります).
$ export LD_RUN_PATH="."
$ gcc main.c -ladd5 -L.
$ readelf -d ./a.out | egrep PATH
0x000000000000001d (RUNPATH) Library runpath: [.]
LD_LIBRARY_PATHを使うと,
a.out中の検索パス以外の動的ライブラリを実行時に動的リンクできます.
例えば,以下でlddコマンドを使うと,
/tmp/libadd5.soが使われることを確認できます❼.
$ export LD_LIBRARY_PATH="/tmp"
$ cp libadd5.so /tmp
$ ldd ./a.out
libadd5.so => ❼/tmp/libadd5.so (0x00007ffffffb8000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fffffd8b000)
/lib64/ld-linux-x86-64.so.2 (0x00007ffffffc4000)
なおLD_LIBRARY_PATHは危険で強力なので,なるべく使うのは避けるべきです.
使う場合は最新の注意を払って使いましょう.
なぜならば,例えば,/tmp/libc.so.6という悪意のある動的ライブラリがあると,
/tmp/libc.so.6中のprintfが呼び出されてしまうからです.
(このprintfの中身はコンピュータウイルスかも知れません)
位置独立コードとは
位置独立コード(position independent code, PIC)とはメモリ上の どこにロードしても,そのまま実行できるコードです. 位置独立コードでは絶対アドレスは使わず(再配置が必要になってしまうから), 相対アドレスか間接アドレス参照だけを使います. 位置独立コードにすることで,メモリ上で動的ライブラリを共有できるため, メモリ使用量を抑えることができます.
デバッグ情報
デバッグ情報とは
デバッグ情報とはgccに-gオプションをつけると
バイナリに付加される情報で,
デバッグ時に有用なソースコード中の情報を含んでいます.
例えば,変数の型情報や,ソースコード中の行番号が挙げられます.
$ gcc ❶ -g main.c add5.c
$ file ./a.out
./a.out: ELF 64-bit LSB pie executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=68a01f5977ae542600062913c447a7ba7f2fad62, for GNU/Linux 3.2.0, ❷ with debug_info, not stripped
❶-gオプションをつけてコンパイルしてから,fileコマンドで調べると,
❷デバッグ情報が含まれていることを確認できます.
コンパイラは様々なデバッグ情報の形式を扱えます. LinuxのELFバイナリではDWARFデバッグ情報 が使われることが多いです.(以下,DWARFを前提として説明します)
デバッグ情報が無いと,デバッガでファイル名や行番号が表示されない
デバッグ情報無しでデバッガgdbを使うとどうなるか試してみましょう.
add5.cとmain.cは
前節と同じものを使います.
(gdbの使い方の詳細はデバッガgdbの使い方を参照下さい).
$ gcc ❶ main.c add5.c
$ gdb ./a.out
(gdb) ❷ b add5
Breakpoint 1 at 0x1175
(gdb) ❸ r
Starting program: /tmp/a.out
Breakpoint 1, 0x0000555555555175 in ❹ add5 ()
(gdb) bt
#0 ❻ 0x0000555555555175 in ❺ add5 ()
#1 0x000055555555515b in main ()
(gdb) quit
-gオプション無しで❶コンパイルしています.
add5関数にブレークポイントを設定❷します.
ブレークポイントとはプログラムの実行を一時的に停止する場所です.
関数名add5でブレークポイントを指定したので,
実行するとadd5関数の先頭で実行が一時停止します.
❸ runコマンド (rはrunコマンドの省略形)で実行した所,
add5関数でブレーク(実行を一時停止)できたのですが,
関数名add5だけが表示され,ファイル名や行番号が表示されません❹.
バックトレースを出力しても同様です❺.
バックトレースとは「main関数から現在実行中の関数までの,
関数呼び出し系列」のことです.
ここではmain関数がadd5関数を呼び出しただけなので,
バックトレースは2行しかありません.
❻0x0000555555555175はadd5関数が
0x0000555555555175番地の機械語命令を実行する直前で実行を停止していることを
示しています.
デバッグ情報があると,デバッガでファイル名や行番号が表示される
今回はデバッグ情報ありでデバッガを使ってみます.
$ gcc ❶ -g main.c add5.c
$ gdb ./a.out
(gdb) b add5
Breakpoint 1 at 0x1175: ❷ file add5.c, line 2.
(gdb) r
Starting program: /tmp/a.out
Breakpoint 1, add5 (n=10) at ❸ add5.c:2
2 {
(gdb) bt
#0 add5 (n=10) at ❹ add5.c:2
#1 0x000055555555515b in main () at main.c:5
$ gcc ❶ -g main.c add5.c
$ gdb ./a.out
(gdb) b add5
Breakpoint 1 at 0x1183: ❷ file add5.c, line 3.
(gdb) r
Breakpoint 1, add5 (n=10) at ❸ add5.c:3
3 return n + 5;
(gdb) bt
#0 add5 (n=10) at ❹ add5.c:3
#1 0x000055555555515b in main () at main.c:5
- ❶
-gをつけたので,a.outにはデバッグ情報が付加されています. - 先程とは異なり,❷❸❹ファイル名
add5.cや行番号3が付加されています.
デバッグ情報があると,行番号とアドレスを相互変換できる.
アドレス→行番号の変換
デバッグ情報があるバイナリに対しては,
addr2lineコマンドでアドレスを対応する行番号に変換できます.
$ gcc -g main.c add5.c
$ objdump -d ./a.out | egrep -A 4 "<main>:"
0000000000001149 <main>:
1149: f3 0f 1e fa endbr64
114d: 55 push %rbp
114e: 48 89 e5 mov %rsp,%rbp
1151: bf 0a 00 00 00 mov $0xa,%edi
$ addr2line -e ./a.out ❶ 0x1149
❷/tmp/main.c:4
上の実行例ではaddr2lineコマンドで,
0x1149番地の機械語命令はソースコードでは❷/tmp/main.cの4行目に
対応していることが分かりました.
デバッガ上でも確かめてみましょう.
(gdb) b main
Breakpoint 1 at 0x1151: file main.c, line 5.
(gdb) r
Breakpoint 1, main () at main.c:5
5 printf ("%d\n", add5 (10));
(gdb) ❶ disas
Dump of assembler code for function main:
0x0000555555555149 <+0>: endbr64
0x000055555555514d <+4>: push %rbp
0x000055555555514e <+5>: mov %rsp,%rbp
=> 0x0000555555555151 <+8>: mov $0xa,%edi
0x0000555555555156 <+13>: call 0x555555555178 <add5>
(以下略)
(gdb) ❷ info line *0x0000555555555149
Line 4 of "main.c" starts at address 0x555555555149 <main>
and ends at 0x555555555151 <main+8>.
(gdb) ❸ info line main.c:4
Line 4 of "main.c" starts at address 0x555555555149 <main>
and ends at 0x555555555151 <main+8>.
- (objdumpコマンドでも可能ですが)
gdb上でも逆アセンブルできます. 逆アセンブルのコマンドはdisassembleですが長いので, 短縮名disasをここでは使っています. (gdbは他のコマンドと区別できる範囲で,コマンド名を省略できます). ASLRとPIEが有効な場合, デバッガ上で逆アセンブルすると,実際のメモリのアドレスが表示されて便利です. この場合,上では0x1149番地だったのに,0x0000555555555149番地に変わっています. gdbの❷info lineコマンドを使うと,アドレスから行番号に変換できます.0x555555555149番地はmain.cの4行目に対応しており, また,この行は機械語命令では0x555555555149番地から0x555555555151に 対応していると表示されています.gdb上では❸info lineコマンドを使って, 行番号からアドレスへの変換もできます.
なお,gdbでlayout asmとすると逆アセンブル結果を常に表示できます.
ブレークポイント(左端のbやB)や次に実行する機械語命令の位置(>)が
表示されて分かりやすいです.
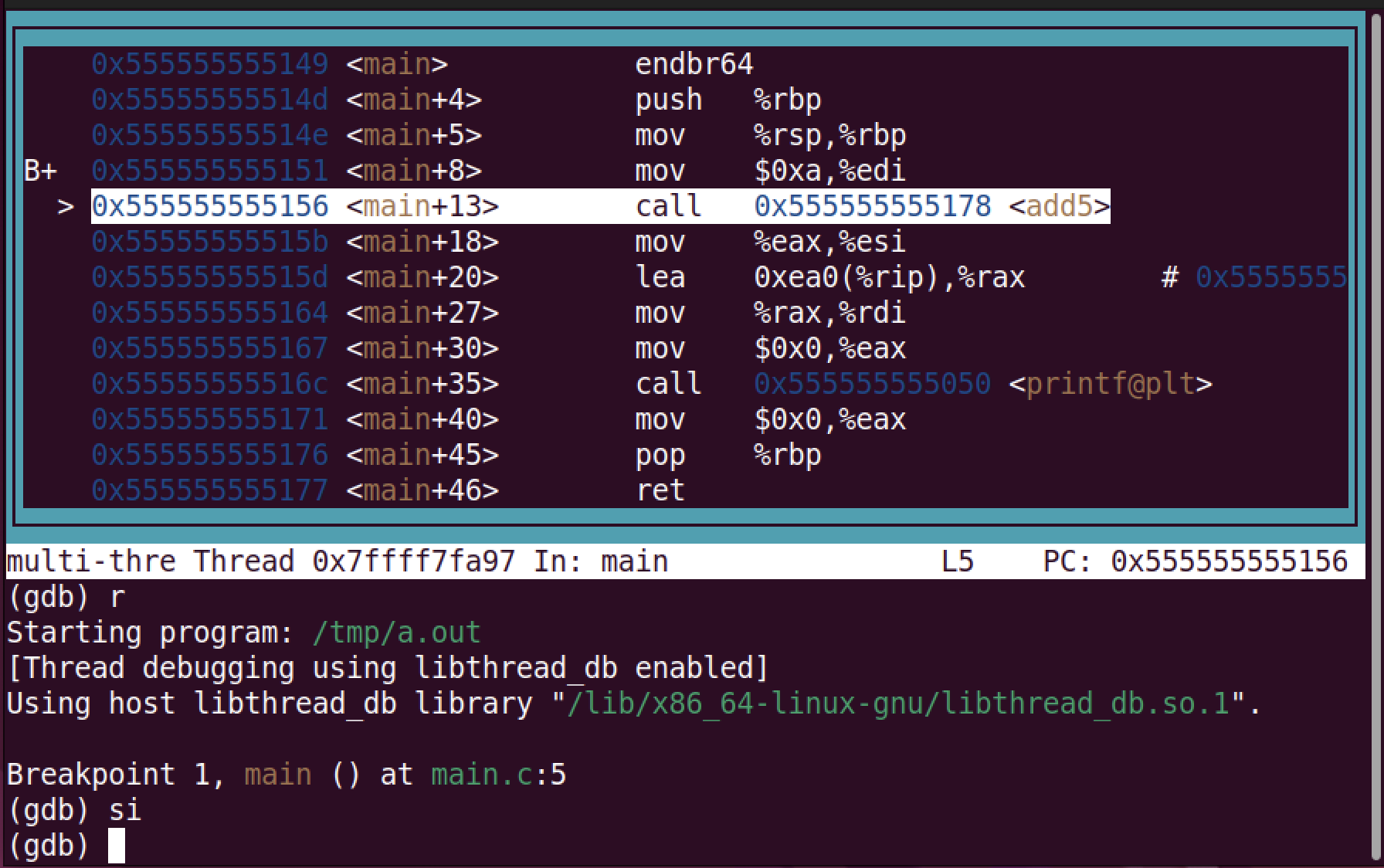
B+ってどういう意味
Bは少なくても一度はブレークしたブレークポイントbは一度もブレークしていないブレークポイント+は有効化されているブレークポイント-は無効化されているブレークポイント
行番号→アドレスの変換
コマンドライン上で,行番号をアドレスに変換するには
(コマンドがちょっと長くなりますが)以下のようにgdbを使います.
$ gdb ./a.out -ex "info line main.c:4" --batch
Line 4 of "main.c" starts at address ❶0x1149 <main> and ends at 0x1151 <main+8>.
上ではプログラムを実行せずにアドレスを取得したので,
a.outファイル中のアドレス❶0x1149が表示されています.
実行時のアドレスを表示したいなら,以下のようにします
(バッチモードで,b main,run,info line main.c:4という3つのコマンドを実行しています).
実行時のアドレス❷0x555555555149を表示できました.
$ gdb ./a.out -ex "b main" -ex "r" -ex "info line main.c:4" --batch
Breakpoint 1, main () at main.c:5
5 printf ("%d\n", add5 (10));
Line 4 of "main.c" starts at address ❷0x555555555149 <main> and ends at 0x555555555151 <main+8>.
以下のようにline2addrなどの名前でシェル関数を定義すれば,
短く書けます(が,そんなに頻繁には使わないかも).
$ function line2addr () {
> command gdb $1 -ex "info line $2" --batch
> }
$ line2addr ./a.out main.c:4
Line 4 of "main.c" starts at address 0x1149 <main> and ends at 0x1151 <main+8>.
デバッグ情報があると,逆アセンブル時にソースコードも表示できる
デバッグ情報がある場合,
(objdump -dではなく)objdump -Sで逆アセンブルすると
ソースコードも表示できます.
❶関数add5の定義部分であること,
❷return n + 5;の行のコンパイル結果であること,
などが見やすくなります.
$ gcc -g -c add5.c
$ objdump -S ./add5.o
./add5.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <add5>:
❶ int add5 (int n)
{
0: f3 0f 1e fa endbr64
4: 55 push %rbp
5: 48 89 e5 mov %rsp,%rbp
8: 89 7d fc mov %edi,-0x4(%rbp)
❷ return n + 5;
b: 8b 45 fc mov -0x4(%rbp),%eax
e: 83 c0 05 add $0x5,%eax
}
11: 5d pop %rbp
12: c3 ret
デバッガでレジスタの値を確認する
デバッガでレジスタの値を確認できます.
$ gcc -g main.c add5.c
$ gdb ./aout
(gdb) b add5
Breakpoint 1 at 0x1183: file add5.c, line 3.
(gdb) r
Breakpoint 1, add5 (n=10) at add5.c:3
3 return n + 5;
(gdb) p ❶ $rdi
$1 = 10
(gdb) ❷ info reg
Undefined info command: "regs". Try "help info".
(gdb) info reg
rax 0x555555555149 93824992235849
rbx 0x0 0
rcx 0x555555557dc0 93824992247232
rdx 0x7fffffffe048 140737488347208
rsi 0x7fffffffe038 140737488347192
rdi 0xa 10
(以下略,qを押して表示を停止)
- ❶
gdbでは%ではなく$をつけてレジスタ名を指定します.pはprintコマンドの省略名です.%rdiの値が10であることが分かりました. 16進数で表示したい場合は,p/x $rdiと/xをつけます - ❷ レジスタの値一覧は
info regで表示できます.ページャが起動されるので,qを押して表示を停止します.
gdbでlayout regsとすると,レジスタの値を常に表示できます.
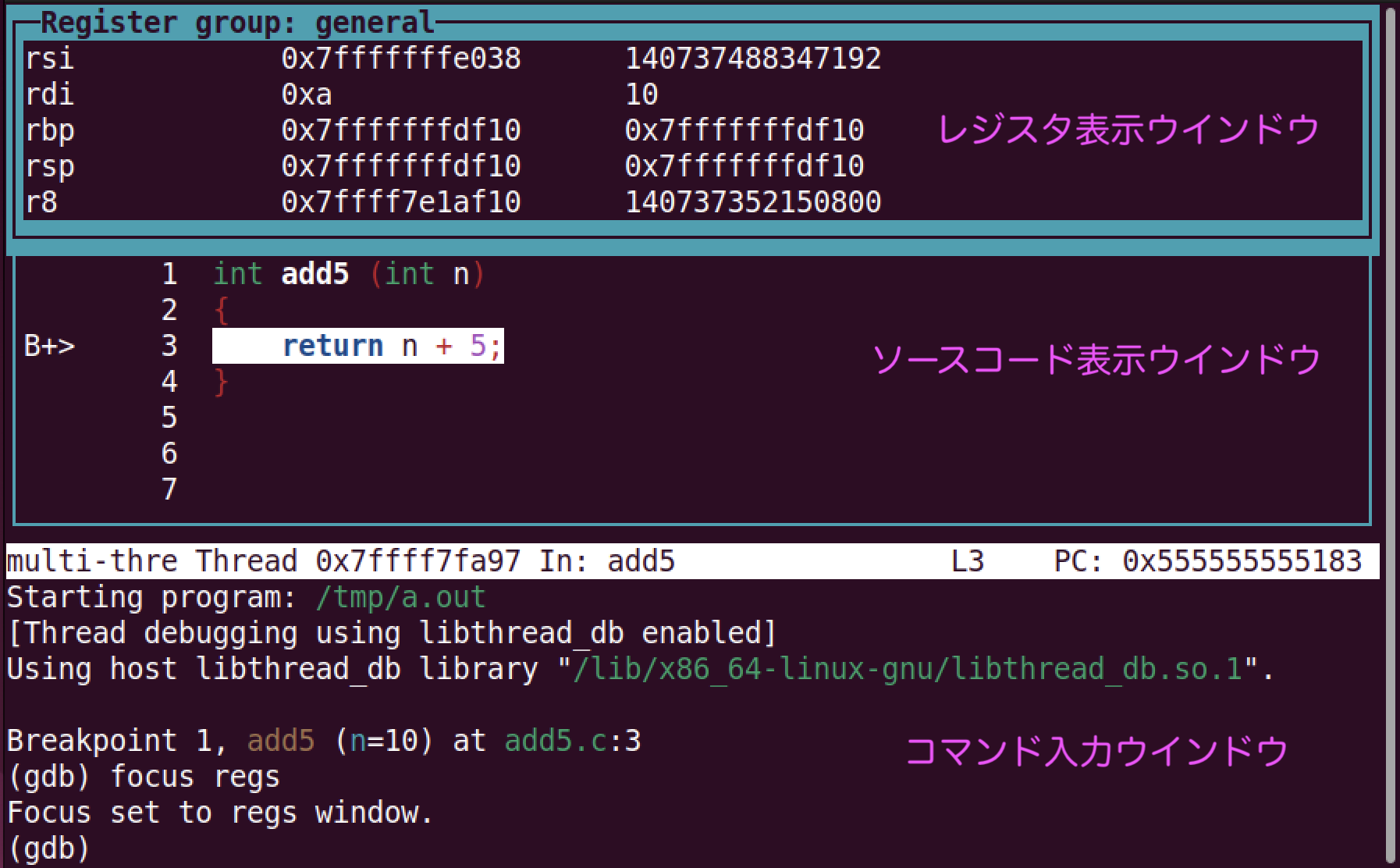
layout regsするとレジスタの値一覧が表示されます. 上から「レジスタ表示」「ソースコード表示」「コマンド入力」のためのウィンドウです.focus regsや,ctrl-x oなどを入力すると,レジスタ表示ウィンドウが選択されます. この状態で↓キーを押すと(あるいはマウスでスクロールされると) レジスタ表示ウィンドウの表示をスクロールできます.ctrl-x aを入力すると,元の表示方法に戻ります.
デバッガでメモリの値を確認する
add5.cとmain.cを
を実行し,add5関数のスタックフレームが作成された直後は
以下の図(ここで使った図の再掲)
になっています.

これをデバッガで確認しましょう.
$ gcc -g main.c add5.c
$ gdb ./a.out
(gdb) b add5
Breakpoint 1 at 0x1183: file add5.c, line 3.
(gdb) r
Breakpoint 1, add5 (n=10) at add5.c:3
3 return n + 5;
(gdb) disas
Dump of assembler code for function add5:
0x0000555555555178 <+0>: endbr64
0x000055555555517c <+4>: push %rbp
0x000055555555517d <+5>: mov %rsp,%rbp
0x0000555555555180 <+8>: mov %edi,-0x4(%rbp)
=> 0x0000555555555183 <+11>: mov -0x4(%rbp),%eax
0x0000555555555186 <+14>: add $0x5,%eax
0x0000555555555189 <+17>: pop %rbp
0x000055555555518a <+18>: ret
(gdb) ❶ p/x $rsp
$1 = 0x7fffffffdf10
(gdb) ❷ p/x $rbp
$2 = 0x7fffffffdf10
(gdb) ❸ x/1gx 0x7fffffffdf10
0x7fffffffdf10: 0x00007fffffffdf20
(gdb) ❹ x/1gx $rsp
0x7fffffffdf10: 0x00007fffffffdf20
(gdb) ❺ x/8bx $rsp
0x7fffffffdf10: 0x20 0xdf 0xff 0xff 0xff 0x7f 0x00 0x00
-
❶❷
%rspと%rbpレジスタの値を調べると,どちらも0x7fffffffdf10番地でした. -
❸
x/1gx 0x7fffffffdf10はメモリの中身を表示するコマンドです.xのコマンド名は examine memory から来ています./1gxは出力形式を指定しています. この場合は「8バイトのデータを16進表記で1つ表示」という意味です.
xコマンドの表示オプション
xコマンドの表示オプションには以下があります(他にもあります).
x16進数d符号あり10進数u符号なし10進数t2進数c文字s文字列
データのサイズ指定には以下があります.
b1バイト (byte)h2バイト (halfword)w4バイト (word)g8バイト (giant)
サイズの用語がバラバラ過ぎる!
以下の通り,GNUアセンブラ(AT&T形式),Intel形式,gdbで各サイズに対する
用語がバラバラです.混乱しやすいので要注意です.
| 1バイト | 2バイト | 4バイト | 8バイト | |
|---|---|---|---|---|
| GNUアセンブラ | byte (b) | short (s) | long (l) | quad (q) |
| Intel形式 | byte | word | double word (dword) | quad word (qword) |
gdb | byte (b) | halfword (h) | word (w) | giant (g) |
- ❹ 具体的なアドレス(ここでは
0x7fffffffdf10)ではなく, レジスタ名 (ここでは$rsp)を指定して, そのレジスタが指しているメモリの中身を表示できます. - ❺
/1gxではなく/8bxと表示形式を指定すると, 「1バイトのデータを16進表記で8個表示」という意味になります.0x7FFFFFFFDF10から0x7FFFFFFFDF17までの各番地には,それぞれ, 以下の図の通り,0x20,0xDF,0xFF,0xFF,0xFF,0x7F,0x00,0x00という値が メモリ中に入っていることが分かります. この格納されている8バイトのデータ0x00007fffffffdf20はアドレスであり, 以下の図の一番下のアドレス(赤字の部分)を指しています.

(上のデバッグの続き)
(gdb) ❻ x/1gx $rsp+8
0x7fffffffdf18: 0x000055555555515b
(gdb) ❼ x/8bx $rsp+8
0x7fffffffdf18: 0x5b 0x51 0x55 0x55 0x55 0x55 0x00 0x00
(gdb) ❽ disas 0x000055555555515b
Dump of assembler code for function main:
0x0000555555555149 <+0>: endbr64
0x000055555555514d <+4>: push %rbp
0x000055555555514e <+5>: mov %rsp,%rbp
0x0000555555555151 <+8>: mov $0xa,%edi
0x0000555555555156 <+13>: call 0x555555555178 <add5>
❾ 0x000055555555515b <+18>: mov %eax,%esi
0x000055555555515d <+20>: lea 0xea0(%rip),%rax # 0x555555556004
0x0000555555555164 <+27>: mov %rax,%rdi
0x0000555555555167 <+30>: mov $0x0,%eax
0x000055555555516c <+35>: call 0x555555555050 <printf@plt>
0x0000555555555171 <+40>: mov $0x0,%eax
0x0000555555555176 <+45>: pop %rbp
0x0000555555555177 <+46>: ret
End of assembler dump.
- ❻
x/1gxを使って,上の図の8(%rsp)のアドレスの中身を表示させています.8(%rsp)の意味は「%rspの値に8を足したアドレス」です.gdb中では「$rsp + 8」と入力します. - ❼
x/8bxを使って,上の図の8(%rsp)のアドレスを1バイトごとに表示しました. 上記の図の通り,0x7FFFFFFFDF18から0x7FFFFFFFDF1Fまでの各番地には,それぞれ,0x5B,0x51,0x55,0x55,0x55,0x55,0x00,0x00が 格納されていることが分かりました. - ❻の結果で得た
0x000055555555515b番地を使って❽逆アセンブルしてみると, ❾この番地は「call add5」の次の命令 (この場合はmov %eax, %esi)であることが 分かりました. このように,戻り番地 (return address)は通常, 「その関数を呼び出したcall命令の次の命令のアドレス」になります.
戻り番地が通常ではない場合って?
末尾コール最適化 (tail-call optimization; TCO)が起こった時が該当します.
- 上の「末尾コール最適化の前」の図では
main関数がAを呼び, 関数AがBを呼んでいます.また逆の順番でリターンします. しかし,call Bの次の命令がret(次の命令❷)になっているため, 関数Bからリターンした後,関数Aでは何もせず,mainにリターンしています. - そこで「末尾コール最適化の後」の図のように,関数
A中のcall命令を 無条件ジャンプ命令jmpに書き換えて,関数Bからは(Aを経由せず) 直接,main関数のリターンするように書き換えて無駄なリターンを省くことができます. これが末尾コール最適化です. - その結果,関数
Bのリターンアドレスは,関数A中のcall命令の次のアドレス (次の命令❷)ではなく,関数main中の「次の命令❶」となってしまいました. これが戻り番地が通常ではない場合の一例です.
デバッグ情報を直接見る
objdump,readelf,llvm_dwarfdumpコマンドを使うと,
デバッグ情報の中身を直接見ることができます.
objdump -W
デバッグ情報には例えば,以下のものがあります
- デバッグ情報 (
.debug_info) - 行情報 (
.debug_line) - アドレス情報 (
.debug_aranges) - フレーム情報 (
.eh_frame) - 省略情報 (
.debug_abbrev)
objdump -W add5.o とすると,add5.o中のデバッグ情報を全て表示します
-Wi, -Wl, -Wr, -Wf,-Waとすると,
それぞれ,デバッグ情報,行情報,アドレス情報,フレーム情報,
省略情報だけを表示できます.
$ objdump -W add5.o | less
add5.o: file format elf64-x86-64
Contents of the .debug_info section:
Compilation Unit @ offset 0x0:
Length: 0x62 (32-bit)
Version: 5
Unit Type: DW_UT_compile (1)
Abbrev Offset: 0x0
Pointer Size: 8
<0><c>: Abbrev Number: 1 (DW_TAG_compile_unit)
<d> DW_AT_producer : (indirect string, offset: 0x5): GNU C17 11.3.0 -mtune=generic -march=x86-64 -g -fasynchronous-unwind-tables -fstack-protector-strong -fstack-clash-protection -fcf-protection
<11> DW_AT_language : 29 (C11)
<12> DW_AT_name : (indirect line string, offset: 0x5): add5.c
(以下略)
上記の出力例では例えば「ファイル名add5.cを省略番号1とします」という情報を含んでいます(詳細は省略し.
コンパイル単位 (compile unit)とはファイルのことです.
例えば,以下の部分は
仮引数の情報として「変数名は❻n,
❷add5.cの❸1行目❹15カラム目で宣言されていて,
型は❺<0x5e>を見てね.変数の場所は❻(DW_OP_fbreg: -20)」となってます.
<2><50>: Abbrev Number: 3 (DW_TAG_formal_parameter)
<51> DW_AT_name : ❶ n
<53> DW_AT_decl_file : ❷ 1
<54> DW_AT_decl_line : ❸ 1
<55> DW_AT_decl_column : ❹ 15
<56> DW_AT_type : ❺ <0x5e>
<5a> DW_AT_location : 2 byte block: 91 6c ❻ (DW_OP_fbreg: -20)
❻DW_OP_fbreg: -20とは
「CFA (canonical frame address)から -20バイトのオフセットの位置」を意味しています.
CFAはDWARFデバッグ情報が定める仮想的なレジスタでCPUごとに異なります.
x86-64の場合は「call命令を実行する直前の%rspの値」なので,以下になります.
(call命令が戻り番地をスタックにプッシュすることを思い出しましょう).
引数n(下図で赤い部分)の先頭アドレスは,
CFAからちょうど-20バイトの場所にあることが確認できました.

-fomit-frame-pointerでコンパイルされていなければ,
(通常は関数の先頭でpush %rbpするので)以下の式が成り立ちます.
CFA == %rbp + 16
なお,fbreg は frame base registerの略だと思います.
Abbrev Number (省略番号)とは
例えば,以下のDIE(デバッグ情報の部品)で Abbrev Number は ❶4となっています.
$ objdump -Wi add5.o
(一部略)
<1><5e>: Abbrev Number: ❶4 (DW_TAG_base_type)
<5f> DW_AT_byte_size : 4
<60> DW_AT_encoding : 5 (signed)
<61> DW_AT_name : int
objdump -Waで.debug_abbrevを表示すると4番目のエントリは
以下となっています.つまり,
- ❷4番のAbbrev Number (省略番号)を持つDIEは ❸DW_TAG_base_type である
- DW_TAG_base_typeには例えば,❹変数名の情報があり,その型は❺DW_FORM_stringである
と分かります.
$ objdump -Wa add5.o
(一部略)
❷4 ❸DW_TAG_base_type [no children]
DW_AT_byte_size DW_FORM_data1
DW_AT_encoding DW_FORM_data1
❹DW_AT_name ❺DW_FORM_string
DW_AT value: 0 DW_FORM value: 0
要するに.debug_abbrevの情報は.debug_infoのメタ情報(型情報)であり,
この場合,4という数字を保持するだけで,
「このDIEはDW_TAG_base_typeである.その内容は…(以下略)」
という情報を持てるのです.
これによりサイズの圧縮が可能になっています.
objdump -Wはある程度は散っている情報をまとめて表示していて親切です.
LEB128とは
LEB128 (little endian base 128)は任意の大きさの整数を扱える 可変長の符号化方式です.直感的にはLEB128はUTF-8の整数版です.
LEB128はDWARFやWebAssemblyなどで使われています. (ですので,DWARFデバッグ情報にはLEB128の符号化が使われている箇所があります. デバッグ情報の16進ダンプを解析する際は注意しましょう).
LEB128には符号ありと符号なしの2種類がありますが,以下では符号なしで説明します.
ここでは123456を符号なしLEB128形式に変換します.
結果は最下位バイトから,0xC0,0xC4,0x07の3バイトになります.
まずbcコマンドで2進数にします❶.
$ bc
obase=2
123456
❶ 11110001001000000
次に以下のステップを踏みます.
ステップ4の結果をbcコマンドで16進数にします❷.
$ bc
obase=16
ibase=2
000001111100010011000000
❷ 7C4C0
結果の16進数❷0x7C4C0 を1バイトごとに最下位バイトから出力すると,
最終的な結果は0xC0,0xC4,0x07となります.
LEB128の最上位バイトの最上位ビットは必ず0で,
それ以外のバイトはの最上位ビットは1なので,
サイズ情報がなくても,
元の整数に戻す際,どのバイトまで処理すればよいかが分かります.
型の情報<0x5e>は以下にありました.
「サイズは❼ 4バイト,❽符号あり,型名は❾int」です.
<1><5e>: Abbrev Number: 4 (DW_TAG_base_type)
<5f> DW_AT_byte_size : ❼ 4
<60> DW_AT_encoding : 5 ❽ (signed)
<61> DW_AT_name : ❾ int
上記の.debug_info中の情報である,
DW_TAG_formal_parameterやDW_TAG_base_typeなどは
DIE (debug information entry)というデバッグ情報の単位の1つです.
DIEは全体で木構造になっています.

またデバッグ情報情報があちこちに散っています. 例えば,❷「ファイル1」の情報はどこにあるかというと
<53> ❷ DW_AT_decl_file : 1
行情報にありました.
以下でエントリ1の情報を見ると,add5.cと分かりました.
$ objdump -Wl add5.o | less
(中略)
The File Name Table (offset 0x2c, lines 2, columns 2):
Entry Dir Name
0 0 (indirect line string, offset: 0x11): add5.c
1 0 (indirect line string, offset: 0x18): add5.c
readelf
readelfコマンドでもobjdumpと同様にDWARFデバッグ情報を表示できます.
以下は実行例です.
$ readelf -wi ./add5.o
Contents of the .debug_info section:
Compilation Unit @ offset 0x0:
Length: 0x62 (32-bit)
Version: 5
Unit Type: DW_UT_compile (1)
Abbrev Offset: 0x0
Pointer Size: 8
<0><c>: Abbrev Number: 1 (DW_TAG_compile_unit)
<d> DW_AT_producer : (indirect string, offset: 0x5): GNU C17 11.3.0 -mtune=generic -march=x86-64 -g -fasynchronous-unwind-tables -fstack-protector-strong -fstack-clash-protection -fcf-protection
<11> DW_AT_language : 29 (C11)
<12> DW_AT_name : (indirect line string, offset: 0x5): add5.c
<16> DW_AT_comp_dir : (indirect line string, offset: 0x0): /tmp
<1a> DW_AT_low_pc : 0x0
<22> DW_AT_high_pc : 0x13
<2a> DW_AT_stmt_list : 0x0
(以下略)
メモリマップを見る
pmapコマンドでメモリマップを見る
pmapコマンドを使うと,
実行中のプログラム(プロセス)がどのメモリ領域を使用しているか
(メモリマップ)を調べられます.
(この出力は/procファイルシステムの /proc/プロセス番号/mapsの内容から作られています).
$ cat
❶ ^Z
[1]+ Stopped cat
$ ps | egrep cat
❷ 7687 pts/0 00:00:00 cat
$ ❸ pmap 7687
7687: cat
❼000055f74daf2000 8K r---- cat
❼000055f74daf4000 16K r-x-- cat
❼000055f74daf8000 8K r---- cat
❼000055f74dafa000 4K r---- cat
❼000055f74dafb000 4K rw--- cat
000055f74dafc000 132K rw--- [ anon ]
00007f63a7e00000 6628K r---- locale-archive
00007f63a8600000 160K r---- libc.so.6
00007f63a8628000 1620K r-x-- libc.so.6
00007f63a87bd000 352K r---- libc.so.6
00007f63a8815000 16K r---- libc.so.6
00007f63a8819000 8K rw--- libc.so.6
00007f63a881b000 52K rw--- [ anon ]
00007f63a8829000 148K rw--- [ anon ]
00007f63a885d000 8K rw--- [ anon ]
00007f63a885f000 8K r---- ld-linux-x86-64.so.2
00007f63a8861000 168K r-x-- ld-linux-x86-64.so.2
00007f63a888b000 44K r---- ld-linux-x86-64.so.2
00007f63a8897000 8K r---- ld-linux-x86-64.so.2
00007f63a8899000 8K rw--- ld-linux-x86-64.so.2
❹ 00007fff86f9f000 132K ❺rw--- ❻[ stack ]
00007fff86ff8000 16K r---- [ anon ]
00007fff86ffc000 8K r-x-- [ anon ]
ffffffffff600000 4K --x-- [ anon ]
total 9560K
$ fg
❽ ^D
-
まず
catコマンドを起動します.ファイル名を指定していないので, 標準入力からの入力待ちになります. ここで❶ ctrl-z を入力して,catコマンドの実行を中断 (suspend)します.pmapコマンドは実行中のプロセスにしか実行できないため,catコマンドが実行中のまま終了しないように,こうしています. -
次に
psコマンドでcatコマンドのプロセス番号を調べます. ❷7687がプロセス番号と分かりました. -
❸プロセス番号7687を引数として
pmapコマンドを実行します. -
出力の各行が使用中のメモリ領域の情報を示しています.例えば,❹の行は次を意味しています.
❹ 00007fff86f9f000 132K ❺rw--- ❻[ stack ]- ❹アドレス`00007fff86f9f000'からサイズ132KBの領域を使用している.
- このメモリ領域の❻アクセス権限は読み書きが可能で,実行は不可.
r読み込み可能w書き込み可能x実行可能
- このメモリ領域は❻スタックとして使用している
-
catコマンド自身は以下の5つのメモリ領域を使用しています.❼000055f74daf2000 8K r---- cat ❼000055f74daf4000 16K r-x-- cat ❼000055f74daf8000 8K r---- cat ❼000055f74dafa000 4K r---- cat ❼000055f74dafb000 4K rw--- cat- アクセス権限が
r-x--のものは,.textセクションでしょう. (.textセクションは通常,実行可能かつ書き込み禁止にするからです) - アクセス権限が
rw----のものは,.dataセクションでしょう. (.dataセクションは通常,実行禁止かつ書き込み可能にするからです) - 残りの3つのアクセス権限が
r----のものは,.rodataセクションなどでしょう. (詳細は調べていません) - 使用しているサイズが4KBの倍数なのは,x86-64でよくある
ページ(page)サイズが4KBだからです.
(ページとは仮想記憶方式の1つであるページングで使われる,
固定長(例えば4KB)に区切ったメモリ領域のことです).
プロセスは
mmapシステムコールを使って,OSからページ単位でメモリを割り当ててもらい,その際にページごとにアクセス権限を設定できます.
- アクセス権限が
-
最後に❽で,中断していた
catコマンドをfgコマンドで実行を再開し,ctrl-Dを入力してcatコマンドの実行を終了しています.
gdbでメモリマップを見る
gdbでもメモリマップを見ることができます
$ gdb /usr/bin/cat
(gdb) r
ctrl-z
Program received signal SIGTSTP, Stopped (user).
(gdb) info proc map
process 7821
Mapped address spaces:
Start Addr End Addr Size Offset Perms objfile
0x555555554000 0x555555556000 0x2000 0x0 r--p /usr/bin/cat
0x555555556000 0x55555555a000 0x4000 0x2000 ❶r-xp /usr/bin/cat
0x55555555a000 0x55555555c000 0x2000 0x6000 r--p /usr/bin/cat
0x55555555c000 0x55555555d000 0x1000 0x7000 r--p /usr/bin/cat
0x55555555d000 0x55555555e000 0x1000 0x8000 rw-p /usr/bin/cat
0x55555555e000 0x55555557f000 0x21000 0x0 rw-p [heap]
0x7ffff7400000 0x7ffff7a79000 0x679000 0x0 r--p /usr/lib/locale/locale-archive
0x7ffff7c00000 0x7ffff7c28000 0x28000 0x0 r--p /usr/lib/x86_64-linux-gnu/libc.so.6
0x7ffff7c28000 0x7ffff7dbd000 0x195000 0x28000 r-xp /usr/lib/x86_64-linux-gnu/libc.so.6
0x7ffff7dbd000 0x7ffff7e15000 0x58000 0x1bd000 r--p /usr/lib/x86_64-linux-gnu/libc.so.6
0x7ffff7e15000 0x7ffff7e19000 0x4000 0x214000 r--p /usr/lib/x86_64-linux-gnu/libc.so.6
0x7ffff7e19000 0x7ffff7e1b000 0x2000 0x218000 rw-p /usr/lib/x86_64-linux-gnu/libc.so.6
0x7ffff7e1b000 0x7ffff7e28000 0xd000 0x0 rw-p
0x7ffff7f87000 0x7ffff7fac000 0x25000 0x0 rw-p
0x7ffff7fbb000 0x7ffff7fbd000 0x2000 0x0 rw-p
0x7ffff7fbd000 0x7ffff7fc1000 0x4000 0x0 r--p [vvar]
0x7ffff7fc1000 0x7ffff7fc3000 0x2000 0x0 r-xp [vdso]
0x7ffff7fc3000 0x7ffff7fc5000 0x2000 0x0 r--p /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
0x7ffff7fc5000 0x7ffff7fef000 0x2a000 0x2000 r-xp /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
0x7ffff7fef000 0x7ffff7ffa000 0xb000 0x2c000 r--p /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
0x7ffff7ffb000 0x7ffff7ffd000 0x2000 0x37000 r--p /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
0x7ffff7ffd000 0x7ffff7fff000 0x2000 0x39000 rw-p /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
0x7ffffffde000 0x7ffffffff000 0x21000 0x0 rw-p [stack]
0xffffffffff600000 0xffffffffff601000 0x1000 0x0 --xp [vsyscall]
アクセス権限rwxpの❶pとは
mmapでメモリ領域をマップする際に,
フラグとしてMAP_PRIVATEを指定するとp,
MAP_SHAREDを指定するとsと表示されます.
-
MAP_PRIVATEマップした領域への変更はプロセス間で共有されません. このマップはcopy-on-writeなので,書き込まれるまで自分専用のコピーは発生せず,共有されます. (copy-on-writeとは「書き込みが起こるまでコピーを遅延する」というテクニックです). -
MAP_SHAREDマップした領域への変更はプロセス間で共有されます. すなわちマップした領域に書き込みを行うと, その変更は他のプロセスにも見えます. ただし,msyncを使う必要があります.
❶.textセクションの共有設定もpとなっています.
これは.textセクションもmmapのMAP_PRIVATEでマップしているからです.
動的リンクした実行可能ファイルの.textセクションは
物理メモリ上で共有されていますが,
その共有とMAP_SHAREDは関係ないのです.
再配置情報
再配置情報の概要
再配置情報(relocation information)とは「後でアドレス調整する時のために,
機械語命令中のどの場所をどんな方法で書き換えればよいか」を表す情報です.
オブジェクトファイル*.oは一般的に再配置情報を含んでいます.
// asm/reloc-main.c
#include <stdio.h>
extern int x;
int main ()
{
printf ("%d\n", x);
}
// asm/reloc-sub.c
int x = 999;
例えば,上のreloc-main.cと
reloc-sub.cを見て下さい.
reloc-main.c中で参照している変数xの実体はreloc-main.c中には無く,
実体はreloc-sub.c中にあります.

ですので,reloc-main.s中の
movq x(%rip), %eaxをアセンブルしてreloc-main.oを作っても,
この時点ではxのアドレスが不明なので,仮のアドレス(上図では00 00 00 00)
にするしかありません.
そこで,このmovq x(%rip), %eax命令に対する再配置情報として
「この命令の2バイト目から4バイトを4バイト長の%rip相対アドレスで埋める」
という情報(R_X86_64_PC32,後述)を
reloc-main.o中に保持しておき,リンク時に正しいアドレスを埋め込むのです.

$ gcc -c reloc-main.c
$ gcc -c reloc-sub.c
$ gcc reloc-main.o reloc-sub.o
なんでgccを3回?
通常はgcc reloc-main.c reloc-sub.cと,gccを一回実行して
a.outを作ります.が,ここではreloc-main.oの中の再配置情報を
見たいので,わざわざ別々にreloc-main.oとreloc-sub.oを作り,
最後にリンクしてa.outを作っています.
reloc-main.oとreloc-sub.oをリンクしてa.outを作ると,
(様々な*.o中のセクションを一列に並べることで)
変数xのアドレスが0x4010に決まり,
上図の「次の命令」のアドレスも0x1157に決まりました.
仮のアドレスに埋めたかったのは,%rip相対番地でしたので,
0x4010-0x1157=0x2EB9と計算した0x2EB9番地を仮のアドレスの部分に埋めました.
これが再配置です.
様々な*.o中のセクションを一列に並べることで,とは

例えば上図でfoo2.o中の変数xのアドレスは仮アドレス0x1000ですが,
foo1.oとfoo2.o中のセクションを1列に並べると,
リンク後は「a.outの先頭アドレスが(例えば)0x4000なので,先頭から数えると,
(0x4000 + 0x0500 + 0x1000 = 0x5500という計算をして)
変数xのアドレスは0x5500に決まりますよね」という話です.
objdump -dr で再配置情報を見てみる
$ gcc -g -c reloc-main.c
$ objdump -dr reloc-main.o
./reloc-main.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
0: f3 0f 1e fa endbr64
4: 55 push %rbp
5: 48 89 e5 mov %rsp,%rbp
8: 8b 05 ❶ 00 00 00 00 mov 0x0(%rip),%eax # e <main+0xe>
❷ a: R_X86_64_PC32 x-0x4
e: 89 c6 mov %eax,%esi
10: 48 8d 05 ❸ 00 00 00 00 lea 0x0(%rip),%rax # 17 <main+0x17>
❹ 13: R_X86_64_PC32 .rodata-0x4
17: 48 89 c7 mov %rax,%rdi
1a: b8 00 00 00 00 mov $0x0,%eax
1f: e8 00 00 00 00 call 24 <main+0x24>
20: R_X86_64_PLT32 printf-0x4
24: b8 00 00 00 00 mov $0x0,%eax
29: 5d pop %rbp
2a: c3 ret
前節の説明を,実際に再配置情報を見ることで確かめます.
上の実行例はobjdump -drでreloc-main.oの逆アセンブルの結果と
再配置情報の両方を表示させたものです.
- ❶を見ると図の通り,仮のアドレス
00 00 00 00を確認できます. - ❷の
a: R_X86_64_PC32 x-0x4が再配置情報です.aは仮のアドレスを書き換える場所(.textセクションの先頭からのオフセット)です. 命令mov 0x0(%rip), %eaxの先頭のオフセットが0x8なので,0x8に2を足した値が0xaとなっています (このmov命令の最初の2バイトはオペコード).R_X86_64_PC32は再配置の方法を表しています. 「%rip相対アドレスで4バイト(32ビット)としてアドレスを埋める」ことを意味しています. (PCはプログラムカウンタ,つまり%ripを使うことを意味しています).x-0x4は「変数xのアドレスを使って埋める値を計算せよ. その際に-0x4を足して調整せよ」を意味しています.
-4はどう使うのか
R_X86_64_PC32はSystem V ABIが
定めており,埋めるアドレスのサイズは4バイト(32ビット),
埋めるアドレスの計算方法はS + A - Pと定めています.
Sはそのシンボルのアドレス (上の例では0x4010)Aは調整用の値 (addend と呼びます.上の例では-4)Pは仮アドレスを書き換える場所 (上の例では0x1157 - 4番地)
なので,計算すると
0x4010 + (-4) - (0x1157 - 4) = 0x2EB9
となります.
- ❸は"%d\n"という文字列の仮アドレス,❹はその仮アドレスの再配置情報です. ❶❷と同様です.
readelf -rで再配置情報を見てみる
$ readelf -r reloc-main.o | less
Relocation section '.rela.text' at offset 0x5b0 contains 3 entries:
Offset Info Type Sym. Value Sym. Name + Addend
00000000000a 000a00000002 R_X86_64_PC32 0000000000000000 x - 4
000000000013 000300000002 R_X86_64_PC32 0000000000000000 .rodata - 4
000000000020 000b00000004 R_X86_64_PLT32 0000000000000000 printf - 4
(略)
readelf -rでもobjdump -drと同様の結果が得られます.
PLTの再配置情報
printfの再配置情報も見てみましょう.

$ objdump -dr ./reloc-main.o
./reloc-main.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
0: f3 0f 1e fa endbr64
4: 55 push %rbp
5: 48 89 e5 mov %rsp,%rbp
8: 8b 05 00 00 00 00 mov 0x0(%rip),%eax # e <main+0xe>
a: R_X86_64_PC32 x-0x4
e: 89 c6 mov %eax,%esi
10: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # 17 <main+0x17>
13: R_X86_64_PC32 .rodata-0x4
17: 48 89 c7 mov %rax,%rdi
1a: b8 00 00 00 00 mov $0x0,%eax
1f: e8 ❶ 00 00 00 00 call 24 <main+0x24>
❷ 20: R_X86_64_PLT32 printf-0x4
24: b8 00 00 00 00 mov $0x0,%eax
29: 5d pop %rbp
2a: c3 ret
$ objdump -d ./a.out
0000000000001149 <main>:
1149: f3 0f 1e fa endbr64
114d: 55 push %rbp
114e: 48 89 e5 mov %rsp,%rbp
1151: 8b 05 b9 2e 00 00 mov 0x2eb9(%rip),%eax # 4010 <x>
1157: 89 c6 mov %eax,%esi
1159: 48 8d 05 a4 0e 00 00 lea 0xea4(%rip),%rax # 2004 <_IO_stdin_used+0x4>
1160: 48 89 c7 mov %rax,%rdi
1163: b8 00 00 00 00 mov $0x0,%eax
1168: ❸e8 e3 fe ff ff call 1050 <printf@plt>
116d: b8 00 00 00 00 mov $0x0,%eax
1172: 5d pop %rbp
1173: c3 ret
先程のxの場合とほぼ同じです.
- ❶を見ると図の左側の通り,仮のアドレス
00 00 00 00を確認できます. - ❷の
20: R_X86_64_PLT32 printf-0x4が再配置情報です.20は仮のアドレスを書き換える場所(オフセット)です.R_X86_64_PLT32は再配置の方法を表しており 「printf@pltへの%rip相対アドレス (4バイト(32ビット))を埋める」ことを意味しています.printf-0x4は「変数printf@pltのアドレスを使って埋める値を計算せよ. その際に-0x4を足して調整せよ」を意味しています.
-4はどう使うのか
R_X86_64_PLT32はSystem V ABIが
定めており,埋めるアドレスのサイズは4バイト(32ビット),
埋めるアドレスの計算方法はL + A - Pと定めています.
LはそのシンボルのPLTエントリのアドレス (上の例ではprintf@pltのアドレス0x1050)Aは調整用のaddend (上の例では-4)Pは仮アドレスを書き換える場所 (上の例では0x116D - 4番地)
なので,計算すると
0x1050 + (-4) - (0x116D - 4) = -0x11D = 0xFFFFFEE3
となります.
a.out中では「次の命令」が0x116D番地,printf@pltが0x1050番地と決まったので,0x1050 - 0x116D = -0x11D = 0xFFFFFEE3番地が ❸の部分に埋め込まれました.
ここでも説明した通り,
printfの実体はCライブラリの中にあり,
(gccのデフォルト動作である)動的リンクの場合,
PLTとGOTの仕組みを使って,printfを呼び出します.
これは先程のxの場合は
「(main関数中の)次の命令と変数xの相対アドレスは固定で決まる」のに対して,
printfの場合は固定で決まらないからです
(Cライブラリが実行時に何番地にロードされるか不明だから).

そこで,
main関数中では(printfを直接呼ぶのではなく), (printfのための踏み台である)printf@pltを呼び出す.printf@pltはGOT領域に実行時に書き込まれるprintfのアドレスを使い, 間接ジャンプ (上図ではbnd jmp *0x2f75(%rip))して, 本物のprintfを呼び出す.
という仕組みになっています.
ABI と API
ABIとAPIはどちらも互換性のための規格(お約束)ですが, 対象がそれぞれ,バイナリ,ソースコード,と異なります.
ABI
- ABI = Application Binary Interface
- バイナリコードのためのインタフェース規格.
- 同じABIをサポートするシステム上では再コンパイル無しで 同じバイナリを使ったり実行できる.
- ABIはコーリングコンベンション(関数呼び出し規約, calling convention), バイトオーダ,アラインメント,バイナリ形式などを定める
- Linux AMD64のABI はSystem V ABI (AMD64)
API
- API = Application Programming Interface
- ソースコードのためのインタフェース規格
- 同じAPIをサポートするシステム上では再コンパイルすれば 同じソースコードを実行できる.
- 例えば,POSIXはUNIXのAPIであり,LinuxはPOSIXにほぼ準拠している.
POSIXはシステムコール,ライブラリ関数,マクロなどの形式や意味を定めている- POSIXはここに書いてあるとおり,opengroup.orgに登録することで無料で入手可能
アーキテクチャ
一般的なコンピュータの構成要素
コンピュータの基本構造

-
コンピュータでは上図のように,CPU,メインメモリ(以後,単にメモリ), 入出力装置が,バス(bus)と呼ばれる信号線でつながっています.
-
CPUは制御装置,ALU(演算装置),レジスタから構成されています
-
バスはデジタルの信号線です. アドレスバス,データバス,制御バスがあります(図にはこの区別は書いていません).
-
上図にはキャッシュやMMUなどがありませんが, 本書の範囲ではこの図の知識で十分です.
CPUの基本構成
- 制御装置 = フェッチ実行サイクルをひたすら繰り返します
- ALU = 四則演算や論理演算などを計算します
- レジスタ
- 高速・小容量・固定長のメモリです
- 特定の役割を持つ専用レジスタ(例: プログラムカウンタ
%rip)と, 様々な用途に使える汎用レジスタ(例:%rax)に概ね分かれています.
メモリ

- メモリはRAMです.揮発性があります(電源が切れると記憶内容は失われます).
- メモリは巨大なバイトの配列です
- メモリのアドレスを指定して,メモリの内容を読み書きします
- バイト単位だけでなく,4バイトや8バイトなどの連続するメモリ領域も読み書きできます
- 通常,メモリには1バイトごとに連番のアドレスがつきます これをバイトアドレッシングといいます.
実際の物理アドレスには,RAMだけでなく,ROMや memory-mapped I/O (メモリのアドレスを使ってアクセスする入出力装置,例えばVRAM)も マップされています.ただし,これらは通常はユーザプロセスからは見えないので気にしなくて良いです.
フェッチ実行サイクル

-
CPUは次の動作をひたすら繰り返します
- フェッチ(fetch)
- プログラムカウンタ(
%rip)が指す機械語命令を メモリからCPUに読み込みます - 次の機械語命令を指すように,プログラムカウンタの値を増やします
- デコード(decode)
- 読み込んだ命令を解析して,実行の準備をします
- 例えば,必要ならメモリからオペランドの値をCPUに読み込みます
- 実行(execute)
- 読み込んだ機械語命令を実行します
x86-64のレジスタ
汎用レジスタ

- 上記16個のレジスタが汎用レジスタ(general-purpose register)です. 原則として,プログラマが自由に使えます.
- ただし,
%rspはスタックポインタ,%rbpはベースポインタと呼び, 一番上のスタックフレームの上下を指す という役割があります. (ただし,-fomit-frame-pointer オプションでコンパイルされたa.out中では,%rbpはベースポインタとしてではなく, 汎用レジスタとして使われています).
caller-saved/callee-savedレジスタ
| 汎用レジスタ | |
|---|---|
| caller-savedレジスタ | %rax, %rcx, %rdx, %rsi, %rdi, %r8〜%r11 |
| callee-savedレジスタ | %rbx, %rbp, %rsp, %r12〜%r15 |
引数
| 引数 | レジスタ |
|---|---|
| 第1引数 | %rdi |
| 第2引数 | %rsi |
| 第3引数 | %rdx |
| 第4引数 | %rcx |
| 第5引数 | %r8 |
| 第6引数 | %r9 |
プログラムカウンタ(命令ポインタ)

ステータスレジスタ(フラグレジスタ)

本書で扱うフラグ
ステータスレジスタのうち,本書は以下の6つのフラグを扱います. フラグの値が1になることを「フラグがセットされる」「フラグが立つ」と表現します. またフラグの値が0になることを「フラグがクリアされる」「フラグが消える」と表現します.
| フラグ | 名前 | 説明 |
|---|---|---|
CF | キャリーフラグ | 算術演算で結果の最上位ビットにキャリーかボローが生じるとセット.それ以外はクリア.符号なし整数演算でのオーバーフロー状態を表す. |
OF | オーバーフローフラグ | 符号ビット(MSB)を除いて,整数の演算結果が大きすぎるか小さすぎるかするとセット.それ以外はクリア.2の補数表現での符号あり整数演算のオーバーフロー状態を表す. |
ZF | ゼロフラグ | 結果がゼロの時にセット.それ以外はクリア. |
SF | 符号フラグ | 符号あり整数の符号ビット(MSB)と同じ値をセット.(0は0以上の正の数,1は負の数であることを表す) |
PF | パリティフラグ | 結果の最下位バイトの値1のビットが偶数個あればセット,奇数個であればクリア. |
AF | 調整フラグ | 算術演算で,結果のビット3にキャリーかボローが生じるとセット.それ以外はクリア.BCD演算で使用する(本書ではほとんど使いません). |
CFフラグが立つ例
# asm/cf.s
.text
.globl main
.type main, @function
main:
movb $0xFF, %al
addb $1, %al # オーバーフローでCFが立つ
ret
.size main, .-main
$ gcc -g cf.s
$ gdb ./a.out
(gdb) b 8
Breakpoint 1 at 0x112d: file cf.s, line 8.
(gdb) r
Breakpoint 1, main () at cf.s:8
8 ret
(gdb) p $al
$1 = ❶ 0
(gdb) p $eflags
$2 = [ ❷ CF PF AF ZF IF ]
(gdb) quit

movb $0xFF, %alとaddb $1, %alで,1バイト符号なし整数の加算0xFF+1をすると,オーバーフローが起きて%alの値は❶ 0になります. (1バイト符号なし整数の範囲は0〜255です.0xFF+1は255+1=256となり (1バイト符号なし整数として)オーバーフローが起きています).p $eflagsでステータスフラグを調べると,❷ CF フラグが立っています.
OFフラグが立つ例
# asm/of.s
.text
.globl main
.type main, @function
main:
movb $0x7F, %al
addb $1, %al # オーバーフローでOFが立つ
ret
.size main, .-main
$ gcc -g of.s
$ gdb ./a.out
(gdb) b main
Breakpoint 1 at 0x1129: file of.s, line 6.
(gdb) r
Breakpoint 1, main () at of.s:6
6 movb $0x7F, %al
(gdb) si
7 addb $1, %al # オーバーフローでOFが立つ
(gdb) si
main () at of.s:8
8 ret
(gdb) p $al
$1 = ❶ -128
(gdb) p $eflags
$1 = [ AF SF IF ❷ OF ]
(gdb) ❸ p/u $al
$2 = ❹ 128
(gdb) quit

movb $0x7F, %alとaddb $1, %alで,1バイト符号あり整数の加算0x7F+1をすると,オーバーフローが起きて%alの値は❶ -128になります. (1バイト符号あり整数の範囲は-128〜127です.0x7F+1は127+1=128となり (1バイト符号あり整数として)オーバーフローが起きています).p $eflagsでステータスフラグを調べると,❷ OF フラグが立っています.- なお,符号なし(❸
u)オプションをつけて%alレジスタの値を表示させると, 符号なしの結果として正しい❹ 128という結果になりました. (x86-64は符号なし・符号ありを区別せず,どちらに対しても正しい結果を 計算します). - ここで説明する通り, 符号あり整数のオーバーフローは未定義動作になるので, 符号あり整数のオーバーフローを起こすプログラムは書いてはいけません.
レジスタの別名
%raxレジスタの別名 (%rbx, %rcx, %rdxも同様)

%raxの下位32ビットは%eaxとしてアクセス可能%eaxの下位16ビットは%axとしてアクセス可能%axの上位8ビットは%ahとしてアクセス可能%axの下位8ビットは%alとしてアクセス可能
%raxに値を入れて,%eax, %ax, %ah, %alにアクセスする例
# asm/reg.s
.text
.globl main
.type main, @function
main:
movq $0x1122334455667788, %rax # ❶
ret
.size main, .-main
$ gcc -g reg.s
$ gdb ./a.out
(gdb) b main
Breakpoint 1 at 0x1129: file reg.s, line 6.
(gdb) r
Breakpoint 1, main () at reg.s:6
6 movq $0x1122334455667788, %rax
(gdb) si
main () at reg.s:7
7 ret
(gdb) p/x $rax
$1 = ❷ 0x1122334455667788
(gdb) p/x $eax
$2 = ❸ 0x55667788
(gdb) p/x $ax
$3 = ❹ 0x7788
(gdb) p/x $ah
$4 = ❺ 0x77
(gdb) p/x $al
$5 = ❻ 0x88
(gdb) q
%raxレジスタに❶0x1122334455667788を入れると, 当たり前ですが%raxレジスタには❷0x1122334455667788が入っています.%eaxには(%raxの下位4バイトなので)❸0x55667788が入っています.%axには(%raxの下位2バイトなので)❹0x7788が入っています.%ahには(%axの上位1バイトなので)❺0x77が入っています.%alには(%axの下位1バイトなので)❻0x88が入っています.
%rbpレジスタの別名 (%rsp, %rdi, %rsiも同様)

%rbpの下位32ビットは%ebpとしてアクセス可能%ebpの下位16ビットは%bpとしてアクセス可能%bpの下位8ビットは%bplとしてアクセス可能
%r8レジスタの別名 (%r9〜%r15も同様)

%r8の下位32ビットは%r8dとしてアクセス可能%r8dの下位16ビットは%r8wとしてアクセス可能%r8wの下位8ビットは%r8bとしてアクセス可能
同時に使えない制限
- 一部のレジスタは
%ah,%bh,%ch,%dhと一緒には使えない. - 例:
movb %ah, (%r8)やmovb %ah, %bplはエラーになる. - 正確には
REXプリフィクス付きの命令では,%ah,%bh,%ch,%dhを使えない.
32ビットレジスタ上の演算は64ビットレジスタの上位32ビットをゼロにする
- 例:
movl $0xAABBCCDD, %eaxを実行すると%raxの上位32ビットが全てゼロになる - 例:
movw $0x1122, %axやmovb $0x11, %alでは上位をゼロにすることはない
上位32ビットをゼロにする実行例

# asm/zero-upper32.s
.text
.globl main
.type main, @function
main:
movq $0x1122334455667788, %rax
movl $0xAABBCCDD, %eax
movq $0x1122334455667788, %rax
movw $0x1122, %ax
movq $0x1122334455667788, %rax
movb $0x11, %al
ret
.size main, .-main
# zero-upper32.txt
b 7
r
list 6,7
p/z $rax
si
p/z $rax
echo # 以下が出力されれば成功\n
echo # $1 = 0x1122334455667788 (%raxは8バイトの値を保持)\n
echo # $2 = 0x00000000aabbccdd (%raxの上位4バイトがゼロになった)\n
quit
$ gcc -g zero-upper32.s
$ gdb ./a.out -x zero-upper32.txt
Breakpoint 1, main () at zero-upper32.s:7
7 movl $0xAABBCCDD, %eax
6 movq $0x1122334455667788, %rax
7 movl $0xAABBCCDD, %eax
$1 = 0x1122334455667788
8 movq $0x1122334455667788, %rax
$2 = 0x00000000aabbccdd
# 以下が出力されれば成功
# $1 = 0x1122334455667788 (%raxは8バイトの値を保持)
# $2 = 0x00000000aabbccdd (%raxの上位4バイトがゼロになった)
オペレーティングシステムの存在
OSは邪魔!?

- アセンブリ言語の利点はCPUや 周辺機器のハードウェア(入出力装置)がよく見えることです
- でもユーザプロセス(皆さんが普通に実行しているプログラム)は
OS上で動作するので,OSはCPUやハードウェアの詳細を見せない働きをします
- この抽象化のおかげで,通常のアプリケーションを開発する際に, CPUやハードウェアの詳細を気にすること無くプログラミングできるわけですが.
- 例えば,OSは以下を隠しています.以下でもう少し詳しく説明します.
- OSによるマルチタスク処理: ユーザプロセスはCPUを専有しているように見えます.
- ハードウェアの詳細(例: ハードディスク): ユーザプロセスはシステムコール経由でハードウェア等にアクセスします.
- 物理メモリ: ユーザプロセスは仮想メモリのみアクセス可能で, 物理メモリへの直接アクセスはできません.
- 割り込み (interrupt): ハードウェアがCPUに非同期的に(asyncronously)送る信号が割り込みです. ユーザプロセスが割り込みを直接受け取ることはありません.
OSによるマルチタスク処理

- ユーザプロセスから見ると「ずっとCPUやレジスタを専有している」ように見えます.
- メモリはユーザプロセスごとに割り当てられますが,
CPUの数は少ないので,OSはCPU上で実行するユーザプロセスを定期的に切り替えています.
- このユーザプロセスの切り替えにはタイマー割り込みを使っています. タイマー割り込みが発生すると,OSがブート時に設定した割り込みハンドラを CPUが自動的に起動します.
- その際,ユーザプロセスが使っていたCPUのレジスタ値はメモリに退避します. 実行再開時にはレジスタ値をメモリから回復します.
- ユーザプロセスのプログラムを書く時は, マルチタスクのことを気にする必要はありません(ただしリアルタイムシステムなどは除く).
システムコール

- ユーザプロセスは直接,周辺機器のハードウェアを操作できません.
ユーザプロセスが直接操作するのは面倒だし危険なので,
通常,OSが「ユーザプロセスによるハードウェア操作」を禁止しているからです.
- (Linuxではシステムコール
iopermやioplを使って, この禁止を解除できますが,本書では説明しません).
- (Linuxではシステムコール
- そのため,ユーザプロセスはシステムコールを使って,
ハードウェア操作をカーネル(OS本体)に依頼します.
- ユーザプロセスが動作するアドレス空間をユーザ空間, カーネルが動作するアドレス空間をカーネル空間と呼びます. カーネル空間ではCPUの特権命令の実行やハードウェア操作が可能です.
printfなどのライブラリ関数の呼び出しにはcall命令とret命令を使います. 一方,writeなどのシステムコールの呼び出しは トラップ命令(ソフトウェア割り込み命令)である,syscall/sysret,sysenter/sysexit,int/iretなどを使います. システムコールの呼び出しにはユーザ空間からカーネル空間への切り替えが 必要だからです.
- システムコール内では入出力命令(
in,out,mov)を実行することで ハードウェアの操作を行います. ハードウェア側から来る割り込みは,予めOSが設定した割り込みハンドラが対処します. ユーザ空間ではCPUの特権命令を実行できないので, ユーザプロセス内では(iopermやioplを使わない限り)これらの操作をできません.
仮想メモリ

- OSはx86-64のページング機能などを使って仮想メモリを有効化しています.
- 上図でプロセスAとプロセスBは物理メモリの一部を仮想メモリとして (仮想アドレスを使って)アクセスできる状態です.
printfはプロセスAとプロセスBで共有しています.- 共有している
printf以外は,プロセスはお互いに他のプロセスのメモリの中身にアクセスできません.

-
仮想メモリが有効な状態では, CPUが扱うアドレス(
%ripやメモリ参照でアクセスするアドレス) はすべて仮想アドレスです. CPU上で動作するプログラム(a.out)は 物理メモリのアドレスを使ってのアクセスはできません. -
仮想アドレスから物理アドレスへの変換:
- OSは「仮想アドレスと物理アドレスの対応表」であるページテーブルを 物理メモリ上で管理します.
- 実際の変換はCPUとバスの間にあるMMU(memory management unit)が高速に行います. MMUはCPUから仮想アドレスを受け取り,それを物理アドレスに変換してから, バス上で物理アドレスを使って物理メモリにアクセスします.
割り込みとシグナル

- CPUはバスを介して周辺機器とつながってます. 例えば,キーボードのキーを押すと,キーを押すたび,離すたびに, CPUに割り込みを伝えます.
- 割り込み(interrupt)は周辺機器側からCPUに非同期的(asynchronously)に 送る信号です.
- CPUは割り込みを受け取ると,(ブート時にOSが設定した)割り込みハンドラを自動的に 起動して,その割り込みに対処します.
- 一部の割り込みはユーザプロセスにUNIXシグナルとして配送されます.
例えば,ユーザプロセスはタイマー割り込みを直接,受け取ることはできませんが,
(
alarmやsetitimerなどのシステムコールを使えば)SIGALRMというUNIXシグナルを受け取ることができます.
バイナリ(2進数)でのデータ表現
2進数と符号化
ここでも説明しましたが,
コンピュータの中のデータは,どんな種類のデータ(例えば,整数,文字,
音声,画像)であっても,
機械語命令であっても,すべて0と1だけで表現されています.
そして,そのためにデータの種類ごとに2進数での表現方法,つまり符号化 (encoding)の方法が定められています. 例えば,
- 文字
UをASCII文字として符号化すると,01010101になります. pushq %rbpをx86-64の機械語命令として符号化すると,01010101になります.
おや,どちらも同じ01010101になってしまいました.
この2進数がPなのかpushq %rbpなのか,どうやって区別すればいいでしょう?
答えは「これだけでは区別できません」です.
別の手段(情報)を使って,いま自分が注目しているデータが,
文字なのか機械語命令なのかを知る必要があります.
例えば,この後で説明する.textセクションにある
2進数のデータ列は「.textセクションに存在するから」という理由で
機械語命令として解釈されます.
以下では,整数(特に2の補数による負の数の表現), ASCII文字コード,機械語命令の符号化などを説明します.
2進数と10進数と16進数
位取り記数法
- 10進数で \( 234 \) という数字の値は \[ 2\times 10^2 + 3\times 10^1 + 4\times 10^0 = 200 + 30 + 4 = 234 \]

- 2進数で \( 1101 \) という数字の値は (2進数→10進数の変換)
\[ 1\times 2^3 + 1\times 2^2 + 0\times 2^1 + 1\times 2^0 = 8+4+0+1=13 \]

-
一般的に,n進数で \( d_m d_{m-1} \cdots d_2 d_1 d_0 \) という数字の値は \[ \sum_{i=0}^m d_i\times n^i = d_m\times n^m + d_{m-1}\times n^{m-1} + \cdots d_2\times n^2 + d_1\times n^1 + d_0\times n^0 \]
- この「数字を並べる記法」を位取り記数法 (positional notation)という.
- nを底 (base), あるいは基数 (radix)と呼ぶ.
-
16進数も同様
- 0から9,AからFまでの数字を使う.Aは10,Bは11,\(\cdots\),Fは15を表す.
- 16進数で \( 1\mathrm{F}4 \) という数字の値は (16進数→10進数の変換) \[ 1\times 16^2 + \mathrm{F}\times 16^1 + 4\times 16^0 = 256 + 240 + 4 = 500 \]
- 2進数は表記が長くなるため,16進数を使って短く表記すると便利(だから使う).
対応表
| 10進数 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2進数 | 0 | 1 | 10 | 11 | 100 | 101 | 110 | 111 | 1000 | 1001 | 1010 | 1011 | 1100 | 1101 | 1110 | 1111 |
| 16進数 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
変換方法
2進数→16進数,16進数→2進数
- 最下位ビットから4桁ずつまとめる(上位ビットには0を埋める). 4ビットごとに16進数にすれば良い(10進数ではこの方法は使えない)

10進数→2進数
-
割り算を使う方法
- 0になるまで繰り返し2で割り,余りを逆順に並べる.
- 例: 13を2進数に変換
\[ \left. \begin{align} 13\div 2 = 6 \cdots 1 \\ 6\div 2 = 3 \cdots 0 \\ 3\div 2 = 1 \cdots 1 \\ 1\div 2 = 0 \cdots 1 \end{align} \right\} 余りを下から上に並べて 1101 \]
- これでうまくいく理由は以下の計算と同じだからです
\[ \begin{eqnarray} 13 &=& 2\times6 + \textcolor{red}{1} \\ &=& 2 \times (2 \times 3 + \textcolor{green}{0}) + \textcolor{red}{1}\\ &=& 2 \times (2 \times (2 \times 1 + \textcolor{blue}{1}) + \textcolor{green}{0}) + \textcolor{red}{1}\\ &=& 2 \times ( 2 \times (2 \times (2 \times 0 + \textcolor{magenta}{1}) + \textcolor{blue}{1}) + \textcolor{green}{0}) + \textcolor{red}{1}\\ &=& 2 \times ( 2 \times (2^2 \times 0 + 2^1 \times \textcolor{magenta}{1} + 2 ^0 \times \textcolor{blue}{1}) + \textcolor{green}{0}) + \textcolor{red}{1}\\ &=& 2 \times ( 2^3 \times 0 + 2^2 \times \textcolor{magenta}{1} + 2^1 \times \textcolor{blue}{1} + 2^0 \times \textcolor{green}{0}) + \textcolor{red}{1}\\ &=& 2^4 \times 0 + 2^3 \times \textcolor{magenta}{1} + 2^2 \times \textcolor{blue}{1} + 2^1 \times \textcolor{green}{0} + 2^0 \times \textcolor{red}{1}\\ &=& (2進数で)\textcolor{magenta}{1}\textcolor{blue}{1}\textcolor{green}{0}\textcolor{red}{1}\\ \end{eqnarray} \]
-
2のべき乗を使う方法
- 大きい2のべき乗から順番に, 例えば,\(2^3=8\)を引けたら,\(2^3\)の位を1にする. 0になるまで繰り返す.
- 例: 13を2進数に変換
\[ \left. \begin{eqnarray} 13 - 2^3 &=& 5 \rightarrow 2^3の位は1 \\ 5 - 2^2 &=& 1 \rightarrow 2^2の位は1 \\ 1 - 2^1 &=& 引けない \rightarrow 2^1の位は0 \\ 1 - 2^0 &=& 0 \rightarrow 2^0の位は1 \end{eqnarray} \right\} 上から下に並べて 1101 \]
-
bcコマンドを使う方法-
bcは電卓コマンド.$ bc 1+2*3+10/5 9 ^D (ctrl-dで終了) $ -
例: 10進数 13を2進数に変換
$ bc obase=2 (出力の底を2に変更) 13 1101 (13の2進数は1101) ^D $ -
例: 16進数 1F4 を2進数に変換
$ bc obase=2 (出力の底を2に変更) ibase=16 (入力の底を16に変更,入力の底の変更は出力の後が良い) 1F4 111110100 (1F4の2進数は111110100) ^D $
-
用語: ビット,バイト,LSB,MSB
ビットとバイト

-
ビット (bit)
- ビットはコンピュータが扱うデータ量の最小単位.binary digit の略.
- 2進数のひと桁が1ビット.1ビットで0か1かの2通りの状態を表現.
-
バイト (byte)
- 通常,8ビットのこと
通常,8ビット?
現在では1バイト=8ビットのコンピュータしか目にしませんが, かつてはそうではないコンピュータもありました. そのため,厳密に8ビットを指すための言葉として, オクテット(octet)という言葉も使われています. ですが,1バイト=8ビットと考えて問題ありません.
- ビットやバイトはレジスタやメモリなどの記憶領域の容量の単位としても使われます
- レジスタ
%raxは8バイトのデータを格納できます. - (バイトアドレッシングの)メモリは1つのアドレスごとに1バイトのデータを格納できます
- レジスタ
バイトアドレッシング
バイトアドレッシングなメモリとは 1つのアドレスごとに1バイトのデータを格納できるメモリのこと. つまり,1バイトの配列としてアクセスするメモリのことです. 一方,ワード(バイト数はアーキテクチャ依存)の配列としてアクセスするメモリを ワードアドレッシングなメモリと言います.
MSBとLSB

- ビット列で最左のビットを最上位ビット (MSB, most significant bit)といいます
- ビット列で最右のビットを最下位ビット (LSB, least significant bit)といいます
- 多倍長データの最上位バイト (most significant byte)と 最下位バイト (least significant byte)も略称がMSBとLSBなので, どちらを指すかは要注意です
ビットの呼び方

- LSBから左に(0から始めて)0ビット目,1ビット目,...,7ビット目と呼ぶことが多いです (例えばIntelのマニュアルで Intel 64 and IA-32 Architectures Software Developer Manuals)
- 0から数え始めることを0オリジン (zero-origin),あるいは0ベース (zero-based)といいます
ワード,ロング,クアッド
| サイズ (バイト) | サイズ (ビット) | Cのデータ型 (LP64) | アセンブラ 命令 | 命令 サフィックス | |
|---|---|---|---|---|---|
| バイト | 1 | 8 | char | .byte | movb |
| ワード | 2 | 16 | short | .word | movw |
| ロング, ダブルワード | 4 | 32 | int | .long | movl |
| クアッド | 8 | 64 | long,ポインタ | .quad | movq |
- ワード,ロング,クアッドのサイズはアーキテクチャ依存です. x86-64では,それぞれ,2バイト,4バイト,8バイトになります.
- C言語の整数型やポインタ型のサイズはプラットフォーム依存です.
最近主流のLP64データモデルでは,
上記の通り,
intは4バイト,longとポインタは8バイトになります. - GNUアセンブラでは次の表記等でデータのサイズを指定します.
- アセンブラ命令で整数データを出力する際には,
サイズに応じて,
.byte,.word,.long,.quadを使います - 多くの機械語命令でオペランドのサイズを命令サフィックスで指定します.
例えば,
movqは オペランドのサイズが8バイトであることを示します
- アセンブラ命令で整数データを出力する際には,
サイズに応じて,
<stdint.h>
- 符号あり
| 型名 | 説明 |
|---|---|
int8_t | 符号あり8ビット |
int16_t | 符号あり16ビット |
int32_t | 符号あり32ビット |
int64_t | 符号あり64ビット |
intptr_t | 符号ありポインタ用 |
- 符号なし
| 型名 | 説明 |
|---|---|
uint8_t | 符号なし8ビット |
uint16_t | 符号なし16ビット |
uint32_t | 符号なし32ビット |
uint64_t | 符号なし64ビット |
uintptr_t | 符号なしポインタ用 |
<stdint.h>は標準ヘッダファイルで,固定長の整数や 符号の有無を確実に扱いたい時に便利です.
文字コード
文字コードとは
- 文字コード = 各文字を区別するために,重複無く割り振った番号です
- ASCIIコードで文字
Aの文字コードは(7ビットの)65 - ASCIIコードで文字
9の文字コードは(7ビットの)57
- ASCIIコードで文字
// ascii.c
#include <stdio.h>
int main ()
{
printf ("'%c', %d\n", 'A', 'A');
printf ("'%c', %d\n", '9', '9');
}
$ gcc -g ascii.c
$ ./a.out
'A', 65
'9', 57
-
文字コードにはいろいろな種類がありますが,GNUアセンブラではASCIIコードのみを使います.
-
文字コードはフォント(書体)や文字の大きさの情報は含んでいません.

例えば,上図の文字Aはフォントも大きさも異なりますが, どちらもASCIIコードでは同じ「7ビットの65」です.
ASCIIコード
ASCIIコード表
| 番号 | 文字 | 番号 | 文字 | 番号 | 文字 | 番号 | 文字 | 番号 | 文字 | 番号 | 文字 | 番号 | 文字 | 番号 | 文字 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ^@ | 16 | ^P | 32 | ␣ | 48 | 0 | 64 | @ | 80 | P | 96 | ` | 112 | p |
| 1 | ^A | 17 | ^Q | 33 | ! | 49 | 1 | 65 | A | 81 | Q | 97 | a | 113 | q |
| 2 | ^B | 18 | ^R | 34 | " | 50 | 2 | 66 | B | 82 | R | 98 | b | 114 | r |
| 3 | ^C | 19 | ^S | 35 | # | 51 | 3 | 67 | C | 83 | S | 99 | c | 115 | s |
| 4 | ^D | 20 | ^T | 36 | $ | 52 | 4 | 68 | D | 84 | T | 100 | d | 116 | t |
| 5 | ^E | 21 | ^U | 37 | % | 53 | 5 | 69 | E | 85 | U | 101 | e | 117 | u |
| 6 | ^F | 22 | ^V | 38 | & | 54 | 6 | 70 | F | 86 | V | 102 | f | 118 | v |
| 7 | ^G | 23 | ^W | 39 | ' | 55 | 7 | 71 | G | 87 | W | 103 | g | 119 | w |
| 8 | ^H | 24 | ^X | 40 | ( | 56 | 8 | 72 | H | 88 | X | 104 | h | 120 | x |
| 9 | ^I | 25 | ^Y | 41 | ) | 57 | 9 | 73 | I | 89 | Y | 105 | i | 121 | y |
| 10 | ^J | 26 | ^Z | 42 | * | 58 | : | 74 | J | 90 | Z | 106 | j | 122 | z |
| 11 | ^K | 27 | ^[ | 43 | + | 59 | ; | 75 | K | 91 | [ | 107 | k | 123 | { |
| 12 | ^L | 28 | ^\ | 44 | , | 60 | < | 76 | L | 92 | \ | 108 | l | 124 | ` |
| 13 | ^M | 29 | ^] | 45 | - | 61 | = | 77 | M | 93 | ] | 109 | m | 125 | } |
| 14 | ^N | 30 | ^^ | 46 | . | 62 | > | 78 | N | 94 | ^ | 110 | n | 126 | ~ |
| 15 | ^O | 31 | ^_ | 47 | / | 63 | ? | 79 | O | 95 | _ | 111 | o | 127 | ^? |
- 128個の文字を扱うコード体系
- 通常,MSBを0にした1バイトデータとして扱う
- 英字アルファベット,数字,記号,制御文字 (control character)を含む
制御文字
- 制御文字は出力装置に(文字表示以外の)動作を要求します
-
例: 改行文字
^J(line feed, C言語では\n)は端末ディスプレイに改行を要求する. 「次に表示する位置を変更する」という動作を要求しています. -
例: エスケープ文字
^[で始まる文字列^[[7mは文字反転,^[[0mは元に戻すというANSIエスケープシーケンスです. 「次に表示する文字と背景の色を変更する」という動作を要求しています.$ echo -e "aaa \E[7mbbb\E[0m ccc" aaa bbb ccc $ cat aaa ^[[7mbbb ^[[0mccc (ctrl-vを押してからエスケープキーを入力) aaa bbb cccechoコマンドの-eは「バックスラッシュによるエスケープを解釈する」というオプションです.また,\Eはbashでエスケープ文字を表すエスケープシーケンスです. ほとんどの端末ソフトで文字列bbbと背景色の色が反転します.catコマンドの場合は,ctrl-vを押してからエスケープキーを押すと エスケープ文字が入力できて,^[と表示されます(2文字に見えますがこれで1文字です). -
ASCIIの以下の制御文字は覚えておきましょう.
制御文字 意味 C言語のエスケープ文字 キーボード中のキー ^@ヌル文字 \0^DEnd of File (EOF) ^HBack Space (後退) \bBack Space ^IHorizontal Tab (水平タブ) \tTab ^JLine Feed (改行) \n^MCarriage Return (復帰) \rEnter ^[Escape (エスケープ) Esc ^?Delete (削除) Delete
-
制御文字Deleteが127である理由
パンチカード時代に「穴が開いているビットは1」と扱っていて, Deleteを127 (2進数で1111111)にしておけば, 「どんな文字に対しても全てのビットの穴を開ければ, その文字を削除できたから」です. なおパンチカードの実物は私も見たことはありません. (大昔のゴジラの映画で見た貴ガス).
ctrl-j や ctrl-m で改行できる(ことが多い)理由
- 歴史的な話ですが,
ctrlキーを押しながら,あるキー(例えばj)を押すと,jのASCIIコード(2進数8ビット表記で 01101010)の 上位3ビットをゼロにした 00001010 (つまり改行文字^J)を入力できました. - そのなごりで,今でも
ctrl-jやctrl-mを押すとEnterキーの入力と同じ動作を するソフトウェアが多くあります. 同様に,ctrl-iでTabを,ctrl-[でEscapeを,ctrl-hでBack Spaceを 入力できるソフトウェアが多いです. - もちろん,現在ではキーの処理はソフトウェアごとに自由に決められるので,
ctrl-jで常に改行できるわけではありません.
ファイルの改行文字
| OS | ファイル中の 改行文字 | 記号 |
|---|---|---|
| Linux, macOS | ^J | LF |
| Windows | ^M ^J | CR LF |
-
LinuxやmacOSのファイルでは,通常,ファイル中の改行を Line Feed (
^j, LF)の1文字で表します. 一方,Windows では Carriage Return (^m, CR)とLine Feed (^j, LF)の2文字で表すことが多いです. (ファイル中の改行文字はエディタの設定で通常,変更可能). -
このため,Windows で作成したファイルを Linux で開くと, 行末に
^Mが見えることがあります.「改行が CR LF なんだな」と思って下さい.$ ❶ cat foo2.txt hello byebye $ ❷ cat -v foo2.txt ❸ hello^M byebye^M $ ❹ od -c -t x1 foo2.txt 0000000 h e l l o ❺ \r \n b y e b y e \r \n 68 65 6c 6c 6f 0d 0a 62 79 65 62 79 65 0d 0a 0000017- 例えば,改行が CR LF なファイル
foo2.txtを用意して, ❶catで表示すると普通に表示されますが, ❷-vオプション(制御文字を可視化)を使うと,❸^Mが表示されました. - ❹
odコマンドを使っても,CRの存在を確認できます (❺\r).
- 例えば,改行が CR LF なファイル
文字集合と符号化方式,UnicodeとUTF-8
GNUアセンブラではASCIIコードのみを使用するので, この節の話はスキップ可能です.
- ASCIIコードでは文字コード(文字の背番号,コードポイント)をそのままバイナリ表現として使っていました.
- 一方,多くの文字コード体系では文字集合と符号化方式を区別しています.
-
例えば,Unicodeは(ほぼ世界中の)文字を定める文字集合です. Unicodeで日本語の「あ」のコードポイントは
0x3042です. -
UTF-8はUnicodeの符号化方式の一つです. UTF-8で「あ」をバイト列に符号化すると,
0xE3,0x81,0x82になります. (Unicodeの他の符号化方式として,UTF-16やUTF-32もあります).
$ cat a.txt あ $ od -t x1 a.txt 0000000 e3 81 82 0a 0000004odコマンドで確かめると「あ」が0xE3,0x81,0x82のバイト列と確認できます. 最後の0x0Aは改行文字 (\n)ですね. -
1110や 10を使う理由は あるバイトが文字の最初のバイトなのか,2バイト目以降なのかを簡単に 区別できるからです. また,1バイトの文字 (例えば
A)と混同する心配もありません. -
UTF-8はASCIIと互換性があるのが大きな利点です. ASCIIコードで書かれたテキストはそのままUTF-8として処理できます.
-
符号なし整数
符号なし整数のビット表現
- 2進数の各桁をそのままビット表現とする
- 例: 2を8ビットの符号なし整数で表現すると, 2の2進数は10なので,00000010 になる. (余った上位ビットに0を入れることに注意)
符号なし整数の一覧表
- 前半
| ビット表現 | 10進数 | 16進数 |
|---|---|---|
| 00000000 | 0 | 0x0 |
| 00000001 | 1 | 0x1 |
| 00000010 | 2 | 0x2 |
| \(\vdots\) | \(\vdots\) | \(\vdots\) |
| 01111110 | 126 | 0x7E |
| 01111111 | 127 | 0x7F |
- 後半
| ビット表現 | 10進数 | 16進数 |
|---|---|---|
| 10000000 | 128 | 0x80 |
| 10000001 | 129 | 0x81 |
| 10000010 | 130 | 0x82 |
| \(\vdots\) | \(\vdots\) | \(\vdots\) |
| 11111110 | 254 | 0xFE |
| 11111111 | 255 | 0xFF |
符号なし整数の扱える範囲
- 固定長の整数の範囲は有限
- 例: 8ビット符号なし整数が表現できる範囲は \(0\)から\(255\)まで
- 一般に\(n\)ビット符号なし整数の範囲は \(0\)から\(2^n-1\)まで
- (符号なしなので当然ですが)負の値は表現できない
符号なし整数の最大値と最小値のビットパターン
| ビット表現 | 10進数 | 16進数 | |
|---|---|---|---|
| 8ビットの最小値 | 00000000 | 0 | 0x0 |
| 8ビットの最大値 | 11111111 | 255=\(2^8-1\) | 0xFF |
| 16ビットの最小値 | 00000000 00000000 | 0 | 0x0 |
| 16ビットの最大値 | 11111111 11111111 | 65535=\(2^{16}-1\) | 0xFFFF |
| 32ビットの最小値 | 00000000 00000000 00000000 00000000 | 0 | 0x0 |
| 32ビットの最大値 | 11111111 11111111 11111111 11111111 | 4294967295=\(2^{32}-1\) | 0xFFFFFFFF |
- 見やすさのため8ビットごとにスペースを入れてます
- 最小値は全てのビットが0,最大値は全てのビットが1
- 32ビット符号なし整数の最大値は約42.9億.現在の世界の人口(約80億人)を数えられない
符号なし整数のオーバーフロー
- 演算の結果,表現できる範囲を超えた場合をオーバーフロー (overflow)と言う.
- 8ビット符号なし整数が表現できる範囲は0から255まで(復習)
- 例: 8ビット符号なし整数の255に1を足すと,256は表現できる範囲外なので, オーバーフローして結果は0になる
// overflow1.c
#include <stdio.h>
#include <stdint.h>
int main ()
{
uint8_t x = 255;
x++;
printf ("%d\n", x);
}
$ gcc -g overflow1.c
$ ./a.out
0
- 例: 8ビット符号なし整数の0から1を引くと,-1は表現できる範囲外なので, オーバーフローして結果は255になる
// overflow2.c
#include <stdio.h>
#include <stdint.h>
int main ()
{
uint8_t x = 0;
x--;
printf ("%d\n", x);
}
$ gcc -g overflow2.c
$ ./a.out
255
- 8ビット符号なし整数のオーバーフロー時の動作: 0から255までの範囲に収まるように,256で割った余りを計算結果とする (これはC言語規格の定義とも合致する).
- 一般的には\(n\)ビット符号なし整数の場合, オーバーフローの結果は,\(0\)から\(2^n-1\)の範囲に収まるように, \(2^n\)で割った余りを計算結果とする.
「割った余りを計算結果とする」の別の言い方
「\(2^n\)で割った余りを計算結果とする」の別の言い方として, 以下の言い方をすることがあります.
- 「モジュロ (modulo) \(2^n\)を取る」
- 「\(2^n\)を法とする」
キャリーとボロー
-
キャリー (carry)は繰り上げ,ボロー(borrow)は繰り下げのこと
-
符号なし整数のオーバーフローはキャリーやボローの有無でチェックできる
-
例: 8ビット符号なし整数で255+1を計算すると,キャリーが発生する

-
例: 8ビット符号なし整数で0-1を計算すると,ボローが発生する

-
x86-64では符号なし整数のオーバーフローは, キャリーフラグ(CF)で検出できる. キャリーやボローが発生するとキャリーフラグが立つから.
- cf. x86-64では符号あり整数のオーバーフローは, オーバーフローフラグ(OF)で検出できる
符号あり整数,2の補数
符号あり整数のビット表現
-
非負(0か正数)の数は2進数の各桁をそのままビット表現, 負の数は2の補数 (two's complement)を使う
- MSBは符号ビットになる.0なら非負,1なら負になる.
- 2の補数以外にも負の数の表現方法はある. 2の補数を使う理由は,(1) 減算を加算処理で行えるから, (2) x86-64が2の補数を使っているからです.
-
例: 8ビットの符号あり整数の場合,
- 前半の00000000〜01111111を0と正の数に, 後半の10000000〜11111111を負の数にする.
- 例えば,126に対する(8ビットの場合の)2の補数は130(=256-126)なので, 130の2進表記 10000010 を -126 のビット表現とする.
一覧表
- 前半 (0と正の数)
| ビット表現 | 10進数 | 16進数 |
|---|---|---|
| 00000000 | 0 | 0x0 |
| 00000001 | 1 | 0x1 |
| 00000010 | 2 | 0x2 |
| \(\vdots\) | \(\vdots\) | \(\vdots\) |
| 01111110 | 126 | 0x7E |
| 01111111 | 127 | 0x7F |
- 後半 (負の数)
| ビット表現 | 10進数 | 16進数 |
|---|---|---|
| 10000000 | -128 | -0x80 |
| 10000001 | -127 | -0x7F |
| 10000010 | -126 | -0x7E |
| \(\vdots\) | \(\vdots\) | \(\vdots\) |
| 11111110 | -2 | -0x2 |
| 11111111 | -1 | -0x1 |
2の補数と1の補数
-
2の補数とは(キャリーを無視して)加算して全てのビットが0になる数です
-
例: 8ビットの場合,126 (2進数で 01111110)の2の補数は10000010 (=130)です. 01111110+10000010=00000000になるからです(キャリーを無視すれば). \(126+130=256=2^8\)

-
-
1の補数とは(キャリーを無視して)加算して全てのビットが1になる数です
-
例: 8ビットの場合,126 (2進数で 01111110)の1の補数は 10000001 (=129)です. 01111110+10000001=11111111になるからです. \(126+129=255=2^8-1\)

-
-
2の補数の求め方: 各ビットを反転してから,LSBに1を加えれば良い

-
一般的に,\(n\)進数に対して,\(n\)の補数と,\((n-1)\)の補数が存在します
- \(n\)の補数は「足すとちょうど桁が上がる数」です. 10進数で2桁の数を考える時,\(65\)に対する10の補数は\(35\)になります. 足すと\(100\)になるから.
- \(n-1\)の補数は「足してもギリギリ桁が上がらない数」です. 10進数で2桁の数を考える時,\(65\)に対する9の補数は\(34\)になります. 足すと\(99\)になるから.
符号なし整数と符号あり整数の関係
-
8ビットの場合,符号なし整数の128〜255の範囲のビット表現を, 符号あり整数の-128〜-1の範囲にシフトしたことになる.

-
シフトの幅がどれもちょうど256であることがポイント.
-
「130を足す」のと「126を引く」のは同じ
- 8ビット整数の場合,256を足しても引いても値は変化しませんよね. キャリーやボローとしてはみ出るだけだからです.
- 例えば,1 + 256 = 1 ですし,1 - 256 = 1 です. (数式ではこれを \(1 + 256 \equiv 1 \pmod {256}\) と書きます. 「256で割った余りで考えれば,同じ値である」という意味です. ここでは単に = を使います).
- ですので,4 - 126 = 4 + (-126) = 4 + 256 + (-126) = 4 + 130 となります.
-
時計で考えると分かりやすいかも.時計の上で,「7時間足す」のと「5時間引く」のは同じ.

扱える範囲
- 例: 8ビット符号あり整数が表現できる範囲は \(-128\)から\(127\)まで
- \(128\)まででは無いのはプラス側にはゼロ (0)があるから
- 一般に\(n\)ビット符号なし整数の範囲は \(-2^n/2\)から\(2^n/2-1\)まで
- \(n\)ビットの場合,\(2^n\)通りの数が扱える. 正と負で半分ずつ使ってる (\(2^n/2\))が, 正の方はゼロ (0)があるので \(-1\)となる.
最大値と最小値のビットパターン
| ビット表現 | 10進数 | 16進数 | |
|---|---|---|---|
| 8ビットの最小値 | 10000000 | -128=\(-2^8/2\) | -0x80 |
| 8ビットの最大値 | 01111111 | 127=\(2^8/2-1\) | 0x7F |
| 16ビットの最小値 | 10000000 00000000 | -32768=\(-2^{16}/2\) | -0x8000 |
| 16ビットの最大値 | 01111111 11111111 | 32767=\(2^{16}/2-1\) | 0x7FFF |
| 32ビットの最小値 | 10000000 00000000 00000000 00000000 | -2147483648=\(-2^{32}/2\) | 0x80000000 |
| 32ビットの最大値 | 01111111 11111111 11111111 11111111 | 2147483647=\(2^{32}/2-1\) | 0x7FFFFFFF |
- 見やすさのため8ビットごとにスペースを入れてます
- 最小値はMSBが1でそれ以外の全ビットが0,最大値はMSBが0でそれ以外の全ビットが1
x86-64は符号の有無を気にせず加算する→どちらの結果も正しい
-
2の補数の利点 = 足し算回路で引き算ができる
-
例: 31-126は,31と -126 のビット表現の加算で計算できる.
- つまり 00011111 + 10000010 = 10100001 = -95
- この結果が 31 + 130 = 10100001 = 161 の結果と,ビット表現が一致することに注意
- これは当然で,8ビットの場合,31 + (-126) = 31 + 256 + (-126) = 31 + 130 だから

-
実際,x86-64は整数が符号ありか符号なしかを区別せずに加算している. 計算結果はどちらに対しても正しい.
- プログラマ(あるいはコンパイラ)は符号ありか符号なしかを意識する必要がある. 符号あり・符号なしでビット表現が意味する値が変わるし (上の例では161か-95か), オーバーフローの判定にキャリーフラグ(CF)とオーバーフローフラグ(OF)の どちらを使うべきかを判断する必要があるから.
符号あり整数のオーバーフロー
-
8ビット符号あり整数の64に64を足すと,オーバーフローして結果は-128になる (64 + 64 = 128 は8バイト符号あり整数が表現可能な-128〜127の範囲を超えている).

-
C言語の規格上,符号あり整数のオーバーフローは未定義動作(undefined behavior). つまり,符号あり整数をオーバーフローさせてはいけない.
- 未定義動作を含むプログラムに対して,コンパイラはどのように振る舞っても良い.
- コンパイルエラーにしても良いし,実行するたびに異なる結果を出力するコードを出力しても良いし,それっぽい答え(ここではオーバーフローしたビット表現)を出力しても良い
- ここでは-128の結果を得たが,C言語の規格上,他の結果がでる可能性がある
- 未定義動作を含むプログラムに対して,コンパイラはどのように振る舞っても良い.
符号あり整数では,オーバーフローとキャリーの有無は関係ない
-
符号あり整数ではオーバーフローとキャリーの有無は関係ありません

- 例: 8ビット符号あり整数で,64+64=128 は,表現可能な-128〜127を超えているのでオーバーフロー発生.しかしキャリーは0
- 例: 8ビット符号あり整数で,(-1)+(-1)=-2は,表現可能な-128〜127の範囲内なので オーバーフローは発生していない.しかしキャリーは1
-
このため,x86-64では符号あり整数のオーバーフローを(キャリーフラグ(CF)ではなく) オーバーフローフラグ(OF)で検出する
- 一方,符号なし整数のオーバーフローは キャリーフラグ(CF)で検出する
-
なお人間が判断する場合は以下で簡単に判定できる
- 正と正の数同士(どちらもMSBは0)を足して,負になったら(MSBは1)オーバーフロー発生
- 負と負の数同士(どちらもMSBは1)を足して,正になったら(MSBは0)オーバーフロー発生
- 正と負の数同士の足し算では決してオーバーフローは発生しない
C言語で整数計算に注意が必要な場合
符号あり整数のオーバーフロー (未定義動作)
// overflow4.c
#include <stdio.h>
#include <stdint.h>
int main ()
{
int32_t x1 = 10 * 10000 * 10000; // 10億
int32_t x2 = 15 * 10000 * 10000; // 15億
int32_t x3 = x1 + x2; // オーバーフロー
printf ("%d\n", x3); // -1794967296
}
$ gcc -g overflow4.c
$ ./a.out
-1794967296
- 符号あり整数のオーバーフローはセキュリティ上の脆弱性になるため避けるべきです.
-ftrapvオプションをつけると符号あり整数のオーバーフロー時に トラップが発生します. 試した所,シグナルSIGABRTが発生してプログラムは終了しました.
$ gcc -g -ftrapv overflow4.c
$ ./a.out
Aborted
絶対値を計算できない数がある
// overflow5.c
#include <stdio.h>
#include <stdint.h>
int main ()
{
int8_t x1 = -128;
int16_t x2 = -32768;
int32_t x3 = -2147483648;
x1 = -x1;
x2 = -x2;
x3 = -x3;
printf ("%d, %d, %d\n", x1, x2, x3);
}
$ gcc -g overflow5.c
$ ./a.out
-128, -32768, -2147483648
- 符号あり整数で表現可能な最小の数は絶対値を計算できません.
- 例えば8ビット符号あり整数-128の絶対値は計算できません. 絶対値の128が,表現可能な範囲-128〜127を超えてしまうからです.
- この場合もオーバーフローが起きているので未定義動作となります.
符号ありと符号なしを混ぜると直感に反する結果になる
// signed-unsigned.c
#include <stdio.h>
#include <stdint.h>
int main ()
{
int32_t x1 = -1;
uint32_t x2 = 0;
printf ("%d\n", x1 < x2); // 0
}
$ gcc -g singed-unsigned.c
$ ./a.out
0
- これはオーバーフローではなくC言語の規格に関する話です.
- 上の
signed-unsigned.cを実行すると0が返りました. (-1 < 0は真なので1が返って欲しいのに). - これは違う型同士の演算ではC言語ではまず型を同じにするためです
(通常の算術型変換といいます).
この場合は
-1を符号なしに変換します. その結果,0xFFFFFFFFという大きな正の数になり,0xFFFFFFFF < 0を比較して0が返るわけです. - この問題があるため,C言語では符号ありと符号なしを混ぜて使うことを避けるべきです.
- 通常は符号ありの整数を使う
- ビット演算をしたい場合などに限定して符号なしの整数を使う (符号あり整数へのビット演算は(未定義動作ではないが) 処理系定義の動作を引き起こす場合があるため).
機械語命令の符号化
覚える必要はありません
- 機械語命令の符号化方法はCPUごとに異なります
- x86-64の機械語命令の符号化方法はx86-64のマニュアル Intel 64 and IA-32 Architectures Software Developer Manualsに書いてありますし,アセンブラが自動変換してくれるので,私達は覚える必要は全くありません
- とはいえ,「機械語命令も2進数で符号化されている」ことを確認するために, 機械語命令の符号化をちょっとだけ見てみましょう
概要
- x86-64はCISC (complex instruction set computer)なので, 「1つの命令で複雑な処理をする」という設計哲学です. そのため命令は可変長(1バイト〜15バイト)で複雑です. 一方,RISC (reduced instruction set computer)では命令長は固定長で, 1命令が処理する内容は単純なことが多いです.
命令フォーマット

- 上図はx86-64の基本的な命令フォーマットです(この図と異なる例外的な命令もあります).
- 命令プリフィクス (instruction prefix)には例えばLOCKプリフィクスがあります. LOCKプリフィクスはメモリアクセスをアトミックにする効果がありますが, LOCKプリフィクスをつけて良い命令は一部に限定されています. また,以下ではREXプリフィクスも登場します.
- ModR/MバイトとSIBバイトは, アドレッシングモード,レジスタやメモリオペランドを指定します.
- 変位(displacement)と即値(immediate)はどちらも定数です.
pushq 4(%rsp)の4が変位,pushq $4の4が即値です.
処理方向ビット

- 2つのオペランドを持つ多くの命令で, 1バイトのオペコードの (LSBを0ビット目と数えて)1ビット目が処理方向ビット(operation direction bit)になります.
- 処理方向ビットが
0の時,代入の方向はreg→r/mになります. 一方1の時,代入の方向はr/m→regになります. - 例えば,上図で
movqr64, r/m64のオペコードはREX.W 89,movqr/m64, r64のオペコードはREX.W 8Bです. 確かに,処理方向ビットがそれぞれ0と1になっています. (REX.Wは命令プリフィクスで,オペランドサイズを64ビットにします).
REXプリフィクス

| Intelマニュアル表記 | 意味 |
|---|---|
| REX.W | オペランドサイズを64ビットにする |
| REX.R | ModR/MのRegフィールドの拡張 |
| REX.X | SIBのIndexフィールドの拡張 |
| REX.B | ModR/MのR/M,SIBのBase,オペコードのRegフィールドの拡張 |
REXプリフィクスはx86-64で追加された1バイト長の命令プリフィクスです.- GNUアセンブラが自動挿入するので,アセンブリコードでプログラマが
明示的に
REXプリフィクスを記述する必要は通常はありません. REX.Wはオペランドサイズを64ビットにします.REX.R,REX.X,REX.Bはレジスタを指定する際に使われます. これらの値が1の時,新しいレジスタ%r8〜%r15を指定したことになります.
ModR/MバイトとSIBバイト

- ModR/Mバイトは上図のように分割されてます.
| Mod | 意味 |
|---|---|
| 00 | メモリ参照,変位は無し.ただしR/M=101の時は例外あり(以下参照) |
| 01 | メモリ参照,変位は1バイト |
| 10 | メモリ参照,変位は4バイト |
| 11 | レジスタ参照 |
- ModR/MのModフィールドの意味は上記のとおりです.
$ gcc -g movq-10.s
$ objdump -d ./a.out
0000000000001129 <main>:
1129: 4c 89 c0 mov %r8,%rax # Mod=11,レジスタ
112c: 4c 89 00 mov %r8,(%rax) # Mod=00, メモリ参照,変位無し
112f: 4c 89 40 08 mov %r8,0x8(%rax) # Mod=01,メモリ参照,変位1バイト (0x08)
1133: 4c 89 80 e8 03 00 00 mov %r8,0x3e8(%rax) # Mod=10, メモリ参照,変位4バイト (0xE8, 0x03, 0x00, 0x00)
-
ModR/MのRegフィールドは
REX.Rの1ビットと合わせて,レジスタを指定します(以下の表参照). -
オペランドが1つの時はRegフィールドはレジスタの指定ではなく, オペコードの一部として使われることがあります(なので図中でOpcodeと書いています).
REX.R | Reg | 指定される レジスタ |
|---|---|---|
| 0 | 000 | %rax |
| 0 | 001 | %rcx |
| 0 | 010 | %rdx |
| 0 | 011 | %rbx |
| 0 | 100 | %rsp |
| 0 | 101 | %rbp |
| 0 | 110 | %rsi |
| 0 | 111 | %rdi |
| 1 | 000 | %r8 |
| 1 | 001 | %r9 |
| 1 | 010 | %r10 |
| 1 | 011 | %r11 |
| 1 | 100 | %r12 |
| 1 | 101 | %r13 |
| 1 | 110 | %r14 |
| 1 | 111 | %r15 |
- ModR/MのR/Mフィールドは
REX.Bの1ビットと合わせて,レジスタやメモリ参照を指定します.- Mod=11の時はR/Mフィールドは下の表のレジスタを指定します.
- Mod\(\neq\)11の時はR/Mフィールドは下の表のメモリ参照を指定します.
- ただし,R/M=100の時はSIBバイトを使うことを意味します.
また,R/M=101の時は
%rip相対アドレッシングを使うことを意味します. R/M=101の時,(本来はMod=00は変位無しですが) Mod=00でもMod=10でも変位が4バイトになります.
- ただし,R/M=100の時はSIBバイトを使うことを意味します.
また,R/M=101の時は
REX.B | R/M | 指定される レジスタ (Mod=11) | 指定される メモリ参照 (Mod\(\neq\)11) |
|---|---|---|---|
| 0 | 000 | %rax | (%rax) |
| 0 | 001 | %rcx | (%rcx) |
| 0 | 010 | %rdx | (%rdx) |
| 0 | 011 | %rbx | (%rbx) |
| 0 | 100 | %rsp | SIB使用 |
| 0 | 101 | %rbp | %rip相対 |
| 0 | 110 | %rsi | (%rsi) |
| 0 | 111 | %rdi | (%rdi) |
| 1 | 000 | %r8 | (%r8) |
| 1 | 001 | %r9 | (%r9) |
| 1 | 010 | %r10 | (%r10) |
| 1 | 011 | %r11 | (%r11) |
| 1 | 100 | %r12 | SIB使用 |
| 1 | 101 | %r13 | %rip相対 |
| 1 | 110 | %r14 | (%r14) |
| 1 | 111 | %r15 | (%r15) |
- SIBの各フィールドは,Scale,Indexレジスタ, Baseレジスタを指定します.
(例えば,メモリ参照
(%rax, %rbx, 2)で,%raxがBaseレジスタ,%rbxがIndexレジスタ,2がScaleです).
| Scaleの値 | 乗数 |
|---|---|
| 00 | 1 |
| 01 | 2 |
| 10 | 4 |
| 11 | 8 |
$ gcc -g movq-11.s
$ objdump -d ./a.out
0000000000001129 <main>:
1129: 4c 89 05 e8 03 00 00 mov %r8,0x3e8(%rip)
1130: 4e 89 84 48 e8 03 00 mov %r8,0x3e8(%rax,%r9,2)
1137: 00

-
mov %r8, 0x3e8(%rip)の機械語バイト列を見てみます- Mod=00で,メモリ参照,変位は4バイトを意味します(これはR/M=101の時の例外).
REX.R=1とReg=000で,%r8レジスタを意味します.R/M=101で,%rip相対アドレッシングを意味します.89はmovqのオペコードです. 処理方向ビットが0なのでRegをR/Mに代入を意味します.- 最後の4バイト (
E8 03 00 00)は4バイトの変位です.

-
movq %r8, 0x3e8(%rax,%r9,2)の機械語バイト列を見てみます- Mod=10で,メモリ参照,変位は4バイトを意味します.
REX.R=1とReg=000で,%r8レジスタを意味します.- R/M=100で,SIBバイトの使用を意味します.
- Scale=01で,
0x3e8(%rax,%r9,2)の2を意味します. REX.B=0とBase=000で,Indexレジスタとして%raxを使用します.REX.X=1とIndex=001で,Baseレジスタとして%r9を使用します.
-
SIBバイトのBaseフィールドは
REX.BとともにBaseレジスタを指定します. ただし,❶❷の部分が特別扱いです.- ❶❷の101かつMod=00の場合,
(%rbp)というメモリアクセスではなく, 32ビットの変位のみでのメモリアクセスになります. - 例えば,
movq %r8,0x1000の機械語バイト列は4c 89 04 25 00 10 00 00になります. Mod=00, Base=101となっていますね.
- ❶❷の101かつMod=00の場合,
REX.B | Base | 指定される Baseレジスタ |
|---|---|---|
| 0 | 000 | %rax |
| 0 | 001 | %rcx |
| 0 | 010 | %rdx |
| 0 | 011 | %rbx |
| 0 | 100 | %rsp |
| 0 | ❶101 | %rbp,Mod=00の時は4バイトの変位のみ |
| 0 | 110 | %rsi |
| 0 | 111 | %rdi |
| 1 | 000 | %r8 |
| 1 | 001 | %r9 |
| 1 | 010 | %r10 |
| 1 | 011 | %r11 |
| 1 | 100 | %r12 |
| 1 | ❷101 | %r13,Mod=00の時は4バイトの変位のみ |
| 1 | 110 | %r14 |
| 1 | 111 | %r15 |
-
SIBバイトのIndexフィールドは
REX.Xと合わせて,Indexレジスタを指定します.- ただし%rspは指定不可です
REX.X | Index | Reg |
|---|---|---|
| 0 | 000 | %rax |
| 0 | 001 | %rcx |
| 0 | 010 | %rdx |
| 0 | 011 | %rbx |
| 0 | 100 | 無し(%rspは使用不可) |
| 0 | 101 | %rbp |
| 0 | 110 | %rsi |
| 0 | 111 | %rdi |
| 1 | 000 | %r8 |
| 1 | 001 | %r9 |
| 1 | 010 | %r10 |
| 1 | 011 | %r11 |
| 1 | 100 | %r12 |
| 1 | 101 | %r13 |
| 1 | 110 | %r14 |
| 1 | 111 | %r15 |
データの変換
ゼロ拡張
- ゼロ拡張 (zero extension)は上位ビットを0で埋めてビット列を大きくする変換.
- 符号なし整数をゼロ拡張すると,値は変化しない.
- 例: 2バイトの符号なし整数65535をゼロ拡張で4バイトに変換しても,値は変化しない.
| データサイズ | ビット表現 | 値 |
|---|---|---|
| 2バイト | 11111111 11111111 | 65535 |
| 4バイト | 00000000 00000000 11111111 11111111 | 65535 |
符号拡張
- 符号拡張 (sign extension)は
- 上位ビットを元データのMSBで埋めてビット列を大きくする変換.
- つまり,正の場合は0を,負の場合は1を上位ビットに埋める.
- 符号あり整数を符号拡張すると,値は変化しない.
| データサイズ | ビット表現 | 値 |
|---|---|---|
| 2バイト | 01111111 11111111 | 32767 |
| 4バイト | 00000000 00000000 01111111 11111111 | 32767 |
| データサイズ | ビット表現 | 値 |
|---|---|---|
| 2バイト | 11111111 11111111 | -1 |
| 4バイト | 11111111 11111111 11111111 11111111 | -1 |
- 符号あり整数をゼロ拡張すると,値が変化する.
| データサイズ | ビット表現 | 値 |
|---|---|---|
| 2バイト | 11111111 11111111 | -1 |
| 4バイト | 00000000 00000000 11111111 11111111 | 65535 |
movz␣␣,movs␣␣命令
movz␣␣はゼロ拡張をしてデータをコピーする命令 (move with zero extension)movs␣␣は符号拡張をしてデータをコピーする命令 (move with sign extension)- 通常,値を変化させたくないので,符号なし整数には
movz␣␣を使い, 符号あり整数にはmovs␣␣命令を使う.
切り詰め (truncation)
- 切り詰め = 上位ビットを捨ててビット列を小さくする変換
- 符号あり整数を切り詰めると,正負が変わることがある
| データサイズ | ビット表現 | 値 |
|---|---|---|
| 4バイト | 00000000 00000001 10000110 10100000 | 100000 |
| 2バイト | 10000110 10100000 | -31072 |
#include <stdio.h>
#include <stdint.h>
int main (void)
{
int32_t i = 100000;
int16_t s = i;
printf ("%d\n", s);
}
$ gcc -g trunc.c
$ ./a.out
-31072
- 4バイトから2バイトへ切り詰めは,
例えば,
%eaxに値を入れて,%axで値を取り出せば可能.
# asm/trunc2.s
.text
.globl main
.type main, @function
main:
movl $100000, %eax
movw %ax, %bx
ret
.size main, .-main
$ gcc -g trunc2.s
$ gdb ./a.out -x trunc2.txt
Breakpoint 1 at 0x1131: file trunc2.s, line 8.
Breakpoint 1, main () at trunc2.s:8
8 ret
$1 = -31072
# -31072 が出力されれば成功
メモリレイアウト
多バイト長データはメモリの連続領域に格納

- 通常,メモリはバイトアドレッシングです. つまり,1つの番地ごとに1バイトの情報を格納できます.
- 多バイト長データ(2バイト以上のデータ)をメモリに格納する時は,
メモリの連続領域を使ってデータを格納します.
- 上図では4バイトのデータ
0x11223344をメモリの1000〜1003番地を使って格納していることを示しています. - このデータを読み書きする場合は,先頭番地の1000番地を使います.
- 上図では4バイトのデータ
バイトオーダとエンディアン
-
多バイト長のデータをメモリに格納するには1バイトごとに分割して格納します. 多バイト長のデータをバイト単位で格納する順序をバイトオーダ(byte order)といいます.
-
多バイト長データで最下位のバイトをLeast Significant Byte (LSB), 最上位のバイトをMost Significant Byte (MSB)と呼びます.
- 例えば,
0x11223344という4バイトのデータのLSBは0x44,MSBは0x11です.
- 例えば,
-
多バイト長データをメモリに格納する時,
- LSBから先にメモリに格納する方法をリトルエンディアン(little endian)
- MSBから先にメモリに格納する方法をビッグエンディアン (big endian) と呼びます.
- LSBから先にメモリに格納する方法を

エンディアンの由来とは
エンディアン(endian)という言葉はガリバー旅行記から来ています. お話の中で,卵の殻は尖った方からむくべき派 (little endian)と 丸い方からむくべき派 (big endian)が争うのです.なのでインディアンとは何の関係もありません.
アラインメントとパディング
アラインメント
| 型 | アラインメント制約 |
|---|---|
| 1バイト整数 | 1の倍数のアドレス |
| 2バイト整数 | 2の倍数のアドレス |
| 4バイト整数 | 4の倍数のアドレス |
| 8バイト整数 | 8の倍数のアドレス |
| ポインタ(8バイト長) | 8の倍数のアドレス |
| 16バイト整数 | 16の倍数のアドレス |
| スタックフレーム | 16の倍数のアドレス |
- アラインメント (境界調整,alignment)とは,
特定のアドレス(例: 16の倍数のアドレス)にデータを格納することです
- 16の倍数のアドレスに格納することを, 16バイト境界 (16-byte boundary)に格納する,という言い方もします.
- ABIはアラインメントを守ることを
プログラムに要求します.このお約束をアラインメント制約といいます.
上の表は System V ABI (AMD64)
が定めるアラインメント制約です.
- スタックフレームの16バイト境界への制約は
call命令実行時に%rspの値が16の倍数であることを要求しています.
- スタックフレームの16バイト境界への制約は
アラインメント制約に違反すると最悪,クラッシュする
- アラインメント制約に違反すると,実行速度が遅くなったり,
Segmentation faultなどの実行時エラーが生じます(例: AVX命令の
movdqa). このため,コンパイラはアラインメント制約を満たすコードを出力します. 人手でアセンブリコードを書く場合は, プログラマがアラインメント制約を守るよう注意する必要があります.
アラインメント調整 (.align)とパディング
-
アラインメント制約はアセンブラ命令
.alignを使って満たせます (他にも.skip,.space,.zeroなどのアセンブラ命令でも可能です).char x1 = 10; int x2 = 20;.globl x1 .data .type x1, @object .size x1, 1 x1: .byte 10 .globl x2 ❶.align 4 .type x2, @object .size x2, 4 x2: .long 20
- 例えば,上の
char型のx1とint型のx2というグローバル変数の宣言があった場合,コンパイラは上のようなアセンブリコードを出力します. - 仮に
x1を1000番地に配置したとすると,そのまま次の領域にx2を配置するとx2は1001番地に配置することになります. 1001番地は4バイト境界(4の倍数のアドレス) ではないのでアラインメント制約違反になってしまいます. - これを避けるため❶
.align 4というアセンブラ命令を使用します..align 4は「次に出力するアドレスを4の倍数になるよう(最小限増やして)調整しろ」という意味です.その結果,x2のアドレスは1004番地になります. - なお未使用の1001〜1003番地のメモリ領域のことをパディング(詰め物,padding)といいます.
- 例えば,上の
構造体のパディング
// asm/struct3.c
struct foo {
char x1;
int x2;
};
struct foo f = {10, 20};
.globl f
.data
.align 8 # 構造体全体を8バイト境界に配置
.type f, @object
.size f, 8
f:
.byte 10 # f.x1
.zero 3 # 3バイトのゼロを出力(3バイトのパディング)
.long 20 # f.x2

- アラインメント制約のために,構造体の中にもパディングが生じます
- 上の例では
char型のx1とint型のx2の間に3バイトのパディングができています - 構造体の先頭にパディングが入ることはありません. 一方,構造体の末尾にパディングが入ることはあります(次の節で説明)
配列のためのパディング
-
(構造体にはパディングが生じますが)配列にはパディングは入りません. 配列のすべての要素は常にぴったりくっついて, メモリ上で連続したアドレスに格納されます. 例えば,
int a1 [3];のメモリレイアウトは以下の図になります. (配列の各要素(ここではint)もアラインメント制約を満たしています (ここではアドレスが4の倍数になっています))
-
これは2次元配列になっても同じです. 例えば,
int a2 [2][3];のメモリレイアウトは(C言語では)以下の図になります.
-
「じゃあ,サイズが5バイトの構造体を作って,その構造体の配列を定義したら, その配列の要素はアラインメント制約を満たせないのでは?」
答えは「はい,満たせなくなります.ですので,(構造体中に
int型など アラインメント制約を持つメンバーがある場合は)サイズが5バイトの構造体は作れません」「その場合は構造体のお尻にパディングが入ります」. (なお構造体のメンバーがcharやchar[]など,どの場所にも置けるデータのみの 場合は5バイトの構造体を作れます).
// asm/struct4.c
#include <stdio.h>
struct foo2 {
int x2;
char x1;
};
struct foo2 f = {10, 20};
int main ()
{
printf ("%ld\n", sizeof (struct foo2));
}
.globl f
.data
.align 8
.type f, @object
.size f, 8 # 構造体全体のサイズは8バイト
f:
.long 10
.byte 20
.zero 3 # 構造体のお尻に3バイトのパディングが入っている

実際にやってみると,構造体のお尻に3バイトのパディングが入りました.
x86-64機械語命令
x86-64機械語命令の実行方法
概要:デバッガ上で実行します
機械語命令を実行しても,単にa.outを実行するだけでは
意図通りに実行できたかの確認が難しいです.
(アセンブリコード内からprintfを呼び出せばいいのですが,
そのコードもうざいので).
そこで本書ではデバッガを使って機械語命令の実行と確認を行います.
以下では例としてmovq $999, %raxという機械語命令を実行してみます.
(これらのファイルはサンプルコードから入手できます).
movq $999, %raxは「定数999を%raxレジスタに格納する」という命令ですので,
実行後,%raxレジスタに999という値が入っていれば,
うまく実行できたことを確認できます.
# asm/movq-4.s
.text
.globl main
.type main, @function
main:
movq $999, %rax
ret
.size main, .-main
実行確認のためのgdbのコマンド列を書いたファイルも用意しています.
# asm/movq-4.txt
b 7
r
list 6,6
p $rax
echo # %raxの値が999なら成功\n
quit
デバッガ上で実行:gdbコマンドを手入力
asm/movq-4.txt中のgdbコマンドを
以下のように1行ずつ入力してみて下さい.
(この章でもgdbの使い方を説明していきますが,
gdbの使い方の詳細はデバッガgdbの使い方にもまとめてあります).
$ gcc -g movq-4.s
$ gdb ./a.out ❶
(gdb) b 7 ❷
Breakpoint 1 at 0x1130: file movq-4.s, line 6.
(gdb) r ❸
Breakpoint 1, main () at movq-4.s:6
6 ret
(gdb) list 6,6 ❹
5 movq $999, %rax
(gdb) p $rax ❺
$1 = 999
(gdb) quit
- ❶ コンパイルした
a.outをgdb上で実行 - ❷ ブレークポイントを7行目(
movq $999, %raxの次の行)に設定 (bはbreakの略) - ❸ 実行開始 (
rは run の略) - ❹ ソースコードの6行目だけを表示
- ❺ レジスタ
%raxの値を(10進表記で)表示 (pはprintの略) movq-4.txtの最後の行echo # %raxの値が999なら成功\nは, 「どうなると正しく実行できたか」を確認するメッセージを出力するコマンドですので, ここでは入力不要です. ❺の結果と一致したので「正しい実行」と確認できました.
デバッガ上で実行:gdbコマンドを自動入力 (-xオプションを使う)
gdbコマンドを手入力して,よく使うgdbコマンドを覚えることは良いことです.
とはいえ,手入力は面倒なので,自動入力も使いましょう.
$ gcc -g movq-4.s
$ gdb ./a.out ❶ -x movq-4.txt
Breakpoint 1, main () at movq-4.s:7
7 ret
6 ❷ movq $999, %rax
❸ $1 = 999
❹ # %raxの値が999なら成功
(gdb)
- ❶
-x movq-4.txtというオプションをつけると,指定したファイル(ここではmovq-4.txt)の中に書かれているgdbコマンドを1行ずつ順番に実行してくれます list 6,6を実行した結果,❷6行目のmovq $999, %raxが表示されていますp $raxを実行した結果,%raxレジスタの値が❸999であると表示されています. ($1はgdbが扱う変数です.ここでは無視して下さい)echo # %raxの値が999なら成功\nをgdbが実行した結果, ❹# %raxの値が999なら成功というメッセージが表示されています. このメッセージと❸の実行結果を見比べれば「実行結果が正しい」ことを確認できます.
デバッガ上で実行:gdbコマンドを自動入力 (sourceコマンドを使う)
$ gcc -g movq-4.s
$ gdb ./a.out
(gdb) ❶ source movq-4.txt
Breakpoint 1, main () at movq-4.s:7
7 ret
6 movq $999, %rax
$1 = 999
# %raxの値が999なら成功
gdbは通常通りに実行開始して,
❶ sourceコマンドを使えば,movq-4.txt中のgdbコマンドを実行できます.
-xオプションとsourceコマンドは好きな方を使って下さい.
アドレッシングモード (オペランドの表記方法)
アドレッシングモードの概要
機械語命令は命令(オペコード(opcode))と
その引数のオペランド(operand)から構成されています.
例えば,movq $999, %raxという命令では,
movqがオペコードで,$999と%raxがオペランドです.

アドレッシングモードとはオペランドの書き方のことです. (元々は「メモリのアドレスを指定する記法」という意味で「アドレッシングモード」という用語が使われています). x86-64では大きく,以下の4種類の書き方ができます.
| アドレッシング モードの種類 | オペランドの値 | 例 |
|---|---|---|
| 定数の値 | movq $0x100, %rax | |
movq $foo, %rax | ||
|
|
レジスタの値 | movq %rbx, %rax |
| 定数で指定した アドレスのメモリ値 | movq 0x100, %rax | |
movq foo, %rax | ||
| レジスタ等で計算した アドレスのメモリ値 | movq (%rsp), %rax | |
movq 8(%rsp), %rax | ||
movq foo(%rip), %rax |
fooはラベル(その値はアドレス)であり,定数と同じ扱い.(定数を書ける場所にはラベルも書ける).- メモリ参照では例えば
-8(%rbp, %rax, 8)など複雑なオペランドも指定可能. 参照するメモリのアドレスは-8+%rbp+%rax*8になる. (以下を参照).
アドレッシングモード:即値(定数)
定数 $999
即値(immediate value,定数)には$をつけます.
例えば$999は定数999を意味します.
# asm/movq-4.s
.text
.globl main
.type main, @function
main:
movq $999, %rax
ret
.size main, .-main
movq-4.sの6行目の
movq $999, %raxは「定数999をレジスタ%raxに格納する」という意味です.
デバッガで動作を確認します
(デバッガの操作手順はmovq-4.txtにもあります).
$ gcc -g movq-4.s
$ gdb ./a.out
(gdb) b main
Breakpoint 1 at 0x1129: file movq-4.s, line 6.
(gdb) r
Breakpoint 1, main () at movq-4.s:6
6 movq $999, %rax
(gdb) si
main () at movq-4.s:7
7 ret
(gdb) p $rax
$1 = 999
確かに%raxレジスタ中に999が格納されていました.
なお,多くの場合,即値は32ビットまでで,オペランドのサイズが64ビットの場合,
32ビットの即値は,64ビットの演算前に
64ビットに符号拡張 されます
(ゼロ拡張だと
負の値が大きな正の値になって困るからです).
64ビットに符号拡張される例はこちら
を見て下さい.
例外はmovq命令で,64ビットの即値を扱えます.
実行例はこちらを見て下さい.
ラベル $main
定数が書ける場所にはラベル(その値はアドレス)も書けます.
ラベルは関数名やグローバル変数の実体があるメモリの先頭番地を
示すために使われます(それ以外にはジャンプのジャンプ先としても使われます).
ですので,main関数の先頭番地を示すmainというラベルが
main関数をコンパイルしたアセンブリコード中に存在します.
# asm/movq-6.s
.text
.globl main
.type main, @function
main:
movq $main, %rax
ret
.size main, .-main
movq-6.sの6行目のmovq $main, %raxは
「ラベルmainが表すアドレスを%raxレジスタに格納する」という意味です.
gdbで確かめます.
$ gcc ❶ -no-pie -g movq-6.s
$ gdb ./a.out
(gdb) b main
Breakpoint 1 at ❷ 0x40110a: file movq-6.s, line 7.
(gdb) r
Breakpoint 1, main () at movq-6.s:7
7 ❸ movq $main, %rax
(gdb) ❹ si
main () at movq-6.s:8
8 ret
(gdb) p/x $rax
$1 = ❺ 0x40110a
- まず❶
-no-pieオプションをつけてコンパイルして下さい. (-staticオプションを使ってもうまくいくと思います)
なぜ -no-pieオプション
-no-pieオプションをつけないと以下のエラーが出てしまうからです.
$ gcc -g movq-6.s
/usr/bin/ld: /tmp/ccqHsPbg.o: relocation R_X86_64_32S against symbol `main' can not be used when making a PIE object; recompile with -fPIE
/usr/bin/ld: failed to set dynamic section sizes: bad value
collect2: error: ld returned 1 exit status
-no-pieは「位置独立実行可能ファイル
(PIEの説明1,PIEの説明2)を生成しない」
というオプションです.
最近のLinuxのgccでは,PIEがデフォルトで有効になっている事が多いです.
PIC(位置独立コード)やPIEは「再配置(アドレス調整)無しに
どのメモリ番地に配置しても,そのまま実行可能」という機械語命令列です.
そのため,PIEやPICのメモリ参照では絶対アドレス(absolute address)が使えません.
-no-pieオプションが無いと,
アセンブラはmovq $main, %raxという命令中のmainというラベルを
「絶対アドレスだ」と解釈してエラーにするようです.
絶対アドレス,相対アドレスとは

絶対アドレスとは「メモリの先頭0番地から何バイト目か」で示すアドレスです.
上図で青色のメモリ位置の絶対アドレスは0x1000番地となります.
一方,相対アドレス(relative address)は(0番地ではなく)別の何かを起点とした差分のアドレスです.
x86-64では%ripレジスタ(プログラムカウンタ)を起点とすることが多いです.
上図では青色のメモリ位置の相対アドレスは
%ripを起点とすると,-0x500番地となります(0x1000 - 0x1500 = -0x500).
また,相対アドレスに起点のアドレスを足すと絶対アドレスになります
(-0x500 + 0x1500 = 0x1000).
なぜ PICやPIEで絶対アドレスが使えないかと言うと, 機械語命令列を何番地に置くかで,絶対アドレスが変化してしまうからです.
もうちょっと具体的に
例えば,movq $main, %raxという命令は
main関数のアドレスを%raxレジスタに格納するわけですが,
このアドレスが絶対アドレスの場合,出力される機械語命令に
絶対アドレスが埋め込まれてしまいます.
$ gcc -no-pie -g movq-6.s
$ objdump -d ./a.out
(一部略)
000000000040110a <main>:
40110a: 48 c7 c0 ❷ 0a 11 40 00 mov ❶$0x40110a,%rax
401111: c3 ret
上の逆アセンブル結果を見ると,確かにmain関数のアドレス❶ 0x40110aが
機械語命令列に❷埋め込まれています.
(x86-64はリトルエンディアンなので,バイトの並びが逆順に見えることに注意).
相対アドレスだと大丈夫なことも見てみます.
leaq-1.s中の
leaq main(%rip), %raxは,
「%ripを起点としたmainの相対アドレスと,
%ripの値との和を%raxレジスタに格納する」という命令です.
(lea は load effective address の略です.effective addressは日本語では実効アドレスです).
# asm/leaq-1.s
.text
.globl main
.type main, @function
main:
leaq main(%rip), %rax
ret
.size main, .-main
$ gcc -g leaq-1.s
$ objdump -d ./a.out
(一部略)
0000000000001129 <main>:
❶ 1129: 48 8d 05 ❸ f9 ff ff ff lea ❷ -0x7(%rip),%rax # 1129 <main>
❹ 1130: c3 ret
上のように逆アセンブルすると以下が分かります.
main関数の(ファイルa.out中での)アドレスは❶0x1129番地leaq main(%rip), %raxの%ripの値は❸0x1130番地 (プログラムカウンタ%ripは「次に実行する機械語命令のアドレス」を保持しています).- 機械語命令に埋め込まれているアドレスは相対アドレスで,
❶
0x1129- ❸0x1130= ❷-0x7= ❸0xFFFFFFF9です.
❶ 0x1129 や ❹ 0x1130 のアドレスは,
main関数がどのアドレスに配置されるかで変化します.
しかし,この相対アドレス❷ -0x7 は
main関数がどのアドレスに配置されても変化しないので,
この機械語命令はPICやPIEとして使えるわけです.
❷ -0x7 が ❸ 0xFFFFFFF9 として埋め込まれているのは,
2の補数表現だからですね
なお,相対アドレスが固定にならない場合(例えば,printf関数のアドレス)もあります.
その場合はGOTやPLTを使います.
printf関数のアドレスを機械語命令列(.textセクション)に埋め込むのではなく,
別の書込み可能なセクション(例:gotセクション)に格納し,
そのアドレスを使って間接コール(indirect call)するのです.
-staticオプションとは
-staticオプションは(動的リンクではなく)
静的リンク
せよという,gccへの指示になります.
-
main関数の先頭にブレークポイントを設定します.main関数の先頭アドレスが❷0x40110aと分かります. -
❸
movq $main, %raxの実行直前で止まっているので, ❹siで1命令実行を進めます. -
❺
%raxレジスタ中にmain関数のアドレス❷0x40110aが入っていました.
アドレッシングモード:レジスタ参照
# asm/movq-1.s
.text
.globl main
.type main, @function
main:
movq $999, %rax
movq %rax, %rbx
ret
.size main, .-main
movq-1.s中のmovq %rax, %rbxは
「%raxレジスタ中の値を%rbxに格納する」という意味です.
$ gcc -g movq-1.s
$ gdb ./a.out
(gdb) b main
Breakpoint 1 at 0x1129: file movq-1.s, line 6.
(gdb) r
Breakpoint 1, main () at movq-1.s:6
6 ❶ movq $999, %rax
(gdb) si
7 ❷ movq %rax, %rbx
(gdb) si
main () at movq-1.s:8
8 ret
(gdb) p $rax
$1 = ❸ 999
(gdb) p $rbx
$2 = ❹ 999
gdb上での実行で,❶ 定数999が%raxに格納され,
❷ %rax中の999がさらに%rbxに格納されたことを
❸❹確認できました.
アドレッシングモード:直接メモリ参照
直接メモリ参照はアクセスするメモリ番地が定数となるメモリ参照です.
以下の例ではラベルxを使ってメモリ参照していますが,
これは直接メモリ参照になります.
アセンブル時に(つまり実行する前に)アドレスが具体的に(以下では0x404028番地)と決まるからです.
# asm/movq-7.s
.data
x:
.quad 999
.text
.globl main
.type main, @function
main:
movq x, %rax
ret
.size main, .-main
$ gcc -g -no-pie movq-7.s
$ gdb ./a.out -x movq-7.txt
Breakpoint 1, main () at movq-7.s:10
10 ret
9 movq x, %rax
$1 = ❶ 999
# %raxの値が999なら成功
以下の図で0x401106<main>は「ラベルmainが示すアドレスは0x401106番地」
「ラベルxが示すアドレスは0x404028番地」であることを示してます.

そしてmovq-7.s中の以下の3行で,以下は
.data
x:
.quad 999
「.dataセクションにサイズが8バイトのデータとして値999を配置せよ」
「そのデータの先頭アドレスをラベルxとして定義せよ」を意味しています
(quadが8バイトを意味しています).
ですので,実行時には上図のように
「.dataセクションのある場所(上図では0x404028番地)に値999が入っていて,
ラベルxの値は0x404028」となっています.
ですので,movq-7.s中のmovq x, %raxは
「ラベルxが表すアドレス(上図では0x404028番地)のメモリの中身(上図では999)
を%raxレジスタにコピーせよ」を意味します.
実行するとmovq x, %raxの実行で,x中の999が%raxレジスタに
コピーされたことを確認できました❶.
ここで$マークの有無,つまりxと$xの違いに注意しましょう
(上図も参照).
movq x, %rax # x はメモリの中身を表す
movq $x, %rax # $x はアドレスを表す
以下のようにmovq $x, %raxを実行すると,
%raxレジスタにはアドレス(ここでは0x404028番地)が
入っていることを確認できました❷.
-8(%rbp)の-8には(定数なのに)$マークが付かない
以下でも説明しますが,
例えば-8(%rbp)とオペランドに書いた時,-8は($マークが無いのに)
定数として扱われます.
そして,-8(%rbp)は,%rbp - 8の計算結果をアドレスとするメモリの中身を意味します.
ちなみにこの-8のことは
Intelのマニュアルでは変位 (displacement)と呼ばれています.
つまり「変位は定数だけど$マークはつきません」.
# asm/movq-8.s
.data
x:
.quad 999
.text
.globl main
.type main, @function
main:
movq $x, %rax
ret
.size main, .-main
$ gcc -g -no-pie movq-8.s
$ gdb ./a.out -x movq-8.txt
Breakpoint 1, main () at movq-8.s:10
10 ret
9 movq $x, %rax
$1 = 0x404028 ❷
nm ./a.out | egrep 'd x'
0000000000404028 d x
# %raxの値と nmコマンドによるxのアドレスが一致すれば成功
ちなみに,xのアドレスが0x404028になると分かっていれば,
movq x, %rax # これと
movq 0x404028, %rax # これは同じ意味
上の2行は全く同じ意味(0x404028番地のメモリの中身)になります.
しかし,何番地になるか事前に分からないのが普通なので,
通常はラベル(ここではx)を使います.
アドレッシングモード:間接メモリ参照
間接メモリ参照はアクセスするメモリ番地が変数となるメモリ参照です. アセンブリ言語では変数という概念は無いので, 正確には「実行時に決まるレジスタの値を使って, 参照先のメモリアドレスを計算して決める」という参照方式です. 以下では3つの例が出てきます(以下でより複雑な間接メモリ参照を説明します).
| 間接メモリ参照 | 計算するアドレス |
|---|---|
(%rsp) | %rsp |
8(%rsp) | %rsp + 8 |
foo(%rip) | %rip + foo |

以下のmovq-9.sをpushq $777まで実行すると,
メモリの状態は上図のようになっています.
(%rspが指す777のひとつ下のアドレスが%rsp+8なのは,
pushq $777命令が「サイズが8バイトの値777をスタックにプッシュしたから」です).
# asm/movq-9.s
.data
foo:
.quad 999
.text
.globl main
.type main, @function
main:
pushq $888
pushq $777
movq (%rsp), %rax
movq 8(%rsp), %rbx
movq foo(%rip), %rcx
ret
.size main, .-main
(%rsp)は「アドレスが%rspの値のメモリ」なので値777が入っている部分を参照します8(%rsp)は「アドレスが%rsp + 8の値のメモリ」なので値888が入っている部分を参照しますfoo(%rip)はちょっと特殊です.この形式は%rip相対アドレッシング といいます. この形式の時,ラベルfooの値はプログラムカウンタ%rip中のアドレスを起点とした 相対アドレス になります.ですので,%rip + fooはfooの 絶対アドレス になるので,foo(%rip)はラベルfooのメモリ部分,つまり999が入っている部分になります.
gdbでの実行結果
$ gcc -g movq-9.s
$ gdb ./a.out -x movq-9.txt
Breakpoint 1, main () at movq-9.s:14
14 ret
11 movq (%rsp), %rax
12 movq 8(%rsp), %rbx
13 movq foo(%rip), %rcx
$1 = 777
$2 = 888
$3 = 999
# 777, 888, 999なら成功
メモリ参照の一般形
前節では,
(%rsp),8(%rsp),foo(%rip)という間接メモリ参照の例を説明しました.
ここではメモリ参照の一般形を説明します.
以下がx86-64のメモリ参照の形式です.
| AT&T形式 | Intel形式 | 計算されるアドレス | |
|---|---|---|---|
| 通常のメモリ参照 | disp (base, index, scale) | [base + index * scale + disp] | base + index * scale + disp |
%rip相対参照 | disp (%rip) | [rip + disp] | %rip + disp |
「segment: メモリ参照」という形式
実は「segment: メモリ参照」という形式もあるのですが, あまり使わないので,ここでは省いて説明します. 興味のある人はこちらを参照下さい.
disp (base, index, scale)
でアクセスするメモリのアドレスは
base + index * scale + disp で計算します.
disp(%rip)でアクセスするメモリのアドレスは
disp + %ripで計算します.
disp,base,index,scaleとして指定可能なものは次の節で説明します.
メモリ参照で可能な組み合わせ(64ビットモードの場合)
通常のメモリ参照
通常のメモリ参照では,disp,base,index,scaleに以下を指定できます.

- disp には符号あり定数を指定する.ただし「64ビット定数」は無いことに注意. アドレス計算時に64ビット長に符号拡張される. dispは変位(displacement)を意味する.
- base には上記のいずれかのレジスタを指定可能.省略も可.
- index には上記のいずれかのレジスタを指定可能.省略も可.
%rspを指定できないことに注意. - scale を省略すると
1と同じ
注: dispの例外.
mov␣命令のみ,64ビットのdispを指定可能. この場合,movabs␣というニモニックを使用可能. (absはおそらく絶対アドレス absolute address から). メモリ参照はdispのみで,base,index,scaleは指定不可. 他方のオペランドは%raxのみ指定可能.movq 0x1122334455667788, %rax movabsq 0x1122334455667788, %rax movq %rax, 0x1122334455667788 movabsq %rax, 0x1122334455667788
%rip相対参照

%rip相対参照では32ビットのdispと%ripレジスタのみが指定可能です.
メモリ参照の例
以下がメモリ参照の例です.
| AT&T形式 | Intel形式 | 指定したもの | 計算するアドレス |
|---|---|---|---|
8 | [8] | disp | 8 |
foo | [foo] | disp | foo |
(%rbp) | [rbp] | base | %rbp |
8(%rbp) | [rbp+8] | dispとbase | %rbp + 8 |
foo(%rbp) | [rbp+foo] | dispとbase | %rbp + foo |
8(%rbp,%rax) | [rbp+rax+8] | dispとbaseとindex | %rbp + %rax + 8 |
8(%rbp,%rax, 2) | [rbp+rax*2+8] | dispとbaseとindexとscale | %rbp + %rax*2 + 8 |
(%rip) | [rip] | base | %rip |
8(%rip) | [rip+8] | dispとbase | %rip + 8 |
foo(%rip) | [rip+foo] | dispとbase | %rip + foo |
%fs:-4 | fs:[-4] | segmentとdisp | %fsのベースレジスタ - 4 |
なんでこんな複雑なアドレッシングモード?
x86-64はRISCではなくCISCなので「よく使う1つの命令で複雑な処理が
できれば,それは善」という思想だからです(知らんけど).
例えば,以下のCコードの配列array[i]へのアクセスはアセンブリコードで
movl (%rdi,%rsi,4), %eaxの1命令で済みます.
(ここではsizeof(int)が4なので,scaleが4になっています.
配列の先頭アドレスがarrayの,i番目の要素のアドレスは,
array + i * sizeof(int)で計算できることを思い出しましょう.
なお,array.sの出力を得るには,gcc -S -O2 array.cとして下さい.
私の環境では-O2が無いとgccは冗長なコードを吐きましたので).
// array.c
int foo (int array [], int i)
{
return array [i];
}
.text
.p2align 4
.globl foo
.type foo, @function
foo:
endbr64
movslq %esi, %rsi
movl (%rdi,%rsi,4), %eax
ret
.size foo, .-foo
オペランドの表記方法
以下の機械語命令の説明で使う記法を説明します. この記法はその命令に許されるオペランドの形式を表します.
オペランド,即値(定数)
| 記法 | 例 | 説明 |
|---|---|---|
| op1 | 第1オペランド | |
| op2 | 第2オペランド | |
| imm | $100 | imm8, imm16, imm32のどれか |
$foo | ||
| imm8 | $100 | 8ビットの即値(定数) |
| imm16 | $100 | 16ビットの即値(定数) |
| imm32 | $100 | 32ビットの即値(定数) |
- 多くの場合,サイズを省略して単にimmと書きます. 特にサイズに注意が必要な時だけ,imm32などとサイズを明記します.
- 一部例外を除き, x86-64では64ビットの即値を書けません(32ビットまでです).
汎用レジスタ
| 記法 | 例 | 説明 |
|---|---|---|
| r | %rax | r8, r16, r32, r64のどれか |
| r8 | %al | 8ビットの汎用レジスタ |
| r16 | %ax | 16ビットの汎用レジスタ |
| r32 | %eax | 32ビットの汎用レジスタ |
| r64 | %rax | 64ビットの汎用レジスタ |
メモリ参照
| 記法 | 例 | 説明 |
|---|---|---|
| r/m | %rbp | r/m8, r/m16, r/m32, r/m32, r/m64のどれか |
100 | ||
-8(%rbp) | ||
foo(%rbp) | ||
| r/m8 | -8(%rbp) | r8 または 8ビットのメモリ参照 |
| r/m16 | -8(%rbp) | r16 また は16ビットのメモリ参照 |
| r/m32 | -8(%rbp) | r32 また は32ビットのメモリ参照 |
| r/m64 | -8(%rbp) | r64 また は64ビットのメモリ参照 |
| m | -8(%rbp) | メモリ参照 |
x86-64機械語命令:転送など
nop命令: 何もしない
nopは転送命令ではありませんが,最も簡単な命令ですので最初に説明します.
| 記法 | 何の略か | 動作 |
|---|---|---|
nop | no operation | 何もしない(プログラムカウンタのみ増加) |
nop op1 | no operation | 何もしない(プログラムカウンタのみ増加) |
nopは何もしない命令です(ただしプログラムカウンタ%ripは増加します). フラグも変化しません.- 機械語命令列の間を(何もせずに)埋めるために使います.
nopの機械語命令は1バイト長です. (なのでどんな長さの隙間にも埋められます).nopr/m という形式の命令は2〜9バイト長のnop命令になります. 1バイト長のnopを9個並べるより, 9バイト長のnopを1個並べた方が,実行が早くなります.- 「複数バイトの
nop命令がある」という知識は, 逆アセンブル時にnopl (%rax)などを見て「なんじゃこりゃ」とビックリしないために必要です.
mov命令: データの転送(コピー)
| 記法 | 何の略か | 動作 |
|---|---|---|
mov␣ op1, op2 | move | op1の値をop2にデータ転送(コピー) |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
mov␣ r, r/m | movq %rax, %rbx | %rbx = %rax | movq-1.s movq-1.txt |
movq %rax, -8(%rsp) | *(%rsp - 8) = %rax | movq-2.s movq-2.txt | |
mov␣ r/m, r | movq -8(%rsp), %rax | %rax = *(%rsp - 8) | movq-3.s movq-3.txt |
mov␣ imm, r | movq $999, %rax | %rax = 999 | movq-4.s movq-4.txt |
mov␣ imm, r/m | movq $999, -8(%rsp) | *(%rsp - 8) = 999 | movq-5.s movq-5.txt |
mov命令は第1オペランドの値を第2オペランドに転送(コピー)します. 例えば,movq %rax, %rbxは「%raxの値を%rbxにコピー」することを意味します.
movq-1.sの実行例
$ gcc -g movq-1.s
$ gdb ./a.out -x movq-1.txt
Breakpoint 1, main () at movq-1.s:8
8 ret
7 movq %rax, %rbx
# p $rbx
$1 = 999
# %rbxの値が999なら成功
movq-2.sの実行例
$ gcc -g movq-2.s
$ gdb ./a.out -x movq-2.txt
Breakpoint 1, main () at movq-2.s:8
8 ret
7 movq %rax, -8(%rsp)
# x/1gd $rsp-8
0x7fffffffde90: 999
# -8(%rsp)の値が999なら成功
-
オペランドには,即値,レジスタ,メモリ参照を組み合わせて指定できますが, メモリからメモリへの直接データ転送はできません.
-
␣には命令サフィックス (q,l,w,b)を指定します. 命令サフィックスは転送するデータのサイズを明示します (順番に,8バイト,4バイト,2バイト,1バイトを示します).movq $0x11, (%rsp)は値0x11を8バイトのデータとして(%rsp)に書き込むmovl $0x11, (%rsp)は値0x11を4バイトのデータとして(%rsp)に書き込むmovw $0x11, (%rsp)は値0x11を2バイトのデータとして(%rsp)に書き込むmovb $0x11, (%rsp)は値0x11を1バイトのデータとして(%rsp)に書き込む
機械語命令のバイト列をアセンブリコードに直書きできる
movq %rax, %rbxをコンパイルして逆アセンブルすると,
機械語命令のバイト列は48 89 C3となります.
.byteというアセンブラ命令を使うと,
アセンブラに指定したバイト列を出力できます.
例えば,次のように.byte 0x48, 0x89, 0xC3と書くと,
.textセクションに0x48, 0x89, 0xC3というバイト列を出力できます.
# asm/byte.s
.text
.globl main
.type main, @function
main:
movq %rax, %rbx # これと
.byte 0x48, 0x89, 0xC3 # これは同じ意味
ret
.size main, .-main
$ gcc -g byte.s
$ objdump -d ./a.out
(中略)
0000000000001129 <main>:
1129: ❶48 89 c3 ❸mov %rax,%rbx
112c: ❷48 89 c3 ❹mov %rax,%rbx
112f: c3 ret
コンパイルして逆アセンブルしてみると,
❷0x48, 0x89, 0xC3を出力できています.
一方,❶0x48, 0x89, 0xC3にも同じバイト列が並んでいます.
これは❸movq %rax, %rbx命令の機械語命令バイト列ですね.
さらに❷0x48, 0x89, 0xC3の逆アセンブル結果として,
❹movq %rax, %rbxとも表示されています.
つまり,アセンブラにとっては,
movq %rax, %rbxというニモニック.byte 0x48, 0x89, 0xC3というバイト列
は全く同じ意味になるのでした.
ですので,.textセクションにニモニックで機械語命令を書く代わりに,
.byteを使って直接,機械語命令のバイト列を書くことができます.
異なる機械語のバイト列で,同じ動作のmov命令がある
- 質問:
%raxの値を%rbxにコピーしたい時,movqr, r/m とmovqr/m, r のどちらを使えばいいのでしょう? - 答え: どちらを使ってもいいです.ただし,異なる機械語命令のバイト列に なることがあります.
実は0x48, 0x89, 0xC3というバイト列は,
movq r, r/m を使った時のものです.
一方,movq r/m, r という形式を使った場合は,
バイト列は 0x48, 0x8B, 0xD8になります.確かめてみましょう.
# asm/byte2.s
.text
.globl main
.type main, @function
main:
.byte 0x48, 0x89, 0xC3
.byte 0x48, 0x8B, 0xD8
ret
.size main, .-main
$ gcc -g byte2.s
$ objdump -d ./a.out
(中略)
0000000000001129 <main>:
1129: ❶48 89 c3 ❸mov %rax,%rbx
112c: ❷48 8b d8 ❹mov %rax,%rbx
112f: c3 ret
❶48 89 c3と❷48 8b d8は異なるバイト列ですが
逆アセンブル結果としては
❸mov %rax,%rbxと❹mov %rax,%rbxと,どちらも同じ結果になりました.
このように同じニモニック命令に対して,複数の機械語のバイト列が存在する時,
アセンブラは「実行が速い方」あるいは「バイト列が短い方」を適当に選んでくれます.
(そして,アセンブラが選ばない方をどうしても使いたい場合は,
.byte等を使って機械語のバイト列を直書きするしかありません).
xchg命令: オペランドの値を交換
| 記法 | 何の略か | 動作 |
|---|---|---|
xchg op1, op2 | exchange | op1 と op2 の値を交換する |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
xchg r, r/m | xchg %rax, (%rsp) | %raxと(%rsp)の値を交換する | xchg.s xchg.txt |
xchg r/m, r | xchg (%rsp), %rax | (%rsp)と%raxの値を交換する | xchg.s xchg.txt |
xchg命令はアトミックに2つのオペランドの値を交換します.(LOCKプリフィクスをつけなくてもアトミックになります)- このアトミックな動作はロックなどの同期機構を作るために使えます.
xchg.sの実行例
$ gcc -g xchg.s
$ gdb ./a.out -x xchg.txt
Breakpoint 1, main () at xchg.s:9
9 xchg %rax, (%rsp)
1: /x $rax = 0x99aabbccddeeff00
2: /x *(void **)($rsp) = 0x1122334455667788
10 xchg (%rsp), %rax
1: /x $rax = 0x1122334455667788
2: /x *(void **)($rsp) = 0x99aabbccddeeff00
11 popq %rax
1: /x $rax = 0x99aabbccddeeff00
2: /x *(void **)($rsp) = 0x1122334455667788
# 値が入れ替わっていれば成功
機械語1命令の実行はアトミックとは限らない
機械語1命令の実行はアトミックとは限りません.
例えば,inc命令(オペランドを1増やす命令)は
マニュアルによると「LOCKプリフィックスをつければアトミックに実行される」とあります.
inc命令にLOCKプリフィックスがない場合には(たまたまアトミックに実行されるかも知れませんが)
「常にアトミックである」と期待してはいけないのです(マニュアルで「アトミックだ」と明記されていない限り).
なお,incは「メモリから読んだ値に1を足して書き戻す」ため
アトミックにならない可能性がありますが,読むだけまたは書くだけでかつ,
適切にアラインメントされていれば,
そのメモリ操作はアトミックになります.
lea命令: 実効アドレスを計算
| 記法 | 何の略か | 動作 |
|---|---|---|
lea␣ op1, op2 | load effective address | op1 の実効アドレスを op2 に代入する |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
lea␣ m, r | leaq -8(%rsp, %rsi, 4), %rax | %rax=%rsp+%rsi*4-8 | leaq-2.s leaq-2.txt |
lea命令は第1オペランド(常にメモリ参照)の実効アドレスを計算して, 第2オペランドに格納します.lea命令はアドレスを計算するだけで,メモリにはアクセスしません.
leaq-2.sの実行例
$ gcc -g lea.s
$ gdb ./a.out -x lea.txt
Breakpoint 1, main () at leaq-2.s:8
8 ret
# p/x $rsp
$1 = 0x7fffffffde98
# p/x $rsi
$2 = 0x8
# p/x $rax
$3 = 0x7fffffffdeb0
# %rax == %rsp + %rsi * 4 なら成功
実効アドレスとリニアアドレスの違いは?→(ほぼ)同じ

- 実効アドレス(effective address)は
メモリ参照で
disp (base, index, scale) や disp (
%rip)から計算したアドレスのことです. - x86-64のアセンブリコード中のアドレスは論理アドレス (logical address)といい, セグメントと実効アドレスのペアとなっています. このペアをx86-64用語でfarポインタとも呼びます. (本書ではfarポインタは扱いません).
- セグメントが示すベースアドレスと実効アドレスを加えたものが リニアアドレス(linear address)です. 例えば64ビットアドレス空間だと,リニアアドレスは0番地から264-1番地 まで一直線に並ぶのでリニアアドレスと呼ばれています. リニアアドレスは仮想アドレス(virtual address)と等しくなります.
- また,x86-64では%fsと%gsを除き, セグメントが示すベースアドレスが0番地なので, 実効アドレスとリニアアドレスは等しくなります.
- リニアアドレス(仮想アドレス)はCPUのページング機構により, 物理アドレスに変換されて,最終的なメモリアクセスが行われます.
- コンパイラは加算・乗算を高速に実行するため
lea命令を使うことがあります.
例えば,
movq $4, %rax
addq %rbx, %rax
shlq $2, %rsi # 左論理シフト.2ビット左シフトすることで%rsiを4倍にしている
addq %rsi, %rax
は,%rax = %rbx + %rsi * 4 + 4という計算を4命令でしていますが,
lea命令なら以下の1命令で済みます
leaq 4(%rbx, %rsi, 4), %rax
注: 実行時間は命令ごとに異なりますので,命令数だけで 実行時間を比較することはできません.
pushとpop命令: スタックとデータ転送
| 記法 | 何の略か | 動作 |
|---|---|---|
push␣ op1 | push | op1 をスタックにプッシュ |
pop␣ op1 | pop | スタックから op1 にポップ |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
push␣ imm | pushq $999 | %rsp-=8; *(%rsp)=999 | push1.s push1.txt |
push␣ r/m16 | pushw %ax | %rsp-=2; *(%rsp)=%ax | push2.s push2.txt |
push␣ r/m64 | pushq %rax | %rsp-=8; *(%rsp)=%rax | push-pop.s push-pop.txt |
pop␣ r/m16 | popw %ax | *(%rsp)=%ax; %rsp += 2 | pop2.s pop2.txt |
pop␣ r/m64 | popq %rbx | %rbx=*(%rsp); %rsp += 8 | push-pop.s push-pop.txt |
push命令はスタックポインタ%rspを減らしてから, スタックトップ(スタックの一番上)にオペランドの値を格納します.pop命令はスタックトップの値をオペランドに格納してから, スタックポインタを増やします.- 64ビットモードでは,32ビットの
pushとpopはできません. - 抽象データ型のスタックは(スタックトップに対する)プッシュ操作とポップ操作しか
できませんが,x86-64のスタック操作はスタックトップ以外の部分にも自由にアクセス可能です(例えば,
-8(%rsp)や-8(%rbp)などへのメモリ参照で). - 一番右側の図(
popq %rbx後)で,ポップ後も%rspよりも上に古い値が残っています (0x11〜0x88).このように,ポップしてもスタック上に古い値がゴミとして残ります.
push1.sの実行例
$ gcc -g push1.s
$ gdb ./a.out -x push1.txt
Breakpoint 1, main () at push1.s:6
6 pushq $999
# p/x $rsp
$1 = 0x7fffffffde98
main () at push1.s:7
7 ret
# p/x $rsp
$2 = 0x7fffffffde90
# x/1gd $rsp
0x7fffffffde90: 999
# %rsp が8減って,(%rsp)の値が999なら成功
push2.sの実行例
$ gcc -g push2.s
$ gdb ./a.out -x push2.txt
Breakpoint 1, main () at push2.s:6
6 pushw $999
# p/x $rsp
$1 = 0x7fffffffde98
main () at push2.s:7
7 ret
# p/x $rsp
$2 = 0x7fffffffde96
# x/1hd $rsp
0x7fffffffde96: 999
# %rsp が2減って,(%rsp)の値が999なら成功
pop2.sの実行例
$ gcc -g pop2.s
$ gdb ./a.out -x pop2.txt
Breakpoint 1, main () at pop2.s:7
7 popw %ax
# p/x $rsp
$1 = 0x7fffffffde96
main () at pop2.s:8
8 ret
# p/x $rsp
$2 = 0x7fffffffde98
# p/d $ax
$3 = 999
# %rsp が2増えて,%axの値が999なら成功
push-pop.sの実行例
$ gcc -g push-pop.s
$ gdb ./a.out -x push-pop.txt
Breakpoint 1, main () at push-pop.s:8
8 pushq %rax
# p/x $rsp
$1 = 0x7fffffffde98
main () at push-pop.s:9
9 popq %rbx
# p/x $rsp
$2 = 0x7fffffffde90
# x/8bx $rsp
0x7fffffffde90: 0x88 0x77 0x66 0x55 0x44 0x33 0x22 0x11
# %rsp の値が8減って,スタックトップ8バイトが 0x88, 0x77, 0x66, 0x55, 0x44, 0x33, 0x22, 0x11なら成功
x86-64機械語命令: 算術・論理演算
概要とステータスフラグ
ここでは以下の算術・論理演算を説明します.
| 演算の種類 | 主な命令 |
|---|---|
| 算術 | add, sub, mul, div, inc, dec, neg |
| 論理 | and, or, not, xor |
| シフト | sal, sar, shl, shr, rol, ror, rcl, rcr |
| 比較 | cmp, test |
| 変換(拡張) | movs, movz, cbtw, cqto |
これらの命令のほとんどが演算の結果として, ステータスフラグ の値を変化させます. 本書ではステータスフラグの変化を以下の記法で表します.
記法の意味は以下の通りです.
| 記法 | 意味 |
|---|---|
| 空白 | フラグ値に変化なし |
| ! | フラグ値に変化あり |
| ? | フラグ値は未定義(参照禁止) |
| 0 | フラグ値はクリア(0になる) |
| 1 | フラグ値はセット(1になる) |
add命令: 足し算
| 記法 | 何の略か | 動作 |
|---|---|---|
add␣ op1, op2 | add | op1 を op2 に加える |
adc␣ op1, op2 | add with carry | op1 と CF を op2 に加える |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
add␣ imm, r/m | addq $999, %rax | %rax += 999 | add-1.s add-1.txt |
add␣ r, r/m | addq %rax, (%rsp) | *(%rsp) += %rax | add-2.s add-2.txt |
add␣ r/m, r | addq (%rsp), %rax | %rax += *(%rsp) | add-2.s add-2.txt |
adc␣ imm, r/m | adcq $999, %rax | %rax += 999 + CF | adc-1.s adc-1.txt |
adc␣ r, r/m | adcq %rax, (%rsp) | *(%rsp) += %rax + CF | adc-2.s adc-2.txt |
adc␣ r/m, r | adcq (%rsp), %rax | %rax += *(%rsp) + CF | adc-3.s adc-3.txt |
addとadcはオペランドが符号あり整数か符号なし整数かを区別せず, 両方の結果を正しく計算します.adcは例えば,多倍長整数(任意の桁数の整数)を実装する時の 「繰り上がり」の計算に便利です.
add-1.sの実行例
$ gcc -g add-1.s
$ gdb ./a.out -x add-1.txt
Breakpoint 1, main () at add-1.s:8
8 ret
# p $rax
$1 = 1000
# %raxが1000なら成功
add-2.sの実行例
$ gcc -g add-2.s
$ gdb ./a.out -x add-2.txt
Breakpoint 1, main () at add-2.s:10
10 popq %rbx
# p $rax
$1 = 1001
# x/1gd $rsp
0x7fffffffde90: 1000
# %raxが1001,(%rsp)が1000なら成功
adc-1.sの実行例
$ gcc -g adc-1.s
$ gdb ./a.out -x adc-1.txt
reakpoint 1, main () at adc-1.s:8
8 adcq $2, %rax
# p $rax
$1 = 0
# p $eflags
$2 = [ CF PF AF ZF IF ]
main () at adc-1.s:9
9 ret
# p $rax
$3 = 3
# %rflagsでCFが立っていて,%raxが3なら成功
adc-2.sの実行例
$ gcc -g adc-2.s
$ gdb ./a.out -x adc-2.txt
Breakpoint 1, main () at adc-2.s:9
9 adcq $2, (%rsp)
# p $rax
$1 = 0
# p $eflags
$2 = [ CF PF AF ZF IF ]
main () at adc-2.s:10
10 ret
x/1gd $rsp
0x7fffffffde90: 1002
# %rflagsでCFが立っていて,(%rsp)が1002なら成功
adc-3.sの実行例
$ gcc -g adc-3.s
$ gdb ./a.out -x adc-3.txt
Breakpoint 1, main () at adc-3.s:9
9 adcq (%rsp), %rax
# p $rax
$1 = 0
# p $eflags
$2 = [ CF PF AF ZF IF ]
main () at adc-3.s:10
10 ret
# p $rax
$3 = 1000
# %rflagsでCFが立っていて,%raxが1000なら成功
sub, sbb命令: 引き算
| 記法 | 何の略か | 動作 |
|---|---|---|
sub␣ op1, op2 | subtract | op1 を op2 から引く |
sbb␣ op1, op2 | subtract with borrow | op1 と CF を op2 から引く |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
sub␣ imm, r/m | subq $999, %rax | %rax -= 999 | sub-1.s sub-1.txt |
sub␣ r, r/m | subq %rax, (%rsp) | *(%rsp) -= %rax | sub-2.s sub-2.txt |
sub␣ r/m, r | subq (%rsp), %rax | %rax -= *(%rsp) | sub-2.s sub-2.txt |
sbb␣ imm, r/m | sbbq $999, %rax | %rax -= 999 + CF | sbb-1.s sbb-1.txt |
sbb␣ r, r/m | sbbq %rax, (%rsp) | *(%rsp) -= %rax + CF | sbb-2.s sbb-2.txt |
sbb␣ r/m, r | sbbq (%rsp), %rax | %rax -= *(%rsp) + CF | sbb-2.s sbb-2.txt |
addと同様に,subとsbbは オペランドが符号あり整数か符号なし整数かを区別せず, 両方の結果を正しく計算します.
sub-1.sの実行例
$ gcc -g sub-1.s
$ gdb ./a.out -x sub-1.txt
Breakpoint 1, main () at sub-1.s:8
8 ret
# p $rax
$1 = 1
# %raxが1なら成功
sub-2.sの実行例
$ gcc -g sub-2.s
$ gdb ./a.out -x sub-2.txt
Breakpoint 1, main () at sub-2.s:10
10 popq %rbx
# p $rax
$1 = -997
# x/1gd $rsp
0x7fffffffde90: 998
# %raxが-997,(%rsp)が998なら成功
sbb-1.sの実行例
$ gcc -g sbb-1.s
$ gdb ./a.out -x sbb-1.txt
Breakpoint 1, main () at sbb-1.s:8
8 sbbq $2, %rax
# p $rax
$1 = 0
# p $eflags
$2 = [ CF PF AF ZF IF ]
main () at sbb-1.s:9
9 ret
# p $rax
$3 = -3
# %rflagsでCFが立っていて,%raxが-3なら成功
sbb-2.sの実行例
$ gcc -g sbb-2.s
$ gdb ./a.out -x sbb-2.txt
Breakpoint 1, main () at sbb-2.s:9
9 sbbq $2, (%rsp)
# p $rax
$1 = 0
# p $eflags
$2 = [ CF PF AF ZF IF ]
10 sbbq (%rsp), %rax
main () at sbb-2.s:11
11 ret
x/1gd $rsp
0x7fffffffde90: 996
# p $rax
$3 = -996
# %rflagsでCFが立っていて,(%rsp)が996,%raxが-996なら成功
mul, imul命令: かけ算
| 記法 | 何の略か | 動作 |
|---|---|---|
mul␣ op1 | unsigned multiply | 符号なし乗算.(%rdx:%rax) = %rax * op1 |
imul␣ op1 | signed multiply | 符号あり乗算.(%rdx:%rax) = %rax * op1 |
imul␣ op1, op2 | signed multiply | 符号あり乗算.op2 *= op1 |
imul␣ op1, op2, op3 | signed multiply | 符号あり乗算.op3 = op1 * op2 |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
mul␣ r/m | mulq %rbx | (%rdx:%rax) = %rax * %rbx | mul-1.s mul-1.txt |
imul␣ r/m | imulq %rbx | (%rdx:%rax) = %rax * %rbx | imul-1.s imul-1.txt |
imul␣ imm, r | imulq $4, %rax | %rax *= 4 | imul-2.s imul-2.txt |
imul␣ r/m, r | imulq %rbx, %rax | %rax *= %rbx | imul-2.s imul-2.txt |
imul␣ imm, r/m, r | imulq $4, %rbx, %rax | %rax = %rbx * 4 | imul-2.s imul-2.txt |

- オペランドが1つの形式では,
%raxが隠しオペランドになります. このため,乗算の前に%raxに値をセットしておく必要があります. また,8バイト同士の乗算結果は最大で16バイトになるので, 乗算結果を%rdxと%raxに分割して格納します (16バイトの乗算結果の上位8バイトを%rdxに,下位8バイトを%raxに格納します). これをここでは(%rdx:%rax)という記法で表現しています. imulだけ例外的に,オペランドが2つの形式と3つの形式があります. 2つか3つの形式では乗算結果が8バイトを超えた場合, 越えた分は破棄されます(乗算結果は8バイトのみ).
mul-1.sの実行例
$ gcc -g mul-1.s
$ gdb ./a.out -x mul-1.txt
Breakpoint 1, main () at mul-1.s:9
9 ret
# p $rdx
$1 = 0
# p $rax
$2 = 6
# %rdxが0, %raxが6なら成功
imul-1.sの実行例
$ gcc -g imul-1.s
$ gdb ./a.out -x imul-1.txt
Breakpoint 1, main () at imul-1.s:9
9 ret
# p $rdx
$1 = 0xffffffffffffffff
# p $rax
$2 = -6
# %rdxが0xFFFFFFFFFFFFFFFF, %raxが-6なら成功
imul-2.sの実行例
$ gcc -g imul-2.s
$ gdb ./a.out -x imul-2.txt
Breakpoint 1, main () at imul-2.s:8
8 imulq $4, %rax
9 imulq %rbx, %rax
1: $rax = -8
10 imulq $5, %rbx, %rax
1: $rax = 24
main () at imul-2.s:11
11 ret
1: $rax = -15
# %raxが-8, 24, -15なら成功
div, idiv命令: 割り算,余り
| 記法 | 何の略か | 動作 |
|---|---|---|
div␣ op1 | unsigned divide | 符号なし除算と余り%rax = (%rdx:%rax) / op1 %rdx = (%rdx:%rax) % op1 |
idiv␣ op1 | signed divide | 符号あり除算と余り%rax = (%rdx:%rax) / op1 %rdx = (%rdx:%rax) % op1 |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
div␣ r/m | divq %rbx | %rax = (%rdx:%rax) / %rbx %rdx = (%rdx:%rax) % %rbx | div-1.s div-1.txt |
idiv␣ r/m | idivq %rbx | %rax = (%rdx:%rax) / %rbx %rdx = (%rdx:%rax) % %rbx | idiv-1.s idiv-1.txt |
- 16バイトの値
%rdx:%raxを第1オペランドで割った商が%raxに入り, 余りが%rdxに入ります. - 隠しオペランドとして
%rdxと%raxが使われるので, 事前に値を設定しておく必要があります.idivを使う場合,もし%rdxを使わないのであれば,cqto命令で%raxを%rdx:%raxに符号拡張しておくと良いです.
div-1.sの実行例
$ gcc -g div-1.s
$ gdb ./a.out -x div-1.txt
Breakpoint 1, main () at div-1.s:10
10 ret
# p $rax
$1 = 33
# p $rdx
$2 = 9
# %raxが33, %rdxが9なら成功
idiv-1.sの実行例
$ gcc -g idiv-1.s
$ gdb ./a.out -x idiv-1.txt
Breakpoint 1, main () at idiv-1.s:9
9 idivq %rbx
# p/x $rdx
$1 = 0xffffffffffffffff
main () at idiv-1.s:10
10 ret
# p $rax
$2 = -33
# p $rdx
$3 = -9
# 最初の%rdxが0xFFFFFFFFFFFFFFFF, %raxが-33, 2番目の%rdxが-9なら成功
inc, dec命令: インクリメント,デクリメント
| 記法 | 何の略か | 動作 |
|---|---|---|
inc␣ op1 | increment | op1の値を1つ増加 |
dec␣ op1 | decrement | op1の値を1つ減少 |
incやdecはオーバーフローしてもCFが変化しないところがポイントです.
inc-1.sの実行例
$ gcc -g inc-1.s
$ gdb ./a.out -x inc-1.txt
Breakpoint 1, main () at inc-1.s:8
8 ret
# p $rax
$1 = 1
# %raxが1なら成功
dec-1.sの実行例
$ gcc -g dec-1.s
$ gdb ./a.out -x dec-1.txt
reakpoint 1, main () at dec-1.s:8
8 ret
# p $rax
$1 = -1
# %raxが-1なら成功
neg命令: 符号反転
| 記法 | 何の略か | 動作 |
|---|---|---|
neg␣ op1 | negation | 2の補数によるop1の符号反転 |
neg-1.sの実行例
$ gcc -g neg-1.s
$ gdb ./a.out -x neg-1.txt
Breakpoint 1, main () at neg-1.s:7
7 neg %rax
1: $rax = 999
8 neg %rax
1: $rax = -999
main () at neg-1.s:9
9 ret
1: $rax = 999
# %raxが 999 → -999 → 999 と変化すれば成功
not命令: ビット論理演算 (1)
| 記法 | 何の略か | 動作 |
|---|---|---|
not␣ op1 | bitwise not | op1の各ビットの反転 (NOT) |
not-1.sの実行例
$ gcc -g not-1.s
$ gdb ./a.out -x not-1.txt
Breakpoint 1, main () at not-1.s:7
7 not %al
1: /t $al = 11001010
8 not %al
1: /t $al = 110101
main () at not-1.s:9
9 ret
1: /t $al = 11001010
# %alが 11001010 → 110101 → 11001010 と変化すれば成功
and, or, xor命令: ビット論理演算 (2)
| 記法 | 何の略か | 動作 |
|---|---|---|
and␣ op1, op2 | bitwise and | op1とop2の各ビットごとの論理積(AND) |
or␣ op1, op2 | bitwise or | op1とop2の各ビットごとの論理和(OR) |
xor␣ op1, op2 | bitwise xor | op1とop2の各ビットごとの排他的論理和(XOR) |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
and␣ imm, r/m | andq $0x0FFF, %rax | %rax &= 0x0FFF | and-1.s and-1.txt |
and␣ r, r/m | andq %rax, (%rsp) | *(%rsp) &= %rax | and-1.s and-1.txt |
and␣ r/m, r | andq (%rsp), %rax | %rax &= *(%rsp) | and-1.s and-1.txt |
or␣ imm, r/m | orq $0x0FFF, %rax | %rax |= 0x0FFF | or-1.s or-1.txt |
or␣ r, r/m | orq %rax, (%rsp) | *(%rsp) |= %rax | or-1.s or-1.txt |
or␣ r/m, r | orq (%rsp), %rax | %rax |= *(%rsp) | or-1.s or-1.txt |
xor␣ imm, r/m | xorq $0x0FFF, %rax | %rax ^= 0x0FFF | xor-1.s xor-1.txt |
xor␣ r, r/m | xorq %rax, (%rsp) | *(%rsp) ^= %rax | xor-1.s xor-1.txt |
xor␣ r/m, r | xorq (%rsp), %rax | %rax ^= *(%rsp) | xor-1.s xor-1.txt |
&,|,^はC言語で,それぞれ,ビットごとの論理積,論理和,排他的論理積です (忘れた人はC言語を復習しましょう).
and-1.sの実行例
$ gcc -g and-1.s
$ gdb ./a.out -x and-1.txt
Breakpoint 1, main () at and-1.s:8
8 pushq $0B00001111
# p/t $al
$1 = 10001000
Breakpoint 2, main () at and-1.s:12
12 ret
# x/1bt $rsp
0x7fffffffde90: 00001000
# p/t $al
$2 = 0
# 表示される値が 10001000, 00001000, 0 なら成功
or-1.sの実行例
$ gcc -g or-1.s
$ gdb ./a.out -x or-1.txt
Breakpoint 1, main () at or-1.s:8
8 pushq $0B00001111
# p/t $al
$1 = 11101110
Breakpoint 2, main () at or-1.s:12
12 ret
# x/1bt $rsp
0x7fffffffde90: 11101111
# p/t $al
$2 = 11111111
# 表示される値が 11101110, 11101111, 11111111 なら成功
xor-1.sの実行例
$ gcc -g xor-1.s
$ gdb ./a.out -x xor-1.txt
Breakpoint 1, main () at xor-1.s:8
8 pushq $0B00001111
# p/t $al
$1 = 1100110
Breakpoint 2, main () at xor-1.s:12
12 ret
# x/1bt $rsp
0x7fffffffde90: 01101001
# p/t $al
$2 = 10011110
# 表示される値が 1100110, 01101001, 10011110 なら成功
sal, sar, shl, shr: シフト
| 記法 | 何の略か | 動作 |
|---|---|---|
sal␣ op1[, op2] | shift arithmetic left | 算術左シフト |
shl␣ op1[, op2] | shift logical left | 論理左シフト |
sar␣ op1[, op2] | shift arithmetic right | 算術右シフト |
shr␣ op1[, op2] | shift logical right | 論理右シフト |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
sal␣ r/m | salq %rax | %raxを1ビット算術左シフト | sal-1.s sal-1.txt |
sal␣ imm8, r/m | salq $2, %rax | %raxを2ビット算術左シフト | sal-1.s sal-1.txt |
sal␣ %cl, r/m | salq %cl, %rax | %raxを%clビット算術左シフト | sal-1.s sal-1.txt |
shl␣ r/m | shlq %rax | %raxを1ビット論理左シフト | shl-1.s shl-1.txt |
shl␣ imm8, r/m | shlq $2, %rax | %raxを2ビット論理左シフト | shl-1.s shl-1.txt |
shl␣ %cl, r/m | shlq %cl, %rax | %raxを%clビット論理左シフト | shl-1.s shl-1.txt |
sar␣ r/m | sarq %rax | %raxを1ビット算術右シフト | sar-1.s sar-1.txt |
sar␣ imm8, r/m | sarq $2, %rax | %raxを2ビット算術右シフト | sar-1.s sar-1.txt |
sar␣ %cl, r/m | sarq %cl, %rax | %raxを%clビット算術右シフト | sar-1.s sar-1.txt |
shr␣ r/m | shrq %rax | %raxを1ビット論理右シフト | shr-1.s shr-1.txt |
shr␣ imm8, r/m | shrq $2, %rax | %raxを2ビット論理右シフト | shr-1.s shr-1.txt |
shr␣ %cl, r/m | shrq %cl, %rax | %raxを%clビット論理右シフト | shr-1.s shr-1.txt |

- op1[, op2] という記法は「op2は指定してもしなくても良い」という意味です.
- シフトとは(指定したビット数だけ)右か左にビット列をずらすことを意味します. op2がなければ「1ビットシフト」を意味します.
- 論理シフトとは「空いた場所に0を入れる」, 算術シフトとは「空いた場所に符号ビットを入れる」ことを意味します.
- 左シフトの場合は(符号ビットを入れても意味がないので),論理シフトでも算術シフトでも,0を入れます.その結果,算術左シフト
salと論理左シフトshlは全く同じ動作になります. - C言語の符号あり整数に対する右シフト(>>)は算術シフトか論理シフトかは 決まっていません(実装依存です). C言語で,ビット演算は符号なし整数に対してのみ行うようにしましょう.
sal-1.sの実行例
$ gcc -g sal-1.s
$ gdb ./a.out -x sal-1.txt
Breakpoint 1, main () at sal-1.s:8
8 salq %rax
1: /t $rax = 11111111
9 salq $2, %rax
1: /t $rax = 111111110
10 salq %cl, %rax
1: /t $rax = 11111111000
main () at sal-1.s:11
11 ret
1: /t $rax = 11111111000000
# 表示される値が 11111111, 111111110, 11111111000, 11111111000000 なら成功
shl-1.sの実行例
$ gcc -g shl-1.s
$ gdb ./a.out -x shl-1.txt
reakpoint 1, main () at shl-1.s:8
8 shlq %rax
1: /t $rax = 11111111
9 shlq $2, %rax
1: /t $rax = 111111110
10 shlq %cl, %rax
1: /t $rax = 11111111000
main () at shl-1.s:11
11 ret
1: /t $rax = 11111111000000
# 表示される値が 11111111, 111111110, 11111111000, 11111111000000 なら成功
sar-1.sの実行例
$ gcc -g sar-1.s
$ gdb ./a.out -x sar-1.txt
Breakpoint 1, main () at sar-1.s:8
8 sarq %rax
1: /t $rax = 1111111111111111111111111111111111111111111111111111111100000000
9 sarq $2, %rax
1: /t $rax = 1111111111111111111111111111111111111111111111111111111110000000
10 sarq %cl, %rax
1: /t $rax = 1111111111111111111111111111111111111111111111111111111111100000
main () at sar-1.s:11
11 ret
1: /t $rax = 1111111111111111111111111111111111111111111111111111111111111100
# 表示される値が 1111111111111111111111111111111111111111111111111111111100000000, 1111111111111111111111111111111111111111111111111111111110000000, 1111111111111111111111111111111111111111111111111111111111100000, 1111111111111111111111111111111111111111111111111111111111111100 なら成功
shr-1.sの実行例
$ gcc -g shr-1.s
$ gdb ./a.out -x shr-1.txt
reakpoint 1, main () at shr-1.s:8
8 shrq %rax
1: /t $rax = 1111111111111111111111111111111111111111111111111111111100000000
9 shrq $2, %rax
1: /t $rax = 111111111111111111111111111111111111111111111111111111110000000
10 shrq %cl, %rax
1: /t $rax = 1111111111111111111111111111111111111111111111111111111100000
main () at shr-1.s:11
11 ret
1: /t $rax = 1111111111111111111111111111111111111111111111111111111100
# 表示される値が 1111111111111111111111111111111111111111111111111111111100000000, 111111111111111111111111111111111111111111111111111111110000000, 1111111111111111111111111111111111111111111111111111111100000, 1111111111111111111111111111111111111111111111111111111100 なら成功
rol, ror, rcl, rcr: ローテート
| 記法 | 何の略か | 動作 |
|---|---|---|
rol␣ op1[, op2] | rotate left | 左ローテート |
rcl␣ op1[, op2] | rotate left through carry | CFを含めて左ローテート |
ror␣ op1[, op2] | rotate right | 右ローテート |
rcr␣ op1[, op2] | rotate right through carry | CFを含めて右ローテート |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
rol␣ r/m | rolq %rax | %raxを1ビット左ローテート | rol-1.s rol-1.txt |
rol␣ imm8, r/m | rolq $2, %rax | %raxを2ビット左ローテート | rol-1.s rol-1.txt |
rol␣ %cl, r/m | rolq %cl, %rax | %raxを%clビット左ローテート | rol-1.s rol-1.txt |
rcl␣ r/m | rclq %rax | %raxを1ビットCFを含めて左ローテート | rcl-1.s rcl-1.txt |
rcl␣ imm8, r/m | rclq $2, %rax | %raxを2ビットCFを含めて左ローテート | rcl-1.s rcl-1.txt |
rcl␣ %cl, r/m | rclq %cl, %rax | %raxを%clビットCFを含めて左ローテート | rcl-1.s rcl-1.txt |
ror␣ r/m | rorq %rax | %raxを1ビット右ローテート | ror-1.s ror-1.txt |
ror␣ imm8, r/m | rorq $2, %rax | %raxを2ビット右ローテート | ror-1.s ror-1.txt |
ror␣ %cl, r/m | rorq %cl, %rax | %raxを%clビット右ローテート | ror-1.s ror-1.txt |
rcr␣ r/m | rcrq %rax | %raxを1ビットCFを含めて右ローテート | rcr-1.s rcr-1.txt |
rcr␣ imm8, r/m | rcrq $2, %rax | %raxを2ビットCFを含めて右ローテート | rcr-1.s rcr-1.txt |
rcr␣ %cl, r/m | rcrq %cl, %rax | %raxを%clビットCFを含めて右ローテート | rcr-1.s rcr-1.txt |

- op1[, op2] という記法は「op2は指定してもしなくても良い」という意味です.
- ローテートは,シフトではみ出したビットを空いた場所に入れます.
- ローテートする方向(右か左),CFを含めるか否かで,4パターンの命令が存在します.
rol-1.sの実行例
$ gcc -g rol-1.s
$ gdb ./a.out -x rol-1.txt
Breakpoint 1, main () at rol-1.s:8
8 rolq %rax
1: /t $rax = 11111111
9 rolq $2, %rax
1: /t $rax = 111111110
10 rolq %cl, %rax
1: /t $rax = 11111111000
main () at rol-1.s:11
11 ret
1: /t $rax = 11111111000000
# 表示される値が 11111111, 111111110, 11111111000, 11111111000000 なら成功
rcl-1.sの実行例
$ gcc -g rcl-1.s
$ gdb ./a.out -x rcl-1.txt
Breakpoint 1, main () at rcl-1.s:10
10 rclq %rax
1: /t $rax = 11111111
11 rclq $2, %rax
1: /t $rax = 111111111
12 rclq %cl, %rax
1: /t $rax = 11111111100
main () at rcl-1.s:13
13 ret
1: /t $rax = 11111111100000
# 表示される値が 11111111, 111111111, 11111111100, 11111111100000 なら成功
ror.sの実行例
$ gcc -g ror.s
$ gdb ./a.out -x ror.txt
Breakpoint 1, main () at ror-1.s:8
8 rorq %rax
1: /t $rax = 11111111
9 rorq $2, %rax
1: /t $rax = 1000000000000000000000000000000000000000000000000000000001111111
10 rorq %cl, %rax
1: /t $rax = 1110000000000000000000000000000000000000000000000000000000011111
main () at ror-1.s:11
11 ret
1: /t $rax = 1111110000000000000000000000000000000000000000000000000000000011
# 表示される値が 11111111, 1000000000000000000000000000000000000000000000000000000001111111, 1110000000000000000000000000000000000000000000000000000000011111, 1111110000000000000000000000000000000000000000000000000000000011 なら成功
rcr-1.sの実行例
$ gcc -g rcr-1.s
$ gdb ./a.out -x rcr-1.txt
Breakpoint 1, main () at rcr-1.s:10
10 rcrq %rax
1: /t $rax = 11111010
11 rcrq $2, %rax
1: /t $rax = 1000000000000000000000000000000000000000000000000000000001111101
12 rcrq %cl, %rax
1: /t $rax = 1010000000000000000000000000000000000000000000000000000000011111
main () at rcr-1.s:13
13 ret
1: /t $rax = 1101010000000000000000000000000000000000000000000000000000000011
# 表示される値が 11111010, 1000000000000000000000000000000000000000000000000000000001111101, 1010000000000000000000000000000000000000000000000000000000011111, 1101010000000000000000000000000000000000000000000000000000000011 なら成功
cmp, test: 比較
cmp命令
| 記法 | 何の略か | 動作 |
|---|---|---|
cmp␣ op1[, op2] | compare | op1とop2の比較結果をフラグに格納(比較はsub命令を使用) |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
cmp␣ imm, r/m | cmpq $999, %rax | subq $999, %raxのフラグ変化のみ計算.オペランドは変更なし | cmp-1.s cmp-1.txt |
cmp␣ r, r/m | cmpq %rax, (%rsp) | subq %rax, (%rsp)のフラグ変化のみ計算.オペランドは変更なし | cmp-1.s cmp-1.txt |
cmp␣ r/m, r | cmpq (%rsp), %rax | subq (%rsp), %raxのフラグ変化のみ計算.オペランドは変更なし | cmp-1.s cmp-1.txt |
cmp命令はフラグ計算だけを行います. (レジスタやメモリは変化しません).cmp命令は条件付きジャンプ命令と一緒に使うことが多いです. 例えば以下の2命令で「%raxが(符号あり整数として)1より大きければジャンプする」という意味になります.
cmpq $1, %rax
jg L2
cmp-1.sの実行例
$ gcc -g cmp-1.s
$ gdb ./a.out -x cmp-1.txt
reakpoint 1, main () at cmp-1.s:8
8 cmpq $1, %rax # %rax (=0) - 1
9 cmpq %rax, (%rsp) # (%rsp) (=1) - %rax (=0)
1: $eflags = [ CF PF AF SF IF ]
10 cmpq (%rsp), %rax # %rax (=0) - (%rsp) (=1)
1: $eflags = [ IF ]
main () at cmp-1.s:11
11 ret
1: $eflags = [ CF PF AF SF IF ]
# 表示されるステータスフラグが以下なら成功
# 1: $eflags = [ CF PF AF SF IF ] (SF==1 → 結果は負)
# 1: $eflags = [ IF ] (SF==0 → 結果は0か正)
# 1: $eflags = [ CF PF AF SF IF ] (SF==1 → 結果は負)
test命令
| 記法 | 何の略か | 動作 |
|---|---|---|
test␣ op1[, op2] | logical compare | op1とop2の比較結果をフラグに格納(比較はand命令を使用) |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
test␣ imm, r/m | testq $999, %rax | andq $999, %raxのフラグ変化のみ計算.オペランドは変更なし | test-1.s test-1.txt |
test␣ r, r/m | testq %rax, (%rsp) | andq %rax, (%rsp)のフラグ変化のみ計算.オペランドは変更なし | test-1.s test-1.txt |
test␣ r/m, r | testq (%rsp), %rax | andq (%rsp), %raxのフラグ変化のみ計算.オペランドは変更なし | test-1.s test-1.txt |
cmp命令と同様に,test命令はフラグ計算だけを行います. (レジスタやメモリは変化しません).cmp命令と同様に,test命令は条件付きジャンプ命令と一緒に使うことが多いです. 例えば以下の2命令で「%raxが0ならジャンプする」という意味になります.
testq %rax, %rax
jz L2
- 例えば
%raxが0かどうかを知りたい場合,cmpq $0, %raxとtestq %rax, %raxのどちらでも調べることができます. どちらの場合も,ZF==1なら,%raxが0と分かります (testq %rax, %raxはビットごとのANDのフラグ変化を計算するので,%raxがゼロの時だけ,ZF==1となります). コンパイラはtestq %rax, %raxを使うことが多いです.testq %rax, %raxの方が命令長が短くなるからです.
test-1.sの実行例
$ gcc -g test-1.s
$ gdb ./a.out -x test-1.txt
Breakpoint 1, main () at test-1.s:8
8 testq $0, %rax # %rax (=1) & 0
9 testq %rax, (%rsp) # (%rsp) (=1) & %rax (=1)
1: $eflags = [ PF ZF IF ]
10 testq (%rsp), %rax # %rax (=1) & (%rsp) (=1)
1: $eflags = [ IF ]
main () at test-1.s:11
11 ret
1: $eflags = [ IF ]
# 表示されるステータスフラグが以下なら成功
# 1: $eflags = [ PF ZF IF ] (ZF==1 → 結果は0)
# 1: $eflags = [ IF ] (ZF==0 → 結果は非0)
# 1: $eflags = [ IF ] (ZF==0 → 結果は非0)
movs, movz, cbtw, cqto命令: 符号拡張とゼロ拡張
movs, movz命令
| 記法(AT&T形式) | 記法(Intel形式) | 何の略か | 動作 |
|---|---|---|---|
movs␣␣ op1, op2 | movsx op2, op1 movsxd op2, op1 | move with sign-extention | op1を符号拡張した値をop2に格納 |
movz␣␣ op1, op2 | movzx op2, op1 | move with zero-extention | op1をゼロ拡張した値をop2に格納 |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
movs␣␣ r/m, r | movslq %eax, %rbx | %rbx = %eaxを8バイトに符号拡張した値 | movs-movz.s movs-movz.txt |
movz␣␣ r/m, r | movzwq %ax, %rbx | %rbx = %axを8バイトにゼロ拡張した値 | movs-movz.s movs-movz.txt |
␣␣に入るもの | 何の略か | 意味 |
|---|---|---|
bw | byte to word | 1バイト→2バイトの拡張 |
bl | byte to long | 1バイト→4バイトの拡張 |
bq | byte to quad | 1バイト→8バイトの拡張 |
wl | word to long | 2バイト→4バイトの拡張 |
wq | word to quad | 2バイト→8バイトの拡張 |
lq | long to quad | 4バイト→8バイトの拡張 |
movs,movz命令はAT&T形式とIntel形式でニモニックが異なるので注意です.- GNUアセンブラではAT&T形式でも実は
movsx,movzxのニモニックが使用できます. ただし逆アセンブルすると,movslq,movzwqなどのニモニックが表示されるので,movslq,movzwqなどを使う方が良いでしょう. movzlq(Intel形式ではmovzxd)はありません.例えば,%eaxに値を入れると,%raxの上位32ビットはクリアされるので,movzlqは不要だからです.- Intel形式では,4バイト→8バイトの拡張の時だけ,
(
movsxではなく)movsxdを使います.
movs-movz.sの実行例
$ gcc -g movs-movz.s
$ gdb ./a.out -x movs-movz.txt
Breakpoint 1, main () at movs-movz.s:7
7 movslq %eax, %rbx
8 movzwq %ax, %rbx
1: /x $rbx = 0xffffffffffffffff
main () at movs-movz.s:9
9 ret
1: /x $rbx = 0xffff
# 以下が表示されれば成功
# 1: /x $rbx = 0xffffffffffffffff
# 1: /x $rbx = 0xffff
cbtw, cqto命令
| 記法(AT&T形式) | 記法(Intel形式) | 何の略か | 動作 |
|---|---|---|---|
c␣t␣ | c␣␣␣ | convert ␣ to ␣ | %rax (または%eax, %ax, %al)を符号拡張 |
| 詳しい記法 (AT&T形式) | 詳しい記法 (Intel形式) | 例 | 例の動作 | サンプルコード |
|---|---|---|---|---|
cbtw | cbw | cbtw | %al(byte)を%ax(word)に符号拡張 | cbtw.s cbtw.txt |
cwtl | cwde | cwtl | %ax(word)を%eax(long)に符号拡張 | cbtw.s cbtw.txt |
cwtd | cwd | cwtd | %ax(word)を%dx:%ax(double word)に符号拡張 | cbtw.s cbtw.txt |
cltd | cdq | cltd | %eax(long)を%edx:%eax(double long, quad)に符号拡張 | cbtw.s cbtw.txt |
cltq | cdqe | cltq | %eax(long)を%rax(quad)に符号拡張 | cbtw.s cbtw.txt |
cqto | cqo | cqto | %rax(quad)を%rdx:%rax(octuple)に符号拡張 | cbtw.s cbtw.txt |
cqtoなどはidivで割り算する前に使うと便利(%rdx:%raxがidivの隠しオペランドなので).- GNUアセンブラはIntel形式のニモニックも受け付ける.
cbtw.sの実行例
$ gcc -g cbtw.s
$ gdb ./a.out -x cbtw.txt
Breakpoint 1, main () at cbtw.s:7
7 cbtw # %al -> %ax
9 cwtl # %ax -> %eax
$1 = -1
$2 = 0xffff
11 cwtd # %ax -> %dx:%ax
$3 = -1
$4 = 0xffffffff
13 cltd # %eax -> %edx:%eax
$5 = {-1, -1}
$6 = {0xffff, 0xffff}
15 cltq # %eax -> %rax
$7 = {-1, -1}
$8 = {0xffffffff, 0xffffffff}
17 cqto # %rax -> %rdx:%rax
$9 = -1
$10 = 0xffffffffffffffff
main () at cbtw.s:19
19 ret
$11 = {-1, -1}
$12 = {0xffffffffffffffff, 0xffffffffffffffff}
# 以下が表示されれば成功
# $1 = -1
# $2 = 0xffff
# $3 = -1
# $4 = 0xffffffff
# $5 = {-1, -1}
# $6 = {0xffff, 0xffff}
# $7 = {-1, -1}
# $8 = {0xffffffff, 0xffffffff}
# $9 = -1
# $10 = 0xffffffffffffffff
# $11 = {-1, -1}
# $12 = {0xffffffffffffffff, 0xffffffffffffffff}
ジャンプ命令
- ジャンプとは「次に実行する命令を(『次の番地の命令』ではなく)
『別の番地の命令』にすることです.
ジャンプの仕組みは簡単で「ジャンプ先のアドレスをプログラムカウンタ
%ripに代入する」だけです. C言語風に書くと%rip = ジャンプ先のアドレスとなります (ジャンプ先が相対アドレスで与えられた場合は,%rip += 相対アドレスになります). - 無条件ジャンプはC言語の
goto文と同じで常にジャンプします. 条件付きジャンプは条件が成り立った時だけジャンプします. 条件付きジャンプをC言語風に書くとif (条件) goto ジャンプ先;になります.
絶対ジャンプと相対ジャンプ

- 絶対ジャンプ (absolute jump)は絶対アドレス,
つまりメモリの先頭からのオフセットでジャンプ先のアドレスを指定するジャンプです.
上の例で,AからBにジャンプする時,
jmp 0x1000は絶対ジャンプになります. - 相対ジャンプ (relative jump)は
プログラムカウンタ
%ripを起点とする相対アドレスで ジャンプ先のアドレスを指定するジャンプです. 上の例で,AからBにジャンプする時,jmp -0x500は相対ジャンプになります. (プログラムカウンタは「次に実行する命令を指すレジスタ」なので, 正確には「Aの一つ前の命令からBにジャンプする時」になります).
直接ジャンプと間接ジャンプ

-
直接ジャンプ (direct jump)はジャンプ先のアドレスを 即値 (定数)で指定するジャンプです. 上の例で一番左の
jmp 0x1000は直接ジャンプです. -
間接ジャンプ (indirect jump)はジャンプ先のアドレスを レジスタやメモリで指定して,その中に格納されている値を ジャンプ先のアドレスとするジャンプです.
- 上の例で真ん中の
jmp *%raxはレジスタを使った間接ジャンプです. レジスタ中のアドレス (ここでは0x1000番地)にジャンプします. (なぜアスタリスク*が必要なのかは謎です.GNUアセンブラの記法です.) - 上の例で一番右の
jmp *(%rax)はメモリ参照を使った間接ジャンプです. メモリ中のアドレス (ここでは0x1000番地)にジャンプします.
- 上の例で真ん中の
jmp: 無条件ジャンプ
| 記法 | 何の略か | 動作 |
|---|---|---|
jmp op1 | jump | op1にジャンプ |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
jmp rel | jmp 0x1000 | 0x1000番地に相対・直接ジャンプ (%rip += 0x1000) | jmp.s jmp.txt |
jmp foo | foo番地に相対・直接ジャンプ (%rip += foo) | jmp.s jmp.txt | |
jmp r/m | jmp *%rax | *%rax番地に絶対・間接ジャンプ (%rip = *%rax)) | jmp.s jmp.txt |
jmp r/m | jmp *(%rax) | *(%rax)番地に絶対・間接ジャンプ (%rip = *(%rax)) | jmp.s jmp.txt |
- x86-64では,相対・直接と絶対・間接の組み合わせしかありません. (つまり,相対・間接ジャンプや絶対・直接ジャンプはありません. なお,ここで紹介していないfarジャンプでは絶対・直接もあります).
- 相対・直接ジャンプでは符号ありの8ビット(rel8)か 32ビット(rel32)の整数定数で相対アドレスを指定します. (64ビットの相対アドレスは指定できません.64ビットのジャンプをしたい時は 絶対・間接ジャンプ命令を使います).
- rel8かrel32かはアセンブラが勝手に選んでくれます.
逆に
jmpbやjmplなどとサフィックスをつけて指定することはできません. - なぜか,定数なのにrel8やrel32にはドルマーク
$をつけません. 逆にr/mの前にはアスタリスク*が必要です. GNUアセンブラのこの部分は一貫性がないので要注意です.
条件付きジャンプの概要
- 条件付きジャンプ命令
j␣は ステータスフラグ (CF, OF, PF, SF, ZF)をチェックして, 条件が成り立てばジャンプします. 条件が成り立たない場合はジャンプせず,次の命令に実行を進めます. - 条件付きジャンプは比較命令と一緒に使うことが多いです.
例えば以下の2命令で「
%raxが(符号あり整数として)1より大きければジャンプする」という意味になります.
cmpq $1, %rax
jg L2
- 条件付きジャンプ命令のニモニックでは次の用語を使い分けます
- 符号あり整数の大小には less/greater を使う
- 符号なし整数の大小には above/below を使う
条件付きジャンプ: 符号あり整数用
| 記法 | 何の略か | 動作 | ジャンプ条件 |
|---|---|---|---|
jg reljnle rel | jump if greater jump if not less nor equal | op2>op1ならrelにジャンプ !(op2<=op1)ならrelにジャンプ | ZF==0&&SF==OF |
jge reljnl rel | jump if greater or equal jump if not less | op2>=op1ならrelにジャンプ !(op2<op1)ならrelにジャンプ | SF==OF |
jle reljng rel | jump if less or equal jump if not greater | op2<=op1ならrelにジャンプ !(op2>op1)ならrelにジャンプ | ZF==1||SF!=OF |
jl reljnge rel | jump if less jump if not greater nor equal | op2<op1ならrelにジャンプ !(op2>=op1)ならrelにジャンプ | SF!=OF |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
jg rel | cmpq $0, %raxjg foo | if (%rax>0) goto foo | jg.s jg.txt |
jnle rel | cmpq $0, %raxjnle foo | if (!(%rax<=0)) goto foo | jg.s jg.txt |
jge rel | cmpq $0, %raxjge foo | if (%rax>=0) goto foo | jge.s jge.txt |
jnl rel | cmpq $0, %raxjnl foo | if (!(%rax<0)) goto foo | jge.s jge.txt |
jle rel | cmpq $0, %raxjle foo | if (%rax<=0) goto foo | jle.s jle.txt |
jng rel | cmpq $0, %raxjng foo | if (!(%rax>0)) goto foo | jle.s jle.txt |
jl rel | cmpq $0, %raxjl foo | if (%rax<0) goto foo | jl.s jl.txt |
jnge rel | cmpq $0, %raxjnge foo | if (!(%rax>=0)) goto foo | jl.s jl.txt |
- op1 と op2 は条件付きジャンプ命令の直前で使用した
cmp命令のオペランドを表します. jgとjnleは異なるニモニックですが動作は同じです. その証拠にジャンプ条件はZF==0&&SF==OFと共通です. 他の3つのペア,jgeとjnl,jleとjng,jlとjngeも同様です.
なぜ ZF==0&&SF=OF が(符号ありの場合の)op2>op1になるのか
- 復習:
cmp␣op1, op2は (op2 - op1)という引き算を計算した時の フラグ変化を計算します. - ①: OF==0(オーバーフロー無し)の場合:
- SF==0 だと引き算の結果は0以上→ op2 - op1 >= 0 → op2 >= op1
- ②: OF==1(オーバーフローあり)の場合:
- 結果の正負が逆になる.つまり SF==1 だと引き算の結果は負(OF==1で逆になるので正)→ op2 - op1 >= 0 → op2 >= op1
- ③: ①と②から,(OF==0&&SF==0)||(OF==1&&SF==1)なら,op2 >= op1 になる. (OF==0&&SF==0)||(OF==1&&SF==1)を簡単にすると OF==SF になる.
- ④: ③に ZF==0 (結果はゼロではない)という条件を加えると, ZF==0&&SF=OF が op2 > op1 と等価になる.

- 上の例で,OF==1の時,引き算結果の大小関係(SF)が逆になることを見てみます.
- (+64)-(-64)はオーバーフローが起きて,結果は-128になります(SF==1). 引き算の結果は負ですが,大小関係は (+64) > (-64) です(逆になってます).
- (-64)-(+65)はオーバーフローが起きて,結果は127になります(SF==0). 引き算の結果は正ですが,大小関係は (-64) < (+65) です(逆になってます).
条件付きジャンプ: 符号なし整数用
| 記法 | 何の略か | 動作 | ジャンプ条件 |
|---|---|---|---|
ja reljnbe rel | jump if above jump if not below nor equal | op2>op1ならrelにジャンプ !(op2<=op1)ならrelにジャンプ | CF==0&ZF==0 |
jae reljnb rel | jump if above or equal jump if not below | op2>=op1ならrelにジャンプ !(op2<op1)ならrelにジャンプ | CF==0 |
jbe reljna rel | jump if below or equal jump if not above | op2<=op1ならrelにジャンプ !(op2>op1)ならrelにジャンプ | CF==1&&ZF==1 |
jb reljnae rel | jump if below jump if not above nor equal | op2<op1ならrelにジャンプ !(op2>=op1)ならrelにジャンプ | CF==1 |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
ja rel | cmpq $0, %raxja foo | if (%rax>0) goto foo | ja.s ja.txt |
jnbe rel | cmpq $0, %raxjnbe foo | if (!(%rax<=0)) goto foo | ja.s ja.txt |
jae rel | cmpq $0, %raxjae foo | if (%rax>=0) goto foo | jae.s jae.txt |
jnb rel | cmpq $0, %raxjnb foo | if (!(%rax<0)) goto foo | jae.s jae.txt |
jbe rel | cmpq $0, %raxjbe foo | if (%rax<=0) goto foo | jbe.s jbe.txt |
jna rel | cmpq $0, %raxjna foo | if (!(%rax>0)) goto foo | jbe.s jbe.txt |
jb rel | cmpq $0, %raxjb foo | if (%rax<0) goto foo | jb.s jb.txt |
jnae rel | cmpq $0, %raxjnae foo | if (!(%rax>=0)) goto foo | jb.s jb.txt |
- op1 と op2 は条件付きジャンプ命令の直前で使用した
cmp命令のオペランドを表します. jaとjnbeは異なるニモニックですが動作は同じです. その証拠にジャンプ条件はCF==0&&ZF==0と共通です. 他の3つのペア,jaeとjnb,jbeとjna,jbとjnaeも同様です.
条件付きジャンプ: フラグ用
| 記法 | 何の略か | 動作 | ジャンプ条件 |
|---|---|---|---|
jc rel | jump if carry | CF==1ならrelにジャンプ | CF==1 |
jnc rel | jump if not carry | CF==0ならrelにジャンプ | CF==0 |
jo rel | jump if overflow | OF==1ならrelにジャンプ | OF==1 |
jno rel | jump if not overflow | OF==0ならrelにジャンプ | OF==0 |
js rel | jump if sign | SF==1ならrelにジャンプ | SF==1 |
jns rel | jump if not sign | SF==0ならrelにジャンプ | SF==0 |
jz rel je rel | jump if zero jump if equal | ZF==1ならrelにジャンプ op2==op1ならrelにジャンプ | ZF==1 |
jnz rel jne rel | jump if not zero jump if not equal | ZF==0ならrelにジャンプ op2!=op1ならrelにジャンプ | ZF==0 |
jp rel jpe rel | jump if parity jump if parity even | PF==1ならrelにジャンプ | PF==1 |
jnp rel jpo rel | jump if not parity jump if parity odd | PF==0ならrelにジャンプ | PF==0 |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
jc rel | jc foo | if (CF==1) goto foo | jc.s jc.txt |
jnc rel | jnc foo | if (CF==0) goto foo | jc.s jc.txt |
jo rel | jo foo | if (OF==1) goto foo | jo.s jo.txt |
jno rel | jno foo | if (OF==0) goto foo | jo.s jo.txt |
js rel | js foo | if (SF==1) goto foo | js.s js.txt |
jns rel | jns foo | if (SF==0) goto foo | js.s js.txt |
jz rel | jz foo | if (ZF==1) goto foo | jz.s jz.txt |
je rel | cmpq $0, %raxje foo | if (%rax==0) goto foo | jz.s jz.txt |
jnz rel | jnz foo | if (ZF==0) goto foo | jz.s jz.txt |
jne rel | cmpq $0, %raxjne foo | if (%rax!=0) goto foo | jz.s jz.txt |
jp rel | jp foo | if (PF==1) goto foo | jp.s jp.txt |
jpe rel | jpe foo | if (PF==1) goto foo | jp.s jp.txt |
jnp rel | jnp foo | if (PF==0) goto foo | jp.s jp.txt |
jpo rel | jpo foo | if (PF==0) goto foo | jp.s jp.txt |
jzとjeは異なるニモニックですが動作は同じです. その証拠にジャンプ条件はZF==1と共通です. 他の3つのペア,jnzとjne,jpとjpe,jnpとjpoも同様です.- AFフラグのための条件付きジャンプ命令は存在しません.
call, ret命令: 関数を呼び出す,リターンする
| 記法 | 何の略か | 動作 |
|---|---|---|
call op1 | call procedure | %ripをスタックにプッシュしてから op1にジャンプする( pushq %rip; %rip = op1) |
ret | return from procedure | スタックからポップしたアドレスにジャンプする ( popq %rip) |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
call rel | call foo | 相対・直接の関数コール | call.s call.txt |
call r/m | call *%rax | 絶対・間接の関数コール | call.s call.txt |
ret | ret | 関数からリターン | call.s call.txt |
call.sの実行例
$ gcc -g call.s
$ gdb ./a.out -x call.txt
reakpoint 1, main () at call.s:12
12 call foo
1: /x $rip = 0x401107
# info address foo
Symbol "foo" is at ❶0x401106 in a file compiled without debugging.
Breakpoint 2 at 0x401106: file call.s, line 6.
❷Breakpoint 2, foo () at call.s:6
6 ret
1: /x $rip = 0x401106
❸Breakpoint 2, foo () at call.s:6
6 ret
1: /x $rip = 0x401106
❹Breakpoint 2, foo () at call.s:6
6 ret
1: /x $rip = 0x401106
# 3回,関数fooを呼び出して,リターンできていれば成功
info address fooコマンドで,fooのアドレスは❶0x401106番地と分かりました.- ❷❸❹より3回,
fooを呼び出せていることが分かります.
注: 関数呼び出し規約(calling convention),スタックレイアウトなどは ABIが定めるお約束です. 以下ではLinuxのABIに基づいて説明します.
関数の呼び出し時に戻り番地をスタックに積む,リターン時に戻り番地をスタックから取り出す
関数呼び出しとリターンにはスタックを使います(スタック超重要). スタックは以下の図の通り,プロセスが使うメモリの一部の領域です.
関数呼び出しにジャンプ命令(jmp)を使うと,
(一般的に呼び出す側は複数箇所なので)
リターン時にどこに戻ればよいかが分かりません.
そこで,戻る場所(戻り番地 (return address))をスタックに保存しておきます.
call命令はこの「戻り番地をスタックに保存する」ことを自動的にやってくれます.
以下で具体例call2.sを見てみましょう.
call2.sでは関数mainから関数fooをcall命令で呼び出して,
関数fooから関数mainにret命令でリターンしています.
# asm/call2.s
.text
.type foo, @function
foo:
ret
.size foo, .-foo
.globl main
.type main, @function
main:
call foo
ret
.size main, .-main
$ gcc -g -no-pie call2.s
$ objdump -d ./a.out
(中略)
0000000000401106 <foo>:
❷401106: c3 ret
0000000000401107 <main>:
401107: e8 fa ff ff ff call 401106 <foo>
❶40110c: c3 ret
-no-pieオプションは
実行するたびにアドレスが変わらないためにつけています.
-no-pieオプション無しでも仕組みは変わりません.
-
call foo実行直前: 図(左)が示す通り%ripはcall foo命令を指しています. ここで,call foo命令を実行すると,%ripはcall foo命令の次の命令(ここではmain関数中のret命令)を指します. (%ripは「実行中の命令の次の命令」を指すことを思い出しましょう).call fooはまず%ripの値(上図では❶0x40110C)をスタックにプッシュします. その結果,スタック上に0x40110Cが書き込まれます. この0x40110Cが(関数fooからリターンする際の)戻り番地となります.- 次に,
call fooは関数fooの先頭番地(上図では❷0x401106)にジャンプします.
-
call foo実行直後: 図(中)が示す通り%ripはfoo関数のret命令を指しています. 一方,スタックトップ(%rspが指している場所)には 戻り番地0x40110Cが格納されています. ここで,ret命令を実行すると,- スタックから戻り番地
0x40110Cをポップして取り出して,%ripに格納します(つまり0x40110C番地にジャンプします).
- スタックから戻り番地
-
関数
fooのret実行直後: 無事に関数mainのcall foo命令の次の命令(ここではret命令)に戻ってこれました.
このように戻り番地をスタックに格納すれば,(メモリ不足にならない限り) どれだけ数多くの関数呼び出しが続いても,正しい順番でリターンすることができます. 戻り番地の格納にスタックを使えば, 「コールした順番とは逆の順序で戻りアドレスを取り出せる」からです.

例えば,上図のようにA→B→C→Dという順番で関数コールをした場合, 上図の順番で「Aへの戻り番地」「Bへの戻り番地」「Cへの戻り番地」が スタックに積まれます. リターンするときはD→C→B→Aという逆の順番になるわけですが, スタックを使っているので, ポップするたびに「Cへの戻り番地」「Bへの戻り番地」「Aへの戻り番地」 という逆の順番で戻り番地を正しく取り出せます.
C言語の関数ポインタと,間接call命令
// asm/fp.c
int add5 (int n)
{
return n + 5;
}
int main ()
{
int (*fp)(int n);
fp = add5;
return fp (10);
}
$ gcc -g fp.c
$ objdump -d ./a.out
(中略)
000000000000113c <main>:
113c: f3 0f 1e fa endbr64
1140: 55 push %rbp
1141: 48 89 e5 mov %rsp,%rbp
1144: 48 83 ec 10 sub $0x10,%rsp
1148: 48 8d 05 da ff ff ff ❷ lea -0x26(%rip),%rax # 1129 <add5>
114f: 48 89 45 f8 mov %rax,-0x8(%rbp)
1153: 48 8b 45 f8 mov -0x8(%rbp),%rax
1157: bf 0a 00 00 00 mov $0xa,%edi
115c: ff d0 ❶ call *%rax
115e: c9 leave
115f: c3 ret
- C言語で関数ポインタを使うと,間接
call命令にコンパイルされます.asm/fp.c中の
int (*fp)(int n);
の部分は「『int型の引数をもらい,int型を返す関数』へのポインタを
格納する変数fpを定義しています.
そして,fp = add5と代入を行い,fp (10)することで,
関数ポインタを使って間接的にadd5関数を呼び出しています.
- このCコードをコンパイルして逆アセンブルすると,
関数ポインタを使った関数呼び出しは,
間接
call命令 (ここでは❶ call *%rax)になっていることが分かります.%raxには関数add5の先頭アドレスが入っています (ここでは ❷lea -0x26(%rip),%raxを実行することで).
fp = add5 であってる?
fp = add5ではなくfp = &add5が正しいのでは?と思った人はいますか?
fp = add5で正しいです.
(sizeofや単項演算子&のオペランドであるときを除いて)
式中では「関数は関数へのポインタ」に暗黙的に型変換されます.
ですので,式中でadd5の型は「関数へのポインタ」になり,
fpとadd5は同じ型になります
(fp = &add5としても動くんですけどね).
fp (10)も同様です.「fpは関数へのポインタなのだから,
(*fp) (10)が正しいのでは?」と思うかも知れません.
でも,fp (10)で正しいです.
そもそも関数呼び出しの文法は「関数 ( 引数の列 )」ではなく,
「関数へのポインタ ( 引数の列 )」です.
add5 (10)のadd5の型は関数へのポインタなんです.
ちなみに(*fp)(10)としても動きます.
(*fp)は「関数へのポインタを関数」に戻しますが,その戻った関数型は
すぐに「関数型へのポインタ」に変換されるからです.
ですので,(******fp)(10)でも動きます.
enter, leave命令: スタックフレームを作成する,解放する
スタックフレーム
- 戻り番地はスタックに格納しますが, それ以外のデータ(例えば,局所変数,引数,返り値,退避したレジスタの値など)も スタックを使います.
- スタック上で管理する,関数呼び出し1回分のデータのことを スタックフレーム (stack frame)といいます.
例えば,main関数がadd5関数を呼び出して,add5からリターンすると以下の図になります.
スタックフレームにはいろいろなデータが入っていますが,
スタックフレームまるごとでプッシュしたりポップしたりします.
ですので,関数を呼び出したりリターンする時はこの
「スタックフレームをプッシュしたり,ポップしたり」,
つまり「スタックフレームを作成したり,破棄したり」する機械語命令列を
使う必要があります(以下で説明します).
そして%rspと%rbpは以下の図のように,
スタック上の一番上のスタックフレームの上下を指す役割を担っています.
(ただし,-fomit-frame-pointer
オプションでコンパイルされている場合を除く).
enter, leave命令
| 記法 | 何の略か | 動作 |
|---|---|---|
enter op1, op2 | make stack frame | サイズop1のスタックフレームを作成する |
leave | discard stack frame | 今のスタックフレームを破棄する |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
enter imm16, imm8 | enter $0x20, $0 | pushq %rbpmovq %rsp, %rbpsubq $0x20, %rsp | enter.s enter.txt |
leave | leave | movq %rbp, %rsppopq %rbp | enter.s enter.txt |
enter命令のop2には関数のネストレベルを指定するのですが, C言語では入れ子の関数がない(つまりネストレベルは常にゼロ)なので 常にゼロを指定します.- ただし,
enterは遅いので通常は使いません. 代わりに同等の動作をするpushq %rbp; movq %rsp, %rbp; subq $size, %rspを使います.(sizeは新しいスタックフレームで確保するバイトサイズです). スタックは0番地に向かって成長するので,足し算ではなく引き算を使います.
enter命令はどのぐらい遅いのか(3〜4倍?)
$ gcc -g rdtscp-enter.c
$ ./a.out
processor ID = 0
processor ID = 0
processor ID = 0
240966
60796
$ ./a.out
processor ID = 0
processor ID = 0
processor ID = 0
165718
46368
$ ./a.out
processor ID = 1
processor ID = 1
processor ID = 1
204346
49530
インラインアセンブラを使ったCプログラムrdtscp-enter.cで,以下のコードを10000万回繰り返して,
タイムスタンプカウンタの差分を調べた所,
(単純な調べ方ですが)概ね3〜4倍という結果になりました.
# 遅い
asm volatile ("enter $32, $0; leave");
# 速い
asm volatile ( "pushq %rbp; movq %rsp, %rbp;"
"subq $32, %rsp; leave");
leaveを入れないとスタックを使い切ってしまうのでleaveを入れています.
leaveを除いて計測すればもうちょっと差が開くかも知れません.
というわけで,enterは遅いので,コンパイラがenterの代わりに出力する
機械語命令列で説明します.
# asm/stack-frame.s
.text
.type foo, @function
foo:
pushq %rbp
movq %rsp, %rbp
subq $32, %rsp
# 本来はここにfoo関数本体の機械語列が来る
leave # movq %rbp, %rsp; pop %rbp と同じ
ret
.globl main
.type main, @function
main:
call foo
ret
.size main, .-main
$ gcc -g enter2.s
$ gdb ./a.out -x stack-frame.txt
- 関数
fooの最初の3行が「関数fooのスタックフレーム」を作ります.
pushq %rbp
movq %rsp, %rbp
subq $32, %rsp
call前:%rspと%rbpは関数mainのスタックフレームの上下を指しています.call後:call命令が戻り番地をプッシュしてから, (図にはありませんが)関数fooにジャンプします.pushq %rbp後: スタックに%rbpの値(図中では古い%rbpの値)をプッシュします. この値はmainのスタックフレームの一番下を指しています.movq %rsp, %rbp後:%rbpの値をスタック上に退避した(保存した)ので,movq %rsp, %rbpにより,%rbpが「関数fooのスタックフレームの一番下」を指すようにします.subq $32, %rspにより,fooのスタックフレームを確保しました. これでfooのスタックフレームは完成です. ここでは32バイト確保していますが,関数fooの中身によって適宜,増減します.
- 関数
fooの最後の2行(leaveとret)が 「関数fooのスタックフレーム」を破棄します.leave命令はmovq %rbp, %rsp; popq %rbpと同じ動作をします.
leave
ret
leave前:%rspと%rbpが関数fooのスタックフレームの上下を指しています.leave前半(movq %rbp, %rsp)後:%rspが関数fooのスタックフレームの一番下を指します.leave後半(popq %rbp)後: 退避しておいた「古い%rbp」をポップして%rbpに格納することで,%rbpは関数mainのスタックフレームの一番下を指します.ret後: スタックトップに戻り番地がある状態に戻ったので,ret命令で関数fooからmainにリターンします.ret命令はスタックからポップして戻り番地を取り出すので, スタック上から戻り番地が無くなります. これでスタックは関数fooを呼び出す前と同じ状態に戻りました.%rspと%rbpは関数mainのスタックフレームの上下を指しています.
caller-savedレジスタとcallee-savedレジスタ
- レジスタの数は限られているので,必要に応じて, レジスタの値はスタック上に退避(保存)する必要があります.
- その保存の仕方で,レジスタは caller-savedレジスタとcallee-savedレジスタに分類されます.これを以下で説明します.
calleeとcaller

関数Aが関数Bを呼び出す時,
- 関数Aをcaller(呼び出す側),
- 関数Bをcallee(呼び出される側),といいます.
雇用者を employer,被雇用者(雇われてる人)を employee って呼ぶのと同じ言い方ですね. デバッグする側(debugger),デバッグされる側(debuggee), テストする側(tester),テストされる側(testee)という言い方もあります.
レジスタ退避と回復
- 関数呼び出しで,レジスタの退避と回復が必要になることが良くあります. レジスタの数が有限でごく少ないからです.
- レジスタの退避・回復のやり方は大きく2種類あります:
- caller側で退避・回復: caller側でレジスタのプッシュとポップを行う
- callee側で退避・回復: callee側でレジスタのプッシュとポップを行う

LinuxのABIでの caller-savedレジスタとcallee-savedレジスタ
レジスタの退避と回復は,caller側でもcallee側でもできますが, レジスタごとにどちらでやるかを決めておくと便利です.
- caller側で退避・回復を行うレジスタをcaller-savedレジスタと呼びます
- callee側で退避・回復を行うレジスタをcallee-savedレジスタと呼びます
LinuxのABIでは 以下のように,caller-savedレジスタとcallee-savedレジスタが決まっています.
| 汎用レジスタ | |
|---|---|
| caller-savedレジスタ | %rax, %rcx, %rdx, %rsi, %rdi, %r8〜%r11 |
| callee-savedレジスタ | %rbx, %rbp, %rsp, %r12〜%r15 |
%rspのcallee側での退避・回復には,
プッシュやポップを使いませんが,
「caller側にリターンする前に元に戻す,という約束をcallee側は守る(責任がある)」
という意味で,%rspもcallee-saveレジスタになります.
関数呼び出し規約 (calling convention)
関数呼び出し規約 (calling convention)は ABIが定める「callerとcallee間のお約束」です.例えば,以下を定めます:
- 引数の渡し方 (スタック渡しかレジスタ渡しか)
- スタックフレームのレイアウト (どこに何を置くか)
- レジスタの役割
- caller-savedレジスタとcallee-savedレジスタ
- アラインメント
引数の渡し方
| 引数 | レジスタ |
|---|---|
| 第1引数 | %rdi |
| 第2引数 | %rsi |
| 第3引数 | %rdx |
| 第4引数 | %rcx |
| 第5引数 | %r8 |
| 第6引数 | %r9 |
- 第1引数〜第6引数は上記の通り,レジスタを介して渡します
- 第7引数以降はレジスタではなくスタックを介して渡します
スタックレイアウト

- 上図は典型的なスタックレイアウトです.
- 局所変数と第7以降の引数はスタック上に置きます.
スタック上の局所変数や引数は
%rbpを使ってアクセスします. 例えば,上図ではメモリ参照-16(%rbp)は局所変数2, メモリ参照24(%rbp)は第8引数への参照になります.%rbpを使う理由は, これらの絶対アドレスがコンパイル時に決まりませんが,%rbpに対する相対アドレスはコンパイル時に決まるからです. (-fomit-frame-pointerオプションが 指定された場合は,%rbpではなく%rspを使ってアクセスします). - スタックに置く局所変数や引数が8バイト未満の場合は アラインメント制約を満たすために, 隙間(パディング)を入れる必要があることがあります.
レジスタの役割
%rspと%rbpは一番上のスタックフレームの上下を指します (-fomit-frame-pointerオプションが 指定されていなければ).- (8バイト以下の整数であれば)返り値は
%raxに入れて返します. - 可変長引数の関数(例えば
printf)を呼び出す時は, 呼び出す前に%alに「使用するベクタレジスタ(例えば%xmm0)の数」を入れます.
レッドゾーン (redzone)
- レッドゾーンは
%rspレジスタの上,128バイトの領域のことです. この領域には好きに読み書きして良いことになっています.
アラインメント制約
call命令実行時に%rspレジスタは16バイト境界を満たす, つまり%rspの値が16の倍数である必要があります. これを守らないとプログラムがクラッシュすることがあるので要注意です
関数プロローグとエピローグ

- 関数本体実行前に準備を行うコードを関数プロローグ(function prologue), 関数本体実行後に後片付けを行うコードを関数エピローグ(function epilogue) といいます.
- 上図は典型的な関数プロローグとエピローグです.
- 関数プロローグでは,スタックフレームの作成, callee-saveレジスタの退避(必要があれば), (局所変数や引数のために必要な)スタックフレーム上での領域の確保, などを行います.
- 関数エピローグでは,概ね,関数プロローグの逆を行います.
callee-saveレジスタの回復の順番も,退避のときと逆になっている点に注意して下さい
(退避の時は
%rbx→%r12,回復の時は逆順で%r12→%rbx).
- コンパイラに
-O2などの最適化オプションを指定すると, 不要な命令が削られたり移動するため,プロローグとエピローグの内容が 大きく変わることがあります.
Cコードからアセンブリコードを呼び出す
// asm/mix1/main.c
#include <stdio.h>
int sub (int, int);
int main (void)
{
printf ("%d\n", sub (23, 7));
}
# asm/mix1/sub.s
.text
.globl sub
.type sub, @function
sub:
pushq %rbp
movq %rsp, %rbp
subq %rsi, %rdi
movq %rdi, %rax
leave
ret
.size sub, .-sub
$ gcc -g main.c sub.s
$ ./a.out
16
- 関数規約が守られていれば, Cからアセンブリコードの関数を呼び出したり, アセンブリコードからCの関数を呼び出すことができます.
- 上の例では関数
mainから,アセンブリコード中の関数subを呼び出しています.
アセンブリコードからCコードを呼び出す
# asm/mix2/main.s
.text
.globl main
.type sub, @function
main:
pushq %rbp
movq %rsp, %rbp
movq $23, %rdi
movq $7, %rsi
call sub
leave
ret
.size main, .-main
// asm/mix2/sub.c
int sub (int a, int b)
{
return a - b;
}
$ gcc -g main.s sub.c
$ ./a.out
$ echo $?
16
- 上の例ではアセンブリコードからCの関数を呼び出しています.
関数
subの計算結果をここでは終了ステータスとして表示しています. 関数subが計算結果を%raxに入れて返した後, 関数mainが%raxを壊さず終了したので, 引き算の結果がそのまま終了ステータスになっています. - 終了ステータスの値は関数
mainがreturnした値,またはexitの引数に渡した値です. ただし,下位1バイトしか受け取れないので,終了ステータスの値は0から255までになります.
アセンブリコードからprintfを呼び出す
# asm/printf.s
.section .rodata
L_fmt:
.string "%d\n"
.text
.globl main
.type sub, @function
main:
pushq %rbp
movq %rsp, %rbp
leaq L_fmt(%rip), %rdi
movq $999, %rsi
# pushq $888 # ❶このコメントを外すと segmentation fault になることも
movb $0, %al # ❷
call printf
leave
ret
.size main, .-main
$ gcc -g printf.s
$ ./a.out
999
- アセンブリコードから
printfなどのライブラリ関数を呼び出せます. call命令実行時には%rspの値は16の倍数で無くてはいけません (%rspのアラインメント制約). なので,❶の行のコメントを外して実行すると,segmentation fault が起きることがあります(起きないこともありますが,それはたまたまです). ❶の行のコメントを外さなければ, 「戻り番地の8バイトと古いrbpの値の8バイト」でちょうど16バイトが積まれて,%rspの値は16の倍数になります.printfは可変長引数を持つ関数なので,呼び出し前に%alにベクトルレジスタ(例%xmm0)の数を入れておく必要があります (ここではベクトルレジスタを使っていないのでゼロに設定).
アセンブラ命令
アセンブラとアセンブラ命令
- アセンブラ (assembler)はアセンブリコード (
foo.s)を オブジェクトファイル (foo.o)に変換するプログラムです.- 例えば,
gcc -c foo.sとするとアセンブルできます.gcc -cは内部でasコマンドを呼んでいて,これがアセンブラ本体です. (gccに-vオプションを付けると,asコマンドの実行が見えます).
- 例えば,
- アセンブラ命令 (assembler directive)はアセンブラへの指示です.
- 例えば,
.textはアセンブラに「出力先を.textセクションに切り替えろ」と 指示しています. - GNUアセンブラのアセンブラ命令はすべてドット
.で始まります.
- 例えば,
- アセンブラ命令はCPUが実行しない命令なので, 疑似命令(pseudo instruction)とも呼ばれます. (が,分かりにくい用語なので本書では使いません).
アセンブラ命令と機械語命令
| 例 | 何が実行 | いつ実行 | バイナリファイル中に | |
|---|---|---|---|---|
| アセンブラ命令 | .text | アセンブラ | アセンブル時 | 残らない |
| 機械語命令 | addl $5, %eax | CPU | a.out実行時 | 残る |

- アセンブラがアセンブリコード(
*.s)からオブジェクトファイル(*.o)を作る際に,- アセンブラ命令(例:
.text)に従って処理をします.例えば,addl $5, %eaxを バイト列に変換した結果0x83 0xC0 0x05を.textセクションに出力します. - その結果,アセンブラ命令
.textはオブジェクトファイルには残りません. (オブジェクトファイル中に.textセクションはありますが, これはアセンブラ命令.textではありません).
- アセンブラ命令(例:
- 一方,機械語命令
addl $5, %eaxはオブジェクトファイルに残っています (バイト列0x83 0xC0 0x05と見た目は変わっていますが).a.outを実行したときに,CPUがこの機械語命令を実行します.
アセンブラの主な仕事
概要
アセンブラの主なお仕事は大きく次の4つです.
-
機械語命令やデータを2進数表現に変換する
- 例:
pushq %raxを0x50に変換する - 例:
.string "%d\n"を0x25 0x64 0x0A 0x00に変換する (.stringは自動的にヌル文字0x00を最後に付加します) - アセンブラにとって,機械語命令もデータも 「2進数にして出力する」という意味で,どちらも単なるデータです.
- 例:
-
変換した2進数を指定されたセクションに出力する
- アセンブラは各セクションごとにロケーションカウンタ (location counter)
を持っています.ロケーションカウンタは「機械語命令やデータを次に出力する際の
アドレス」です.
.align 8は「次に出力するアドレスを8の倍数にする(次の出力を8バイト境界にする)」というアセンブラ命令ですが, ロケーションカウンタという言葉を使うと 「ロケーションカウンタを8の倍数になるように増やす」と言い換えられます.
- アセンブラは各セクションごとにロケーションカウンタ (location counter)
を持っています.ロケーションカウンタは「機械語命令やデータを次に出力する際の
アドレス」です.
-
記号表 (symbol table)を作って,ラベルをアドレスに変換する
-
最後に変換したデータをバイナリ形式(LinuxではELF形式)にしてファイル出力する
セクションへの出力
セクションとは
バイナリファイルの構造はざっくり以下の図のようになっています.
- 基本的に,バイナリ (オブジェクトファイル
*.oや実行可能ファイルa.out)は セクション (section)という単位で区切られていて,それぞれ別の目的でデータが格納されます. - ヘッダ (header)は目次の役割で「どこにどんなセクションがあるか」という情報を保持しています.
代表的なセクション
| セクション名 | 説明 |
|---|---|
.text | 機械語命令(例:pushq %rbp)を置くセクション |
.data | 初期化済みの静的変数の値(例:0x1234)を置くセクション |
.bss | 未初期化(実行時に0で初期化する)の静的変数の値を置くセクション |
.rodata | 読み込みのみ(read only)の値(例:"hello\n")を置くセクション |
各セクションに出力する例
例えば,以下のアセンブリコードfoo.sがあるとします
(.rodataセクションを指定する際は,.sectionが必要です).
# foo.s
.text # .textセクションに出力せよ
pushq %rbp
movq %rsp, %rbp
.data # .dataセクションに出力せよ
.long 0x11223344
.section .rodata # .rodataセクションに出力せよ
.string "hello\n"
このfoo.sをアセンブラが処理すると以下になります.
-
pushq %rbpを2進数にすると0x55,movq %rsp, %rbpを2進数にすると0x48 0x89 0xe5なので, これら合計4バイトを.textセクションに出力します. -
.dataは「.dataセクションに出力せよ」,.long 0x11223344は 「0x11223344を4バイトの2進数として出力せよ」という意味です.0x11223344を2進数にすると0x44 0x33 0x22 0x11なので これら4バイトを.dataセクションに出力します. (出力が逆順になっているように見えるのは x86-64がリトルエンディアンだからです.) -
.section .rodataは「.rodataセクションに出力せよ」,.string "hello\n"は 「文字列"hello\n"をASCIIコードの2進数として出力せよ」という意味です."hello\n"を2進数にすると0x68 0x65 0x6c 0x6c 0x64 0x0a 0x00なので, これら7バイトを.rodataセクションに出力します. (最後の0x00はヌル文字'\0'です.C言語では文字列定数の最後に自動的に ヌル文字が追加されますが,アセンブリ言語では必ずしもそうではありません..stringはヌル文字を自動的に追加します. 一方,(ここでは使っていませんが).asciiはヌル文字を自動的に追加しません).ASCIIコードは
man asciiで確認できます.
セクションを確認する
-
セクションの内容は
objdump -hやreadelf -Sコマンドで表示できます. -
objdump -hの例と読み方
$ gcc -g -c add5.c
$ objdump -h add5.o
add5.o: file format elf64-x86-64
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000013 0000000000000000 0000000000000000 00000040 2**0
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .data 00000000 0000000000000000 0000000000000000 00000053 2**0
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000000 0000000000000000 0000000000000000 00000053 2**0
ALLOC
3 .debug_info 00000066 0000000000000000 0000000000000000 00000053 2**0
CONTENTS, RELOC, READONLY, DEBUGGING, OCTETS
4 .debug_abbrev 0000004d 0000000000000000 0000000000000000 000000b9 2**0
CONTENTS, READONLY, DEBUGGING, OCTETS
5 .debug_aranges 00000030 0000000000000000 0000000000000000 00000106 2**0
CONTENTS, RELOC, READONLY, DEBUGGING, OCTETS
6 .debug_line 0000004f 0000000000000000 0000000000000000 00000136 2**0
CONTENTS, RELOC, READONLY, DEBUGGING, OCTETS
7 .debug_str 00000093 0000000000000000 0000000000000000 00000185 2**0
CONTENTS, READONLY, DEBUGGING, OCTETS
8 .debug_line_str 00000089 0000000000000000 0000000000000000 00000218 2**0
CONTENTS, READONLY, DEBUGGING, OCTETS
9 .comment 0000002c 0000000000000000 0000000000000000 000002a1 2**0
CONTENTS, READONLY
10 .note.GNU-stack 00000000 0000000000000000 0000000000000000 000002cd 2**0
CONTENTS, READONLY
11 .note.gnu.property 00000020 0000000000000000 0000000000000000 000002d0 2**3
CONTENTS, ALLOC, LOAD, READONLY, DATA
12 .eh_frame 00000038 0000000000000000 0000000000000000 000002f0 2**3
CONTENTS, ALLOC, LOAD, RELOC, READONLY, DATA
| 欄 | 例 | 説明 |
|---|---|---|
| Idx | 1 | セクションの通し番号 |
| Name | .text | セクションの名前 |
| Size | 00000013 | セクションのサイズ (16進数,バイト) |
| VMA | 00000000 | 実行時のセクションのアドレス (virtual memory address, 16進数) |
| LMA | 00000000 | ロード時のセクションのアドレス (load memory address, 16進数) |
| File Off | 00000040 | ファイルオフセット(16進数,バイト) |
| Algn | 2**0 | セクションのアラインメント制約(バイト), 2**nは\(2^n\)を意味 |
| 属性 | 説明 |
|---|---|
| CONTENTS | このセクションには中身がある(つまり中身が空のセクションもある) |
| ALLOC | ロード時にこのセクションのためにメモリを割り当てる必要がある |
| LOAD | このセクションは実行するためにメモリ上にロードする必要がある |
| READONLY | メモリ上では「読み込みのみ許可(書き込み禁止)」と設定する必要がある |
| CODE | このセクションは実行可能な機械語命令を含んでいる |
| RELOC | このセクションは再配置情報を含んでいる |
readelf -Sの例と読み方
$ gcc -g -c add5.c
$ readelf -S add5.o
There are 21 section headers, starting at offset 0x640:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .text PROGBITS 0000000000000000 00000040
0000000000000013 0000000000000000 AX 0 0 1
[ 2] .data PROGBITS 0000000000000000 00000053
0000000000000000 0000000000000000 WA 0 0 1
[ 3] .bss NOBITS 0000000000000000 00000053
0000000000000000 0000000000000000 WA 0 0 1
[ 4] .debug_info PROGBITS 0000000000000000 00000053
0000000000000066 0000000000000000 0 0 1
[ 5] .rela.debug_info RELA 0000000000000000 00000410
00000000000000c0 0000000000000018 I 18 4 8
[ 6] .debug_abbrev PROGBITS 0000000000000000 000000b9
000000000000004d 0000000000000000 0 0 1
[ 7] .debug_aranges PROGBITS 0000000000000000 00000106
0000000000000030 0000000000000000 0 0 1
[ 8] .rela.debug_[...] RELA 0000000000000000 000004d0
0000000000000030 0000000000000018 I 18 7 8
[ 9] .debug_line PROGBITS 0000000000000000 00000136
000000000000004f 0000000000000000 0 0 1
[10] .rela.debug_line RELA 0000000000000000 00000500
0000000000000060 0000000000000018 I 18 9 8
[11] .debug_str PROGBITS 0000000000000000 00000185
0000000000000093 0000000000000001 MS 0 0 1
[12] .debug_line_str PROGBITS 0000000000000000 00000218
0000000000000089 0000000000000001 MS 0 0 1
[13] .comment PROGBITS 0000000000000000 000002a1
000000000000002c 0000000000000001 MS 0 0 1
[14] .note.GNU-stack PROGBITS 0000000000000000 000002cd
0000000000000000 0000000000000000 0 0 1
[15] .note.gnu.pr[...] NOTE 0000000000000000 000002d0
0000000000000020 0000000000000000 A 0 0 8
[16] .eh_frame PROGBITS 0000000000000000 000002f0
0000000000000038 0000000000000000 A 0 0 8
[17] .rela.eh_frame RELA 0000000000000000 00000560
0000000000000018 0000000000000018 I 18 16 8
[18] .symtab SYMTAB 0000000000000000 00000328
00000000000000d8 0000000000000018 19 8 8
[19] .strtab STRTAB 0000000000000000 00000400
000000000000000d 0000000000000000 0 0 1
[20] .shstrtab STRTAB 0000000000000000 00000578
00000000000000c6 0000000000000000 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
D (mbind), l (large), p (processor specific)
| 欄 | 例 | 説明 |
|---|---|---|
| [Nr] | [1] | セクションの通し番号 |
| Name | .text | セクションの名前 |
| Type | PROGBITS | セクションのタイプ (以下参照) |
| Address | 0000000000000000 | セクションのアドレス |
| Offset | 00000040 | ファイルオフセット(16進数,バイト) |
| Size | 0000000000000013 | セクションのサイズ (16進数,バイト) |
| EntSize | 0000000000000000 | 表中の固定長のエントリのサイズ (エントリがない場合は0) |
| Flags | AX | セクションのフラグ (以下参照) |
| Link | 0 | 関連するセクションの通し番号([Nr]) (存在しない場合は0) |
| Info | 0 | 関連情報 (ない場合は0) |
| Align | 1 | セクションのアラインメント制約(バイト) |
| セクションのタイプ | 説明 |
|---|---|
| NULL | このセクションは使われていない |
| PROGBITS | このセクションはプログラムがフォーマットと意味を決める情報を含む |
| NOBITS | 未初期化の領域を含む (ファイル中ではサイズゼロ) |
| RELA | このセクションは再配置情報を含む (調整用の値(addend)を含む) |
| NOTE | 言語処理系が定義・使用するメモ書き |
| SYMTAB | このセクションは記号表 (symbol table) |
| STRTAB | このセクションは文字列表 (string table) |
| フラグ | 説明 |
|---|---|
| W (write) | このセクションは実行時に書き込み可能にしておく必要がある |
| A (alloc) | ロード時にこのセクションのためにメモリを割り当てる必要がある |
| X (execute) | このセクションは実行可能な機械語命令を含む |
| M (merge) | このセクション中のデータは重複を避けるためにマージ可能 |
| S (strings) | このセクションはヌル終端の文字列を含む |
| I (info) | このセクションはセクションのタイプに依存した付加情報を保持してる |
| L (link order) | このセクションはリンカに対して特別な順序を要求する |
| O (extra OS processing required) | このセクションはOS固有の特別な処理が必要である |
| G (group) | このセクションはセクショングループのメンバーである |
| T (TLS) | このセクションはスレッドローカルストレージを持つ |
| C (compressed) | このセクションの内容は圧縮されている (AやNOBITSとの併用はNG) |
| x (unknown) | このセクションは不明なセクションである |
| o (OS specific) | OS固有の意味を持つ |
| E (exclude) | このセクションは参照もメモリ割り当てもされなければ削除される |
| D (mbind) | このセクションは特別なメモリ領域に置く必要がある.Infoがそのメモリタイプを示す |
| l (large) | このセクションは(2GB以上の)largeコードモデルである |
| p (processor specific) | プロセッサ固有の意味を持つ |
readelf -tで,より詳細なセクション情報を表示可能readelf -nでNOTEセクションの内容を表示可能
記号表とアドレスへの変換
# sym-main.s
.text
.globl main
.type main, @function
main:
movl x(%rip), %eax # ラベル x の参照
ret
.size main, .-main
# sym-sub.s
.globl x
.data
.align 4
.type x, @object
.size x, 4
x: # ラベル x の定義
.long 999
$ gcc -c sym-main.s
$ gcc -c sym-sub.s
$ gcc sym-main.o sym-sub.o
$ nm sym-main.o
0000000000000000 T main
❶ U x
$ nm sym-sub.o
❷ 0000000000000000 D x
$ nm a.out | egrep ' x'
❸ 0000000000004010 D x
$ objdump -D ./a.out
0000000000001129 <main>:
1129: 8b 05 e1 2e 00 00 mov ❹ 0x2ee1(%rip),%eax # 4010 <x>
❻ 112f: c3 ret
(中略)
0000000000004010 <x>:
❺ 4010: e7 03 out %eax,$0x3
$ bc
obase=16
ibase=16
4010-112F
❼ 2EE1
- アセンブラは記号表を作り,ラベルを見つけるたびに記号表に加えます. 記号表はリンク時にも使うので,アセンブラは記号表をオブジェクトファイルに埋め込みます. 最終的に,記号表の情報を使って,ラベルをアドレスに変換します.
- 例えば,上記の例ではラベル
xを記号表で管理して,最終的にアドレス0x4010に変換しています.sym-main.sのmovl x(%rip), %eaxではラベルxが登場するので, アセンブラはラベルxを記号表に加えます.sym-main.s中には定義が無いので,nmコマンドで記号表を見ると「xは未定義 (❶ U x)」となっています.- 一方,
sym-sub.s中にラベルxの定義があるので,nmで調べると,「xの(仮の)アドレスは0番地 ❷」と表示されます. sym-main.oとsym-sub.oをリンクしたa.outを調べると, 「xのアドレスは0x4010番地 ❸」となってます.objdump -Dで(.dataセクションも含めて)逆アセンブルすると,xのアドレスは確かに❹0x4010番地となっていて,movl x(%rip), %eax中のラベルxは相対アドレス❹0x2EE1に なっています(❺ 0x4010 - ❻ 0x112F = ❼ 0x2EE1).
バイナリ形式として出力
- ここまでの処理で,アセンブラはセクション別に2進数のバイト列を生成しています.
- アセンブラはこれらのバイト列をバイナリ形式のフォーマットに従って ファイルに出力します.
- 本書の範囲ではバイナリ形式の詳細を知る必要はありませんが,
以下でELFバイナリ形式の全体の構造だけ説明します.
この知識がないと
readelfコマンドを使う際に「ヘッダが3種類ある」と混乱するからです.
ELFバイナリ形式の構造
- ELFには3種類のヘッダがあります
| ヘッダの種類 | 表示コマンド | 説明 |
|---|---|---|
| ELFヘッダ | readelf -h | ELFファイル全体の目次とメタ情報.必ずファイル先頭に存在 |
| セクションヘッダ | readelf -S | セクションの目次 |
| プログラムヘッダ | readelf -l | セグメントの目次 |

- ELFのセクションはリンクのための処理の単位です.
- ELFのセグメントは複数のセクションが1つになったもので,
実行時にメモリにロードするための処理の単位です.
- セクションと区別するために,「セグメント」という異なる名前が付いているがかえって紛らわしい.
- ELFヘッダ以外は,配置する場所や順番に決まりはないです. (セクションヘッダは(ヘッダという名前なのに)ファイルの最後に配置されることが多いです). セクションヘッダとプログラムヘッダの位置(オフセット)は ELFヘッダ中に書かれています.
ELFとDWARF
バイナリ形式 ELF は executable linkage format の略です. 「北欧神話でおなじみのエルフ(ELF)と来ればドワーフ(DWARF)も欲しいでしょ」 というダジャレで, (元々はELF形式のために)DWARFという名前のデバッグ情報形式が生まれたようです.
GNUアセンブラの文法
文

-
GNUアセンブラの文(statement)はアセンブリコードの構成要素であり, 上記の6つのいずれもが1つの文になります.
-
文は改行かセミコロン
;で区切ります.-
セミコロンで区切れば,複数の文を1行に書いて良いです. 以下はどちらでもOKです
pushq %rbp movq %rsp, %rbppushq %rbp; movq %rsp, %rbp
-
コメント
-
GNUアセンブラのコメントは(C言語と同様に)プログラムのメモ書きです. アセンブラは単に無視します.
-
行コメント: シャープ記号
#から行末までがコメントになります# これは行コメントです注: 行コメントに使う記号はアーキテクチャ依存です. 例えば,x86-64は
#ですが,ARMは@,H8は;,SPARCは!です. -
ブロックコメント: C言語と同じで
/*から*/までがコメントです. C言語と同様にブロックは入れ子禁止です(ブロックコメントの中にブロックコメントは書けません)/* これはブロックコメントです. 複数行でもOKです */ -
入れ子のコメントを書くには,C前処理命令
#if 0と#endifを使います.- ただし,ファイル拡張子を(大文字の)
.Sにする必要があります. - 拡張子を
.SにするとC前処理が実行されるので,#defineや#includeも使えます.
#if 0 これはC前処理命令を使ったコメントです. これは入れ子にできます. #endif - ただし,ファイル拡張子を(大文字の)
定数
| 種類 | 説明 | 例 |
|---|---|---|
| 10進数定数 | 0で始まらない | pushq $74 |
| 16進数定数 | 0xか0Xで始まる | pushq $0x4A |
| 8進数定数 | 0で始まる | pushq $0112 |
| 2進数定数 | 0bか0Bで始まる | pushq $0b01001010 |
| 文字定数 | '(クオート)で始まる | pushq $'J |
'(クオート)で囲む | pushq $'J' | |
\バックスラッシュでエスケープ可 | pushq $'\n | |
| 文字列定数 | "(ダブルクオート)で囲む | .string "Hello\n" |
- 上の例の最初の4つの定数は全部,値が同じです
- GNUアセンブラでは文字定数の値はASCIIコードです.
上の例では,文字
'J'の値は74です. - バックスラッシュでエスケープできる文字は,
\b,\f,\n,\r,\t,\",\\です. また\123は8進数,\x4Fは16進数で指定した文字コードになります. - 文字列定数では,
.stringと.ascizは自動的にヌル文字終端しますが,.asciiはヌル文字終端しません(必要なら明示的に\0と書く必要があります). 文字列定数は即値や変位には使えません.
式
leaq main+10(%rip), %rax # 加算
movq $1<<12, %rax # 左シフト
movq $1024*1024, %rax # 乗算
-
定数やラベルを書ける場所 (即値や変位)には式を書けます.
-
ただし,式には静的に(アセンブル時に)計算できるものだけが書けます.
- レジスタやメモリの値は参照できません.
-
上の例では加算,左シフト,乗算を使った例です.
-
単項演算子
| 演算子 | 意味 |
|---|---|
- | 2の補数による負数 |
~ | ビットごとの反転 (1の補数) |
- 2項演算子
| 演算子 | 意味 |
|---|---|
* | 乗算 |
/ | 除算 |
% | 剰余 |
<< | 左シフト |
>> | 右シフト |
| 演算子 | 意味 |
|---|---|
| | ビットOR |
& | ビットAND |
^ | ビットXOR |
! | ビットOR NOT (a | ~bと同じ) |
| 演算子 | 意味 |
|---|---|
+ | 加算 |
- | 減算 |
== | 等しい |
!= | 等しくない |
<> | 等しくない |
< | 小さい |
> | 大きい |
<= | 以下 |
>= | 以上 |
| 演算子 | 意味 |
|---|---|
&& | 論理AND |
|| | 論理OR |
- 一番上の表が最も優先度が高く,順番に下に行くほど優先度が下がります. 同じ表中の演算子同士は同じ優先度です.
- 述語演算子は,真の時は
-1(つまり全ビットが1),負の時は0(つまり全ビットが0)を返します. - 2023/9:
=が入ってる演算子を使うと,foo.s:9: Error: invalid character '=' in operand 1というエラーがでます.なぜなんだぜ
ラベルと識別子
シンボル
- シンボルはGNUアセンブラが使う一種の変数で,値を保持できます.
- GNUアセンブラのシンボル名に使える文字は英語の大文字と小文字,数字,
_,$,.です.- ただし,シンボル名は数字で始まってはいけません
- 大文字と小文字は区別します (case-sensitive)
$と.は使わない方が良いでしょう (即値やアセンブラ命令と紛らわしいから)
- シンボルは主にラベルに使います.
- ラベルはアセンブラが自動的にアドレスを割り当てます.つまり値がアドレスなシンボルがラベルです.
- アセンブラ命令
.setでシンボルの値をセットできます(あまり使いませんが)
.set x, 999 # シンボルxの値を999にする
ラベル
- シンボルの直後にコロン
:が来ると (例:add5:),それはラベルの定義になります. - そのラベルの値は
add5:を処理した時のロケーションカウンタ (次に出力するアドレス)になります. つまり,アセンブラ が自動的にラベルをアドレスに変換します. - 変換するアドレスが絶対アドレスか相対アドレスかはGNUアセンブラが自動的に判断します (例:
leaq foo(%rip), %raxのfooは相対アドレスになります) - ラベルは関数名や変数名などの識別子名 (identifier),ジャンプ先を表すために使います
- アドレスを書ける場所 (即値や変位)にはラベルを書いて良い
(例:
movq %rax, foo (%rip))
ラベルのスコープ
- 同じファイル中に同じラベル名があってはいけません(二重定義). グローバルではないラベルのスコープはそのファイル.
foo:
foo: # 二重定義でNG
- グローバルなラベルは他のファイルに同じラベル名があってもいけません. グローバルなラベルのスコープはリンクするファイルすべて.
# file1.s
.globl foo
foo:
# file2.s
.globl foo
foo: # 二重定義でNG
- 片方がweakなラベルなら二重定義でもOK
- weakラベルと同名のラベルがあれば,(エラーなしで)weakではない方のラベルが使われる
- weakラベルと同名のラベルがなければ,(エラーなしで)weakラベルが使われる
- weakラベルは「他の定義に上書きされても良い,デフォルトの関数や変数」を定義するのに便利
# file1.s
.globl foo
foo:
# file3.s
.weak foo
.globl foo
foo: # OK (二重定義にならない)
- C言語でも変数や関数をweakにできる
- GCC独自拡張機能である
__attribute__((weak))を使う
- GCC独自拡張機能である
// weak-main.c
#include <stdio.h>
__attribute__((weak)) void foo ()
{
printf ("I am weak foo\n");
}
int main ()
{
foo ();
}
// weak-sub.c
#include <stdio.h>
void foo ()
{
printf ("I am non-weak foo\n");
}
$ gcc -g weak-main.c
$ ./a.out
I am weak foo
$ gcc -g weak-main.c weak-sub.c
$ ./a.out
I am non-weak foo
記号表に含まれないラベル (.Lで始まるラベル)
// label.s
.text
.global foo1
foo1:
foo2:
.Lfoo3:
$ gcc -g -c label.s
$ nm label.o
0000000000000000 T foo1
0000000000000000 t foo2
- ELFバイナリの場合,
.Lで始まるラベルは記号表に含まれません. - コンパイラが出力するジャンプ先のラベルは
.Lで始まることが多いです (例:.LFB0,.LFE0,.L2). ジャンプ先のラベルはデバッグ等に不要なことが多いからです. - 上の例で
.Lfoo3は記号表に含まれないため,nmコマンドで出力されませんでした.
特別なドットラベル .
-
ドット
.は特別なラベルで,ロケーションカウンタ自身(つまり現在のアドレス)を表します. -
例:
fooの中身はfooのアドレスになりますfoo: .quad .foo: .quad foo # こう書いても同じ -
例:
.-add5は現在のアドレスからadd5のアドレスを引くので, 「関数add5の先頭から現在のアドレスまでの,機械語命令のバイト数」が計算できます.size add5, .-add5
数値ラベル

- 数値ラベル = 正の整数にコロン
:がついたもの - 数値ラベルは再定義が可能 (2重定義にならない)
- 参照時には
fかbを付けるb(backward)は後方で最初の同名のラベルを参照f(forward)は前方で最初の同名のラベルを参照
- インラインアセンブリコードで使うと 2重定義を気にせず使えるので便利.
変数名とラベル
int x1 = 111;
int main ()
{
}
.globl x1
.data
.align 4
.type x1, @object
.size x1, 4
x1:
.long 111
- 静的な変数
x1はそのままアセンブリコードのラベルx1になります. ラベルx1の値は「変数x1の実体が置かれるメモリ領域の先頭番地」になります.
// var2.c
void foo ()
{
static int x2 = 222;
}
int main ()
{
static int x2 = 333;
}
.data
.align 4
.type x2.1, @object
.size x2.1, 4
x2.1:
.long 222
.align 4
.type x2.0, @object
.size x2.0, 4
x2.0:
.long 333
- 関数内の静的変数
x2は,同名の変数と区別するため,コンパイラがx2.0,x2.1と数字を付け足しています.
.text
.globl main
.type main, @function
main:
-
関数
mainもそのままアセンブリコードでラベルmainになります. ラベルmainの値は「関数mainの実体が置かれるメモリ領域の先頭番地」になります. -
staticではない局所変数(自動変数)は記号表には含まれません.- 同じ関数が呼ばれるたびに,局所変数の実体がスタック上で確保されるため, アドレスが1つに確定しないからです.
- 局所変数はコンパイル時にベースポインタ (
%rbp)やスタックポインタ (%rsp)との 相対アドレスが確定します.局所変数はこの相対アドレスを使ってアクセスします.
アセンブラ命令
アセンブラ命令の種類
| 種類 | 例 | 意味 |
|---|---|---|
| セクション指定 | .text | 出力先を.textセクションにせよ |
| データ出力 | .long 0x12345678 | 4バイトの整数値0x12345678の2進数表現を出力せよ |
| 出力アドレス調整 | .align 4 | 4バイト境界にアラインメント調整せよ (4の倍数になるようにロケーションカウンタを増やせ) |
| シンボル情報 | .globl main | シンボルmainをグローバルとせよ |
| その他 | .ident "GCC.." | (ELF形式の場合)文字列"GCC.."を.commentセクションに出力する |
アセンブラ命令.identで指定した情報が,
本当にバイナリ中の.commentセクションに入ってるかを確認します.
.ident "GCC: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0"
確認にはここではobjdumpコマンドを使います.
$ objdump -s -j .comment ./a.out
./a.out: file format elf64-x86-64
Contents of section .comment:
0000 4743433a 20285562 756e7475 2031312e GCC: (Ubuntu 11.
0010 342e302d 31756275 6e747531 7e32322e 4.0-1ubuntu1~22.
0020 30342920 31312e34 2e3000 04) 11.4.0.
-j .commentは「.commentセクションだけを出力せよ」,
-sは「出力するセクションの中身をすべてダンプする」という指示です.
確かに.commentセクションに入っていました.
セクション指定
| アセンブラ命令 | 例 | 説明 |
|---|---|---|
.text | .text | 出力先を.textセクションに変更 |
.data | .data | 出力先を.dataセクションに変更 |
.bss | .bss | 出力先を.bssセクションに変更 |
.section セクション名 | .section .rodata | 出力先を指定したセクション名に変更 |
| セクション | 役割 |
|---|---|
.text | 機械語命令列を保持 |
.data | 初期化済みの静的変数を保持 |
.bss | 未初期化の静的変数を保持 |
.rodata | 読み込みのみ(書き込み禁止)データを保持 (例: Cの文字列定数) |
- アセンブラ命令
.textや.dataなどは何度でも指定できます
Cの変数とセクションの対応
// var3.c
int x1 = 10; // コンパイル時に.dataセクションに確保
int x2; // コンパイル時に.bssセクションに確保
static int x3 = 10; // コンパイル時に.dataセクションに確保
static int x4; // コンパイル時に.bssセクションに確保
extern int x5; // 何も確保しない
int main (void)
{
int y1 = 10; // 実行時にスタック上に確保
int y2; // 実行時にスタック上に確保
static int y3 = 10; // コンパイル時に.dataセクションに確保
static int y4; // コンパイル時に.bssセクションに確保
extern int y5; // 何も確保しない
}
$ gcc -g var3.c
$ nm ./a.out
0000000000001129 T main
0000000000004010 D x1
0000000000004020 B x2
0000000000004014 d x3
0000000000004024 b x4
0000000000004018 d y3.0
0000000000004028 b y4.1
| シンボルタイプ | 説明 |
|---|---|
| T | .textセクション中のシンボル(関数名) |
| D | .dataセクション中のシンボル |
| B | .bssセクション中のシンボル |
| U | 参照されているが未定義のシンボル |
- 初期化済みの静的変数は
.dataセクションに置かれます - 未初期化の静的変数は
.bssセクションに置かれます - 大文字のシンボルタイプはグローバルスコープ,小文字はファイルスコープを表します
extern int x5;は「x5の型はintだよ」とコンパイラに伝えるだけなので,実体は確保しません(念のため)
データ配置
| アセンブラ命令 | 例 | 説明 |
|---|---|---|
.byte 式, ... | .byte 0x11, 0x22 | 1バイトデータを2つ (0x11と0x22)出力 |
.word 式, ... | .word 0x11 | 0x11を2バイトデータとして出力 |
.long 式, ... | .long 0x11 | 0x11を4バイトデータとして出力 |
.quad 式, ... | .quad 0x11 | 0x11を8バイトデータとして出力 |
| `.string" 文字列, ... | .string "hello" | 文字列"hello"を出力(ヌル文字を付加する) |
| `.ascii" 文字列, ... | .ascii "hello\0" | 文字列"hello\0"を出力(ヌル文字を付加しない) |
| `.asciz" 文字列, ... | .asciz "hello" | 文字列"hello"を出力(ヌル文字を付加) |
| `.fill データ数,サイズ,値 | .fill 10, 8, 0x1234 | 0x1234を8バイトデータとして10個出力(サイズと値は省略可能.省略時はそれぞれ1と0になる) |
出力アドレス調整 (アラインメント)
| アセンブラ命令 | 例 | 説明 |
|---|---|---|
.align 式 | .align 8 | 出力先アドレスを8バイト境界にせよ (ロケーションカウンタを8の倍数に増やせ) |
.p2align 式 | .p2align 3 | 出力先アドレスを\(2^3=8\)バイト境界にせよ |
.space 式 | .space 3 | ロケーションカウンタを3増やせ (.skipでも同じ) |
.zero 式 | .zero 3 | 3バイトのゼロを出力せよ |
.org 式 | .org 510 | ロケーションカウンタを510にせよ(増やす方向のみ) |
.p2alignのp2は「2のべき乗 (power of 2)」を意味します.
シンボル情報
| アセンブラ命令 | 例 | 説明 |
|---|---|---|
.globl シンボル | .globl foo | シンボルfooをグローバルにせよ |
.type シンボル, 型 | .type main, @function | シンボルmainの型は関数とせよ |
.size シンボル, サイズ | .size main, .-main | シンボルmainのサイズを.-mainの計算結果(単位はバイト)とせよ |
.local シンボル | .local foo | シンボルfooをローカルにせよ |
.comm シンボル, サイズ, アラインメント | .comm foo, 4, 4 | .bssセクションにシンボルfooを作成せよ(サイズは4バイト,アラインメントは4バイト境界で) |
-
.typeでは型を@function(関数)か@object(普通のデータ)で指定します. (ELFの仕様によれば,@section,@file,@notypeなども使えます.これらはreadelf -sの出力にシンボルの型として出てきます). -
.commについて補足します.int x; // グローバル変数に対して,
gcc -Sは.globl x .bss .align 4 .type x, @object .size x, 4 x: .zero 4というアセンブリコードを出力します.一方,
static int y;に対して,
gcc -Sは# ❶ .bss .align 4 .type y, @object .size y, 4 y: .zero 4ではなく
# ❷ .local y .comm y,4,4を出力します(
.localが必要なのは.localが無いと.commで指定したシンボルがグローバルになってしまうからです)..comm y,4,4の最初の4は定義するyのサイズが4,次の4はアラインメント制約が4バイトであることを示しています. 実は❶と❷は全く同じ意味なのです(なのでグローバル変数の場合と統一して,❶を出力してくれた方が分かりやすくて良いと思うのですが…).
# var4.s
.data
.bss
.align 4
.type x, @object
.size x, 4
x:
.zero 4
.local y
.comm y,4,4
.text
.globl main
.type main, @function
main:
endbr64
ret
.size main, .-main
$ gcc -g var4.s
$ readelf -s ./a.out
symbol table '.symtab' contains 37 entries:
Num: Value Size Type Bind Vis Ndx Name
(中略)
12: 0000000000004014 4 OBJECT LOCAL DEFAULT 24 x ❸
13: 0000000000004018 4 OBJECT LOCAL DEFAULT 24 y ❹
$ nm ./a.out
(中略)
0000000000004014 b x ❺
0000000000004018 b y ❻
念のため,readelf -sとnmで記号表の中身を比べると❸〜❻は全く同じになりました.
AT&T形式とIntel形式
コマンド等での選択
gccでは,-masm=att(デフォルト),-masm=intelで出力するアセンブリコードの形式を選択可能です
$ gcc -S -masm=intel add5.c
$ cat add5.s
.intel_syntax noprefix
.text
.globl add5
.type add5, @function
add5:
push rbp
mov rbp, rsp
mov DWORD PTR -4[rbp], edi
mov eax, DWORD PTR -4[rbp]
add eax, 5
pop rbp
ret
.size add5, .-add5
-
アセンブリコード中では,アセンブラ命令
.att_syntax(デフォルト)と.intel_syntaxで,どちらの記法を使うか選択可能です -
objdump -dで逆アセンブルする際は,-M att(デフォルト)と-M intelで選択可能です.
$ objdump -d -M intel add5.o
add5.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <add5>:
0: f3 0f 1e fa endbr64
4: 55 push rbp
5: 48 89 e5 mov rbp,rsp
8: 89 7d fc mov DWORD PTR [rbp-0x4],edi
b: 8b 45 fc mov eax,DWORD PTR [rbp-0x4]
e: 83 c0 05 add eax,0x5
11: 5d pop rbp
12: c3 ret
AT&T形式とIntel形式の主な違い
- オペランドの順序,即値,レジスタの表記が異なります
| AT&T形式での例 | Intel形式での例 | 説明 | |
|---|---|---|---|
| オペランドの代入の順序 | addq $4, %rax | add rax, 4 | AT&T形式では左→右 Intel形式では右→左に代入 |
| 即値の表記 | pushq $4 | push 4 | AT&T形式では即値に$がつく |
| レジスタの表記 | pushq %rbp | push rbp | AT&T形式ではレジスタに%がつく |
- オペランドのサイズ指定方法が異なります
- AT&T形式では命令サフィックス(例えば,
movbのb)で指定します - Intel形式では
BYTE PTRなどの記法を使います
- AT&T形式では命令サフィックス(例えば,
| AT&T形式の サイズ指定 | Intel形式の サイズ指定 | メモリオペランドの サイズ | AT&T形式での例 | Intel形式での例 |
|---|---|---|---|---|
b | BYTE PTR | 1バイト(8ビット) | movb $10, -8(%rbp) | mov BYTE PTR [rbp-8], 10 |
w | WORD PTR | 2バイト(16ビット) | movw $10, -8(%rbp) | mov WORD PTR [rbp-8], 10 |
l | DWORD PTR | 4バイト(32ビット) | movl $10, -8(%rbp) | mov DWORD PTR [rbp-8], 10 |
q | QWORD PTR | 8バイト(64ビット) | movq $10, -8(%rbp) | mov QWORD PTR [rbp-8], 10 |
- メモリ参照の記法が違います
| AT&T形式 | Intel形式 | 計算されるアドレス | |
|---|---|---|---|
| 通常のメモリ参照 | disp (base, index, scale) | [base + index * scale + disp] | base + index * scale + disp |
%rip相対参照 | disp (%rip) | [rip + disp] | %rip + disp |
-
一部の機械語命令のニモニックが違います
- 変換系の命令
記法(AT&T形式) 記法(Intel形式) 何の略か 動作 c␣t␣c␣␣␣convert ␣ to ␣ %rax(または%eax,%ax,%al)を符号拡張
詳しい記法
(AT&T形式)詳しい記法
(Intel形式)例 例の動作 サンプルコード cbtwcbwcbtw%al(byte)を%ax(word)に符号拡張cbtw.s cbtw.txt cwtlcwdecwtl%ax(word)を%eax(long)に符号拡張cbtw.s cbtw.txt cwtdcwdcwtd%ax(word)を%dx:%ax(double word)に符号拡張cbtw.s cbtw.txt cltdcdqcltd%eax(long)を%edx:%eax(doube long, quad)に符号拡張cbtw.s cbtw.txt cltqcdqecltd%eax(long)を%rax(quad)に符号拡張cbtw.s cbtw.txt cqtocqocqto%rax(quad)を%rdx:%rax(octuple)に符号拡張cbtw.s cbtw.txt
- ゼロ拡張,符号拡張の命令
記法(AT&T形式) 記法(Intel形式) 何の略か 動作 movs␣␣op1, op2movsxop2, op1movsxdop2, op1move with sign-extention op1を符号拡張した値をop2に格納 movz␣␣op1, op2movzxop2, op1move with zero-extention op1をゼロ拡張した値をop2に格納
詳しい記法 例(AT&T形式) 例(Intel形式) 例の動作 サンプルコード movs␣␣r/m, rmovslq %eax, %rbxmovsxd rbx,eax%rbx=%eaxを8バイトに符号拡張した値movs-movz.s movs-movz.txt movz␣␣r/m, rmovzwq %ax, %rbxmovzx rbx,ax%rbx=%axを8バイトにゼロ拡張した値movs-movz.s movs-movz.txt
␣␣に入るもの何の略か 意味 bwbyte to word 1バイト→2バイトの拡張 blbyte to long 1バイト→4バイトの拡張 bqbyte to quad 1バイト→8バイトの拡張 wlword to long 2バイト→4バイトの拡張 wqword to quad 2バイト→8バイトの拡張 lqlong to quad 4バイト→8バイトの拡張
インラインアセンブラ
インラインアセンブラの概要

-
インラインアセンブラ (inline assembler)はコンパイラの機能の一部であり, 高級言語(例えばC言語)中にアセンブリコードを記述する(埋め込む)ことを可能にします
- 埋め込んだC言語中のアセンブリコードをインラインアセンブリコードといいます
-
なるべく(アセンブリコードだけで記述するのではなく),C言語中でインラインアセンブラを使うべきです
- アセンブリコードの生産性・保守性・移植性は非常に低いからです
- インラインアセンブラを使えば「大半のコードはC言語で記述し,どうしてもアセンブリコードが必要な部分だけインラインアセンブラを使って書く」ことで,アセンブリコードの記述量を減らせます
- この資料では,Linuxカーネルのアセンブリコードは 0.8% で,ほとんどがC言語だそうです (ただし,Cコード中のインラインアセンブリコードは正しくカウントされていないかも知れません)
-
GCCではasm構文を使ってインラインアセンブリコードを記述します
-
例:
nop命令を埋め込んだ例.実行しても何も起きないのであまり意味はないです. これは基本asm構文の例です.// inline-asm1.c (基本asm構文の例) int main (void) { asm ("nop"); }$ gcc -g inline-asm1.c $ ./a.out (何も起きない) -
例: スタックポインタ
%rspの値を変数addrに格納して表示する例. これはC言語だけでは書けないので意味があります. これは拡張asm構文の例です.// inline-asm2.c (拡張asm構文の例) #include <stdio.h> int main (void) { void *addr; asm volatile ("movq %%rsp, %0": "=m"(addr)); printf ("rsp = %p\n", addr); }$ gcc -g inline-asm2.c $ gdb ./a.out (gdb) b main Breakpoint 2 at 0x555555555175: file foo.c, line 3. (gdb) r Breakpoint 2, main () at foo.c:3 3 { (gdb) n 5 asm ("movq %%rsp, %0": "=m"(addr)); (gdb) n 6 printf ("rsp = %p\n", addr); (gdb) p/x $rsp $2 = 0x7fffffffdee0 ❶ (gdb) c Continuing. rsp = 0x7fffffffdee0 (printfの出力.❶の%rspの値と同じになっている) (gdb) q
-
-
インラインアセンブラの機能はC言語規格ではなく,コンパイラの独自拡張です.
- インラインアセンブラの記法はコンパイラごとに異なります
gcc -std=c11 -pedanticなど,言語規格への遵守を強くするオプションを指定すると,コンパイルエラーになることがあります.asmを__asm__にすればコンパイルできる場合もあります.
__asm__は予約識別子
「_と大文字」あるいは「__(下線2つ)と小文字」で始まる識別子(名前)は
予約識別子 (予約語とは別のものです)と呼ばれ,
言語処理系が定義するための名前です.
__asm__も予約識別子なので,アプリケーションプログラムが定義することはできず,
二重定義を避けられるというわけです.
(二重定義を避けられても,asm構文がGCCの独自拡張であり,
C言語規格には違反であることは同じですが…)
- インラインアセンブラの使い方の注意(概要): コンパイラの最適化の影響をなるべく避けるため,以下に注意:
- なるべく,基本asm構文ではなく拡張asm構文を使う
- 拡張asm構文には修飾子
volatileを必ず付ける - なるべくまとめて,1つの拡張asm構文で記述する
- 必要なら
gcc -Sで出力したアセンブリコードを(意図通りにasm構文が展開されているかを)確認する - 必要なら「人工的な変数の依存関係」を導入する
- コンパイラの最適化により,拡張asm構文が移動させられたり,場合によっては
消去される可能性があります.なので
gcc -Sで出力を確認する必要があるのです.
基本asm構文
-
基本asm構文は以下の形式です
asm 修飾子 ( "アセンブリコード" ); -
以下は
nop命令のみを基本asm構文で指定した例です.asm ("nop"); -
基本asm構文では(拡張asm構文でも)機械語命令以外に,ラベル定義,アセンブラ命令,コメントも書けます.
asm ("foo: .text; nop # this is a comment"); -
修飾子は
volatileとinlineを指定可能です
| 修飾子 | 説明 |
|---|---|
volatile | (ある程度)最適化を抑制する (基本asm構文では指定しなくても volatileとみなされる) |
inline | この基本asm構文を含む関数がインライン化されやすい ようにasm構文中の機械語命令のバイト数を少なく見積もる |
-
アセンブリコードを指定する文字列中では生の改行文字を入れてはいけません(
\nなら良い)-
まず,最適化の影響を避けるため,なるべく1つのasm構文にまとめるべきです. 最適化がasm構文を移動したり削除したりすることがあるからです.
// 良くない例 (1つのasm構文にまとめるべき) asm ("nop"); asm ("nop"); asm ("nop"); -
まとめる際は見やすさのため,各行ごとに文字列定数に分割した上で改行するの良いですし,これが最もお勧めです.
// OK & お勧め asm ("nop\n\t" "nop\n\t" "nop\n\t");- カンマで区切られていない文字列定数の並び
(ここでは
"nop\n\t" "nop\n\t" "nop\n\t") はコンパイルの初期段階で1つの文字列として連結され,"nop\n\tnop\n\tnop\n\t"になります. \tは無くてもOKです.出力されたアセンブリコードのインデントのためにつけています.
- カンマで区切られていない文字列定数の並び
(ここでは
-
文字列定数の途中で改行してはいけません. (文字列定数の途中で改行するとコンパイルエラーになります)
// NG (コンパイルエラー) asm ("nop nop nop");
-
-
基本asmコードはCのコードと協調(例: Cの変数へのアクセス)ができません. → 拡張asm構文を使え
// inline-bad.c
#include <stdio.h>
long x = 111;
long y = 222;
int main ()
{
asm ("movq x(%rip), %rax; addq %rax, y(%rip)");
printf ("x = %ld, y = %ld\n", x, y);
}
$ gcc -g inline-bad.c
$ ./a.out
x = 111, y = 333
上記のように基本asm構文でも無理やりCの変数xやyにアクセスできますが(これは悪い例),
「コンパイラが変数xをx(%rip)として出力する」ことを大前提にしたコードです.つまり「たまたま動いている」だけです.
このため,多くの場合,基本asm構文ではなく拡張asm構文を使うべきです.
上記の例を拡張asm構文で書き直すと以下になります.
("+rm"の+は指定した変数y(%0)が,読み書きの両方で使われていることを示し,
"rm"は「レジスタかメモリ参照として展開せよ」という指示(制約)です).
// inline-good.c
#include <stdio.h>
long x = 111;
long y = 222;
int main ()
{
asm volatile ("movq %1, %%rax; addq %%rax, %0"
: "+rm" (y) // 変数yのアセンブリコードを%0で展開
: "rm" (x) // 変数xのアセンブリコードを%1で展開
: "%rax" // レジスタ%raxの破壊の存在をコンパイラに伝達
);
printf ("x = %ld, y = %ld\n", x, y);
}
- その他の注意点
- 基本asm構文は関数内と関数外の両方で使える(拡張asm構文は関数内のみ)が,
関数外で使う場合は
volatileもinlineも付けてはいけない. - asm構文から他のasm構文へのジャンプはしてはいけない. (拡張asm構文ならCのラベルへのジャンプはしても良い).
- asm構文をGCCが複製する可能性があり(ループ展開とかで),その結果,
シンボルの2重定義などが起こる可能性がある.これを避けるには
%=を使う(ここでは詳細省略) - 基本asm構文ではアセンブリコードをそのまま出力する.レジスタ名も
%rspをそのまま出力する.一方,拡張asm構文中は%を特別扱いするので,%%rspと書く必要があるので注意 (printfのフォーマット中で%を出力するために%%と書くのと同じ). - 基本asm構文は
-masmで指定された方言に従うので,asm ("pushq $99");はgcc -masm=intelとするとコンパイルエラーになる.
- 基本asm構文は関数内と関数外の両方で使える(拡張asm構文は関数内のみ)が,
関数外で使う場合は
拡張asm構文
拡張asm構文の例 (引数を%順番で指定)
// inline-asm2.c (拡張asm構文の例)
#include <stdio.h>
int main (void)
{
void *addr;
asm volatile ("movq %%rsp, %0": "=m"(addr));
printf ("rsp = %p\n", addr);
}

-
拡張asm構文はコロン
:で区切られた引数 (この場合は"=m" (attr))を持ちます. 引数は対応するアセンブリコードに変換した上で,%0などの部分を展開します.- 引数が複数個ある場合は,先頭から順番に
%0,%1,%2, ... と参照します.
- 引数が複数個ある場合は,先頭から順番に
-
上の例ではCの変数
addrを対応するメモリ参照-16(%rbp)に変換して,%0の場所に展開しています.- 拡張asm構文の第1引数(命令テンプレート)中の
%0などは展開対象です. つまり,%は特別扱いしています.%文字自体を使うには%%とする必要があります. このため,レジスタ%rspは命令テンプレート中で%%rspとなっています. "=m"はアセンブリコードに変換する際の指示(制約)です.=は出力,mはメモリ参照として展開せよという意味になります.
- 拡張asm構文の第1引数(命令テンプレート)中の
拡張asm構文の例 (引数を%名前で指定)
// inline-asm3.c
#include <stdio.h>
int main (void)
{
void *addr;
asm volatile ("movq %%rsp, %[addr]": [addr] "=m"(addr));
printf ("rsp = %p\n", addr);
}
- 展開する場所(例:
%0)は順番だけでなく名前でも指定できます. - 上の例では変数
addrに,[addr]とすることでaddrという名前をつけて, 命令テンプレート中で%[addr]と参照しています.- ここではたまたま変数名
addrと名前addrを同じにしましたが,別にしてもOKです "=m (addr)"のaddrの部分には変数だけでなくC言語の式を書けます
- ここではたまたま変数名
拡張asm構文の例 (グルーコードが生じる例)
- グルーコードが生じる例 (単純な例)
// inline-asm4.c
#include <stdio.h>
int main (void)
{
void *addr;
asm volatile ("movq %%rsp, %0": "=r"(addr));
printf ("rsp = %p\n", addr);
}
$ gcc -S inline-asm4.c
$ cat inline-asm4.s
(中略)
#APP
# 6 "inline-asm4.c" 1
❶ movq %rsp, %rax
# 0 "" 2
#NO_APP
❷ movq %rax, -8(%rbp)
-
inline-asm2.cの制約"=m"(メモリ参照)を"=r"(レジスタ)に変更してみます.すると, 制約の指定がレジスタなので,%0は❶%raxに展開されました. しかし,最終的な格納先である変数addrはメモリ (-8(%rbp))だったので, ❷movq %rax, -8(%rbp)が追加され,変数addrに代入されるようになりました. -
この追加された命令❷をグルーコード(glue code)といいます. グルーは接着剤という意味です. グルーコードはCのコードとインラインアセンブリコードの間の隙間を 接着する役割を担ってます.
-
この場合,制約を
=rと指定した結果,inline-asm2.cでは不要だった グルーコードが増えてしまいました.制約はなるべく緩く指定して, コンパイラに最適な出力を任せる方が良いことが多いでしょう. この場合は,レジスタでもメモリでも良いので,"rm"と指定するのが最適だと思います.
グルーコードが生じる例 (rdtscpの例)
// rdtscp.c
#include <stdio.h>
#include <stdint.h>
uint64_t rdtscp (void) {
uint64_t hi, lo;
uint32_t aux;
asm volatile ("rdtscp":"=a"(lo), "=d"(hi), "=c"(aux));
printf ("processor ID = %d\n", aux);
return ((hi << 32) | lo);
}
int main (void) {
printf ("%lu\n", rdtscp ());
}

$ gcc -S rdtscp.c
$ less rdtscp.s
(一部略)
#APP
# 8 "rdtscp.c" 1
rdtscp
# 0 "" 2
#NO_APP
❶ movq %rax, -16(%rbp)
❷ movq %rdx, -8(%rbp)
❸ movl %ecx, -20(%rbp)
rdtscp命令には明示的なオペランドは無く, 64ビットのタイムスタンプカウンタの値を%edx:%eaxに格納します. (そしてプロセッサIDを%ecxに格納します).gcc -Sの出力を見ると,rdtscp命令に加えてグルーコード❶❷❸が追加されています.- ❶❷❸は
rdtscp命令がレジスタに格納した値を変数hi,lo,auxに 格納しています.
- ❶❷❸は
拡張asm構文の形式
-
拡張asm構文の形式は次の2種類があります. 以下ではコロン
:の手前で改行していますが,これは見やすさのためだけで, 1行で書いても構いません.asm 修飾子 (命令テンプレート : 出力オペランド列 : 入力オペランド列 # 省略可能 : 破壊レジスタ列 # 省略可能 );asm 修飾子 (命令テンプレート : 出力オペランド列 : 入力オペランド列 : 破壊レジスタ列 : gotoラベル列 );-
最初の形式の修飾子には
gotoを含んではいけません. 2番目の形式の修飾子にはgotoを含めなくてはいけません. -
最初の形式の場合,出力オペランド列より後は(不要なら)省略可能です.
: 入力オペランド列を省略した場合は,: 破壊レジスタ列も省略しなければいけません. 途中に空の部分がある場合はasm ("nop":::"%rax");などとコロン:を並べます. 一方,2番目の形式では省略できません. -
拡張asm構文は関数中でのみ使えます.関数の外では使えません.
-
修飾子は以下を指定可能です.
修飾子 説明 volatile(ある程度)最適化を抑制する (拡張asm構文には常に指定を推奨) inlineこの基本asm構文を含む関数がインライン化されやすい
ようにasm構文中のasm命令(バイト数)を少なく見積もるgoto命令オペランド中から「gotoラベル列」中のCラベルにジャンプする可能性を示す
(gotoを指定すると,volatileの指定なしでもvolatileになる)- ○○列の中身が複数ある場合はカンマ
,で区切ります.
-
-
拡張asm構文の例 (
goto無し)
// inline-asm5.c
#include <stdio.h>
int main (void)
{
int x = 111, y = 222, z;
// z = x + y;
asm volatile ("movl %1, %%eax; addl %2, %%eax; movl %%eax, %0"
: "=rm" (z)
: "rm" (x), "rm" (y)
: "%eax" );
printf ("x = %d, y = %d, z = %d\n", x, y, z);
}

- 命令テンプレート中の
%0,%1,%2は出力オペランド列と入力オペランド列中のz,x,yに対応します.- 名前を使うと,順番ではなく,
%[z],%[x],%[y]と名前での参照も可能です.
- 名前を使うと,順番ではなく,
- 例えば,出力オペランド列中の
"=rm" (z)は1つの出力オペランドです."=rm"は制約を示していて,"="はこのオペランドが出力であること,"rm"はこのオペランドをレジスタかメモリ参照として%0を展開することを指示しています. - 命令テンプレート中で値を破壊するレジスタは「破壊レジスタ列」で指定する.
- この指定が無いとコンパイラは「命令テンプレート中でどのレジスタが破壊されるか」が分からないからです.コンパイラが気づかず同じレジスタを使うと, 命令テンプレート中のレジスタ書き込みにより,値が壊れてしまいます.
- 出力オペランド列で指定したレジスタは破壊レジスタ列で指定する必要はありません
-
特別な記法として,メモリの値を壊す場合は "memory", フラグレジスタの値を壊す場合は "cc" を「破壊レジスタ列」に指定する.
-
コンパイラは必要に応じて,命令テンプレートの前に「レジスタの値をメモリに退避(書き戻し)」,命令テンプレートの後に「メモリの値をレジスタに復帰させる」コードを追加します
-
拡張asm構文の例 (
gotoあり)
// inline-asm6.c
#include <stdio.h>
int add (unsigned char arg1, unsigned char arg2)
{
asm goto ("addb %1, %0; jc %l[overflow]" // ❷ %l3 でも可
: "+rm" (arg2)
: "rm" (arg1)
:
: overflow ); // ❶
return arg2;
overflow:
printf ("overflow: arg1 = %d, arg2 = %d\n", arg1, arg2);
return arg2;
}
int main (void)
{
printf ("result = %d\n", add (254, 1));
printf ("result = %d\n", add (255, 1));
}
$ gcc -S inline-asm6.c
$ cat inline-asm6.c
(中略)
movl %edi, %edx
movl %esi, %eax
movb %dl, -4(%rbp)
movb %al, -8(%rbp)
movzbl -8(%rbp), %eax
#APP
# 5 "inline-asm6.c" 1
addb -4(%rbp), %al; jc .L2
# 0 "" 2
#NO_APP
(中略)
.L2:
$ gcc -g inline-asm6.c
$ ./a.out
result = 255
overflow: arg1 = 255, arg2 = 0
result = 0
-
命令テンプレート中からCラベルにジャンプする可能性がある場合,
goto付きの拡張asm構文を使う必要があります. その場合はジャンプする可能性があるCのラベルを「gotoラベル列」に列挙します(ダブルクオート"では囲みません). -
上の例では,❶「gotoラベル列」に
overflowを指定しています. 命令テンプレート中でラベルを参照するには次のどちらかを使います.- 引数の順番を使う: "+"は入出力で1回ずつ出現すると数えるので,
出力オペランドが1つ (
%0),入力オペランドが2つ(%1,%2)になるので, ラベルoverflowは(0から数えて)3番目になります.頭に%l(%と小文字のエル)をつけて,%l3とします. - 引数の名前を使う:
%lとラベル名で,❷%l[overflow]とします.
- 引数の順番を使う: "+"は入出力で1回ずつ出現すると数えるので,
出力オペランドが1つ (
-
ある実行パスで出力を設定しない場合,入力でも出力でも使われないことになり, 出力コードがおかしくなることがあるそうです (マニュアルによると).その場合は制約
+を使って,必ず入力として使うと指定すれば大丈夫だそうです(試してません).
出力オペランド列と入力オペランド列
- 出力オペランド列と入力オペランド列はどちらも以下の形式になります
"制約文字列" (Cの式), "制約文字列" (Cの式), …
- 「Cの式」は変数を指定することが多いですが,一般的なCの式でもOKです. ただし,出力オペランドの場合は「Cの式」は左辺値(アドレスを持つ式)でなければいけません.
- 使用できる制約文字列は次の節で示します.
制約
制約の一覧表
代表的な制約を以下に示します. 他の制約はGCCインラインアセンブラを参照下さい.
- 入出力を指定する制約
| 制約 | 説明 |
|---|---|
= | オペランドは出力専用(指定するなら必ず1文字目) |
+ | オペランドは入出力(指定するなら必ず1文字目) |
| (指定なし) | オペランドは入力専用 |
- 汎用の制約
| 制約 | 説明 |
|---|---|
r | オペランドはレジスタ |
m | オペランドはメモリ |
i | オペランドは整数即値 |
g | オペランドは制約無し ("rmi"と同じ) |
& | オペランドは早期破壊レジスタ |
0 | マッチング制約 (1〜9も同じ) |
% | オペランドは交換可能(可換) 書き込みオペランドには指定不可 |
-
x86用の制約 (レジスタ)
制約 説明 a%rax,%eax,%ax,%alのいずれかb%rbx,%ebx,%bx,%blのいずれかc%rcx,%ecx,%cx,%clのいずれかd%rdx,%edx,%dx,%dlのいずれかD%rdi,%edi,%di,%dilのいずれかS%rsi,%esi,%si,%silのいずれかA制約 a,dのいずれかQ制約 a,b,c,dのいずれかq任意の整数レジスタ ( %rspと%rbpは使わない)Ucaller-savedレジスタ q制約は,-fomit-frame-pointerオプションをgccに付けると%rbpを使用する (%rbpが汎用レジスタとして使えるようになるため)
- x86用の制約 (定数)
| 制約 | 説明 |
|---|---|
I | 範囲0〜31の整数 (32ビットシフト用) |
J | 範囲0〜63の整数 (64ビットシフト用) |
K | 範囲-128〜127の整数 (符号あり8ビット整数定数用) |
L | 0xFF, 0xFFFF, 0xFFFFFFFF (マスク用) |
M | 0, 1, 2, 3 (メモリ参照のスケール用) |
N | 範囲0〜255の整数 (in, out命令用)) |
制約m(メモリ)と制約r(レジスタ)の違い
// inline-asm2.c
#include <stdio.h>
int main (void)
{
void *addr;
asm volatile ("movq %%rsp, %0": "=m"(addr));
printf ("rsp = %p\n", addr);
}
$ gcc -S inline-asm2.c
$ cat inline-asm2.s
(中略)
movq %rsp, -16(%rbp)
// inline-asm4.c
#include <stdio.h>
int main (void)
{
void *addr;
asm volatile ("movq %%rsp, %0": "=r"(addr));
printf ("rsp = %p\n", addr);
}
$ gcc -S inline-asm4.c
$ cat inline-asm4.s
(中略)
movq %rsp, %rax
movq %rax, -16(%rbp)
- 上のコードで制約
m(メモリ)を使うと,%0はメモリ参照-16(%rbp)に展開されました.-16(%rbp)は変数addrなので,変数addrへの代入はこれで終了です. - 一方, 制約
r(レジスタ)を使うと,%0はレジスタ%raxに展開されました. また,%raxの値をaddrに代入するために, グルーコードmovq %rsp, -16(%rbp)が追加されました.
読み書きするオペランドには制約+を使う
// inline-asm7.c
#include <stdio.h>
int main (void)
{
long in = 111, out = 222;
asm volatile ("movq %1, %0": "=rm"(out): "rm" (in)); // out = in;
printf ("in = %ld, out = %ld\n", in, out);
}
// inline-asm8.c
#include <stdio.h>
int main (void)
{
long in = 111, out = 222;
asm volatile ("addq %1, %0": "+rm"(out): "rm" (in)); // out += in;
printf ("in = %ld, out = %ld\n", in, out);
}
// inline-asm9.c
#include <stdio.h>
int main (void)
{
long in = 111, out = 222;
asm volatile ("addq %1, %0": "=rm"(out): "rm" (in), "0" (out)); // out += in;
printf ("in = %ld, out = %ld\n", in, out);
}

inline-asm7.cの❶はmovq命令なので,outは出力専用です. このため,入出力の制約は=を指定しています.- 一方,
inline-asm8.cの❷はaddq命令なので,outは入力と出力の両方になります. このため,入出力の制約は+を指定しています. addq命令に対してはマッチング制約 (ここでは"0")を使う方法もあります.inline-asm9.cの❸では,出力オペランド列ではoutに=を指定し, 入力オペランド列にもoutを指定し,その制約に"0"を指定しています. この"0"の指定で「このオペランドoutは出力オペランドの%0と同じオペランドだ」と伝えているのです.- マッチング制約で「同じオペランドだ」と指定された場合, コンパイラはそれらのオペランドに同じレジスタやメモリ参照を 割り当てようとします.
早期破壊オペランド制約 &
要約:
- 入力オペランドの参照よりも前に,出力オペランドへの代入がある場合は,
早期破壊オペランド制約
&を使う必要がある. - 早期破壊オペランド制約
&は「同じレジスタに割り当てるな」という指示- cf. マッチング制約は「同じレジスタに割り当てろ」という指示
// early-clobber.c
#include <stdio.h>
int main (void)
{
int a = 20, b;
asm volatile ("movl $10, %0; addl %1, %0"
: "=r"(b) : "r"(a)); // b = 10; b += a;
printf ("b = %d\n", b);
}
// early-clobber2.c
#include <stdio.h>
int main (void)
{
int a = 20, b;
asm volatile ("movl $10, %0; addl %1, %0"
: "=&r"(b) : "r"(a)); // b = 10; b += a;
printf ("b = %d\n", b);
}
$ gcc -g early-clobber.c
$ ./a.out
b = 20 結果が正しくない
$ gcc -g early-clobber2.c
$ ./a.out
b = 30 結果は正しい

- GCCは「命令テンプレートでは,入力オペランドを全て参照した後で, 出力オペランドへ代入している」という仮定をしています.
- その理由は多くの場合,その仮定は成り立つし,成り立てば,入力オペランドと出力オペランドに同じレジスタを割り当てられるからです.
- OKな例:
y = x + 3;はxを参照した後で,yに代入しています.ですので,xとyに同じレジスタ%eaxを割り当てて,addl $3, %eaxとしてもOKです. - NGな例:
b = 10; b += a;はbへの代入の後で,入力aを参照しています. GCCの仮定に反しているのに,aとbに同じレジスタ%eaxを割り当ててmovl $10, %eax; addl %eax, %eaxとしてしまうと,aの元の値が破壊されてしまいます.これが上のearly-clobber.cの状況です.
- OKな例:
early-clobber.c(上図の左)では,出力の制約を❶=としているだけなので,%0と%1が同じレジスタ%eaxになり❷, 意図通りの計算結果になりません(aの初期値20が失われています).- これを防ぐには 早期破壊オペランド制約
&(early-clobber operand constraint)を 制約に指定します❸.その結果,%0と%1には別のアドレスが割り当てられました.
破壊レジスタ列
-
出力オペランド列に指定したレジスタやメモリ以外への書き込みがある場合は, 破壊レジスタ列に指定する必要があります. コンパイラは指定されたレジスタやメモリへの読み書きが整合する範囲でのみ, 最適化のためのasm構文の移動を考えてくれます.
-
レジスタの破壊を指定して退避される例
int main ()
{
asm ("movl $999, %%ebx" :::"%ebx");
}
❶ pushq %rbx # %rbxの退避
movl $999, %ebx # %rbxの上位32ビットはクリアされる
❷ movq -8(%rbp), %rbx # %rbxの回復
破壊レジスタ列に%rbxを指定すると,コンパイラは前後に
%rbxの退避❶と回復❷のコードを付け足します.
%rbxはcallee-saveレジスタなので,main関数からリターンする前に,
%rbxの値を元の値に戻す必要があるからです.
- メモリの破壊を指定してコードが変化する例
// clobber-mem.c
#include <stdio.h>
int x = 111, y = 222;
int main ()
{
y = x;
// asm volatile ("":::"memory");
return x;
}
// clobber-mem2.c
#include <stdio.h>
int x = 111, y = 222;
int main ()
{
y = x;
asm volatile ("":::"memory"); // ❶
return x;
}
$ gcc -S clobber-mem.c
$ cat clobber-mem.s
(一部省略)
main:
movl x(%rip), %eax
movl %eax, y(%rip)
ret
$ gcc -S clobber-mem2.c
$ cat clobber-mem2.s
(一部省略)
main:
❷ pushq %rbp
❷ movq %rsp, %rbp
❸ movl x(%rip), %eax
movl %eax, y(%rip)
# asm volatile ("":::"memory");
❹ movl x(%rip), %eax
❷ popq %rbp
ret
- 上のコードで
"memory"を付けてメモリの破壊の存在をコンパイラに伝えた所, 以下の2つの変化がありました- スタックフレームが壊されないように,
main用のスタックフレームを作りました❷ - 変数
xの値が変化しているかも知れないので,❸で読んだ値は使わず, メモリが変化したと言われた後の ❹で改めて読んでいます.
- スタックフレームが壊されないように,
- なお,上の命令テンプレート❶は空ですが,コンパイラはメモリ破壊を信じてくれています
GCCは%以外の命令テンプレートの中身を見ない
// inline-hoge.c
#include <stdio.h>
long x = 111;
long y = 222;
int main ()
{
asm volatile ("hogehoge %1, %0": "+rm" (y): "rm" (x));
printf ("x = %ld, y = %ld\n", x, y);
}
movq x(%rip), %rax
movq y(%rip), %rdx
hogehoge %rax, %rdx
movq %rdx, y(%rip)
- GCCは(
%を除いて)命令テンプレートの中身は見ません. 入出力オペランド列や破壊レジスタ列などの情報だけを使って,%0などの部分を展開したり,グルーコードを出力します. - その証拠に,上の例では存在しない命令
hogehogeに対して,上記の展開とグルーコード付加をGCCは行いました.
局所変数をレジスタ割当にする
// local-reg.c
#include <stdio.h>
int main ()
{
register long foo asm ("%r15") = 999;
printf ("%ld\n", foo);
}
- 非常に頻繁に使う局所変数をレジスタ名を指定してレジスタ割当にしたい場合があります.その場合は上記の記法で指定できます.
- 注意:
registerは必要です.static,const,volatileなどはつけてはいけません.- この記法は指定したレジスタを予約するものではありません. コンパイラは他の部分で指定したレジスタを上書きするので,それを前提として使う必要があります.
アセンブラ方言の扱い
- GCCはアセンブリ記法の方言を出力できます.例えば,x86-64では
gcc -masm=attでAT&T記法を,gcc -masm=intelでIntel記法を出力できます. (デフォルトはAT&T記法です) gccへのオプション (-masm=att,-masm=intel)でどちらの記法を出力するか切り替えられますが,インラインアセンブリコードの中身は自動的には切り替わりません.- どちらのオプションが指定されても大丈夫にする方法がGCCにはいろいろ用意されています..例えば,以下の記法は
int main ()
{
asm volatile ("{movslq %%eax, %%rbx | movsxd rbx,eax}":);
}
AT&T形式の際は movslq %%eax, %%rbxを出力し,Intel形式の時は
movsxd rbx,eaxを出力します.
(このように命令テンプレート中で,{, |, }も, (そして =も)
特別な意味を持つので,これらの文字自身を出力したい場合は,
それぞれ,%{, %|, %}, %=と記述する必要があります).
つまり,インラインアセンブリコードを書く人が
AT&T形式とIntel形式の記述の両方を併記する必要があります.
さらに,
int main ()
{
int x = 111;
asm volatile ("inc %q0":"+r" (x));
}
と書くと,%q0の部分は,AT&T形式に対しては例えば%rax,Intel形式に対してはraxなどと展開します.詳細はGCCインラインアセンブラの
x86 Operand Modifiersを御覧ください.
GCCが生成したアセンブリコードを読む
この章では単純なCのプログラムをGCCがどのようなアセンブリコードに変換するかを見ていきます. これより以前の章で学んだ知識を使えば,C言語のコードが意外に簡単にアセンブリコードに変換できることが分かると思います. 実際にコンパイラの授業で構文解析の手法を学べば, (そして最適化器の実装を諦めれば)コンパイラは学部生でも十分簡単に作れます.
制御文
if文
// if.c
int x = 111;
int main ()
{
if (x > 100) {
x++;
}
}

- ifの条件式
x > 100は反転して「x <= 100なら,then部分をスキップして,thenの直後(ラベル.L2)にジャンプする」というコードを出力しています. (反転する必然性はありません.x > 0を評価してその結果が0に等しければ,.L2にジャンプするコードでも(実行速度を除けば)同じ動作になります) - then部分では「
xに1を加える」コードを出力しています.
なぜGCCはinc命令を使わないの?
incl x(%rip)なら1命令で済みますよね.
もし-Oや-O2などの最適化オプションを付ければ,
GCCはincを使うかも知れませんが,
そうしてしまうと,(最適化が賢すぎて)元のif文の構造がガラリと変わってしまう可能性があるため避けています.
この章では全て「最適化オプションを付けていないので,GCCは無駄なコードを出力することがある」と考えて下さい.
if-else文
// if-else.c
int x = 111;
int main ()
{
if (x > 100) {
x++;
} else {
x--;
}
}

- ifの条件式
x > 100は反転して「x <= 100なら,then部分をスキップして,thenの直後(ラベル.L2)にジャンプする」というコードを出力しています. - then部分では「
xに1を加える.次にelse部分をスキップするために.L3にジャンプする」コードを出力しています. - else部分では「
xから1減らす」コードを出力しています.
while文
// while.c
int x = 111;
int main ()
{
while (x > 100) {
x--;
}
}

- while条件判定はwhileボディのコードの後に置かれています(これは必然ではありません).
最初にwhileループに入る時,
.L2にジャンプします. - whileの条件式
x > 100が成り立つ間は,.L3に繰り返しジャンプします. - 「whileボディ」実行後に必ず「while条件判定」が必要になるので,これでうまくいきます.
for文
// for.c
int x = 111;
int main ()
{
for (int i = 0; i < 10; i++) {
x--;
}
}

- ほぼwhile文と同じです.違いは「for初期化」 (
int i = 0)があることと, 「forボディ」の直後に「for更新」(i++)があることだけです. - GCCが条件判定のコードを,
i < 10(cmpl $10, -4(%rbp); jl .L3)ではなく,i <= 9(compl $9, -4(%rbp); jl .l3)としています. どちらも同じなのですが,なぜこうしたのか,GCCの気持ちは分かりません.
switch文 (単純比較)
// switch.c
int x = 111;
int main ()
{
switch (x) {
case 1:
x++;
break;
case 111:
x--;
break;
default:
x = 0;
break;
}
}

- ジャンプテーブルを使わない,単純に比較するコード生成です.
例えば,
case 1:は,if (x == 1)と同様のコード生成になっています. - この方法ではcaseが\(n\)個あると,\(n\)回比較する必要があるので, \(O(n)\)の時間がかかってしまいます.
switch文 (ジャンプテーブル)
// switch2.c
int x = 111;
int main ()
{
switch (x) {
case 1: x++; break;
case 2: x--; break;
case 3: x = 3; break;
case 4: x = 4; break;
case 5: x = 5; break;
default: x = 0; break;
}
}
// switch3.c
int x = 111;
int main ()
{
void *jump_table [] = {&&L2, &&L8, &&L7, &&L6, &&L5, &&L3} ; // ❶
goto *jump_table [x]; // ❷
L8: // case 1:
x++; goto L9;
L7: // case 2:
x--; goto L9;
L6: // case 3:
x = 3; goto L9;
L5: // case 4:
x = 4; goto L9;
L3: // case 5:
x = 5; goto L9;
L2: // default:
x = 0; goto L9;
L9:
}

switch2.cをジャンプテーブルを使って書き換えたのがswitch3.cです. ❶と❷の部分はGCC拡張機能で「ラベルの値を配列変数に格納し❶」, 「gotoで格納したラベルにジャンプ❷」することができます.- 変数
xの値をジャンプテーブル(配列)のインデックスとして, ジャンプ先アドレスを取得し,間接ジャンプしています.movl %eax, %eaxはレジスタ%raxの上位32ビットをゼロクリアしています.notrackはIntel CET (control-flow enforcement technology)による拡張命令です.notrack付きの場合,間接ジャンプ先がendbr64ではなくても例外は発生しなくなります.
- ジャンプテーブルを使うと,\(O(1)\)でcase文を選択できます. ただし,ジャンプテーブルが使えるのはcaseが指定する範囲がある程度, 密な場合に限ります(巨大な配列を使えば,疎な場合でも扱えますが…).
定数
整数定数
// const-int.c
int main ()
{
return 999;
}
main:
endbr64
pushq %rbp
movq %rsp, %rbp
movl ❶ $999, %eax
popq %rbp
ret
- 整数定数
999は❶即値 ($999)としてコード生成されています
文字定数
// const-char.c
int main ()
{
return 'A';
}
main:
endbr64
pushq %rbp
movq %rsp, %rbp
movl ❶ $65, %eax
popq %rbp
ret
- 文字定数は❶即値 (
$65, 65は文字AのASCIIコード)としてコード生成されています
文字列定数
// const-string.c
#include <stdio.h>
int main ()
{
puts ("hello\n");
}
❶ .section .rodata
❷ .LC0:
❸ .string "hello\n"
.text
.globl main
.type main, @function
main:
endbr64
pushq %rbp
movq %rsp, %rbp
leaq ❹ .LC0(%rip), %rax
movq %rax, %rdi
call puts@PLT
movl $0, %eax
popq %rbp
ret
- 文字列定数
"hello\n"の実体は❶.rodataセクションに置かれます. ❸.string命令で"hello\n"のバイナリ値を配置し, その先頭アドレスを❷ラベル.LC0:と定義しています. - 式中の
"hello\n"の値は「その文字列の先頭アドレス」ですので, ❹.LC0(%rip)と参照しています(ここでは文字列の先頭アドレスが%raxに格納されます)
配列

以下で使うint a[3]の配列のメモリレイアウトは上の図のようになってます.
このため,a[2]を参照する時はアドレスa+8のメモリを読み,
a[i]を参照する時はアドレスa+i*4のメモリを読む必要があります.
// array3.c
int a [] = {111, 222, 333};
int main ()
{
return a [2];
}
.globl a
.data
.align 8
.type a, @object
.size a, 12
❶ a:
❷ .long 111
❷ .long 222
❷ .long 333
.text
.globl main
.type main, @function
main:
endbr64
pushq %rbp
movq %rsp, %rbp
movl ❸ 8+a(%rip), %eax
popq %rbp
ret
- 配列はメモリ上で連続する領域に配置されます.
この場合は❷
.long命令で4バイトずつ,111,222,333の2進数を隙間なく配置しています.個人的には.long 111, 222, 333と1行で書いてくれる方が嬉しいのですが… (なお,配列とは異なり,構造体の場合はメンバー間や最後にパディング(隙間)が入ることがあります) - 配列の先頭アドレスを❶ラベル
a:と定義しています. a[2]の参照は❸8+a(%rip)という%rip相対のメモリ参照になっています. 指定したインデックスが定数(2)だったため,変位が8+aになっています. (a[i]などとインデックスが変数の場合はアセンブラの足し算は使えません).
a[i]の場合のコンパイル結果は例えば以下のとおりです.
a[i]の値を読むために,a+i*4の計算をする必要があり,
少し複雑になっています.
// array4.c
int a [] = {111, 222, 333};
int i = 1;
int main ()
{
return a [i];
}
.globl a
.data
.align 8
.type a, @object
.size a, 12
a:
.long 111
.long 222
.long 333
.globl i
.align 4
.type i, @object
.size i, 4
i:
.long 1
.text
.globl main
.type main, @function
main:
endbr64
pushq %rbp
movq %rsp, %rbp
movl i(%rip), %eax # iの値を %eax に代入
cltq # %eax を %rax に符号拡張
leaq 0(,%rax,4), %rdx # i*4 を %rdx に代入
leaq a(%rip), %rax # aの絶対アドレスを %rax に代入
movl (%rdx,%rax), %eax # アドレス a+i*4 の値(4バイト,これがa[i])を %eax に代入
popq %rbp
ret
.size main, .-main
構造体
// struct5.c
struct foo {
char x1;
int x2;
};
struct foo f = {10, 20};
int main ()
{
return f.x2;
}
.globl f
.data
.align 8
.type f, @object
.size f, 8
❶ f:
❷ .byte 10 # x1
❸ .zero 3 # 3バイトのパディング
❹ .long 20 # x2
.text
.globl main
.type main, @function
main:
endbr64
pushq %rbp
movq %rsp, %rbp
movl ❺ 4+f(%rip), %eax
popq %rbp
ret
- 構造体
fooがメモリ上に配置される際,アラインメント制約を満たすために パディングが入ることがあります. - ここでは,メンバー❷
x1と❹x2の間に❸3バイトのパディングが入っています. - 構造体メンバーの参照
foo.x2は ❺4+f(%rip)という%rip相対のメモリ参照になっています.
共用体
// union2.c
#include <stdio.h>
union foo {
char x1 [5];
int x2;
};
union foo f = {.x1[0] = 'a'};
int main ()
{
f.x2 = 999;
return f.x2;
}
.globl f
.data
.align 8
.type f, @object
❶ .size f, 8
❷ f:
❸ .byte 97
❹ .zero 4
❺ .zero 3
.text
.globl main
.type main, @function
main:
endbr64
pushq %rbp
movq %rsp, %rbp
movl $999, ❻ f(%rip)
movl ❼ f(%rip), %eax
popq %rbp
ret
- 共用体は以下を除き,構造体と一緒です
- 同時に1つのメンバーにしか代入できない
- 全てのメンバーはオフセット0でアクセスする
- 共用体のサイズは最大サイズを持つメンバ+パディングのサイズになる
- 上の例では最大サイズのメンバ
char x1 [5]に3バイトのパディングがついて, 共用体fのサイズは8バイトになってます
- 上の例では最大サイズのメンバ
- 上の例では指示付き初期化子(designated initializer)の記法
(
union foo f = {.x1[0] = 'a'};)を使って,メンバx1を初期化しています. ❸'a'の値が.byteで配置され,残りの7バイトは❹❺0で初期化されています. - 共用体
fへの代入や参照はメモリ参照❻❼f(%rip)でアクセスされています.
変数
初期化済みの静的変数
// var-init-static.c
int x = 999;
int main ()
{
return x;
}
.globl x
❶ .data
.align 4
.type x, @object
.size x, 4
❷ x:
❸ .long 999
.text
.globl main
.type main, @function
main:
endbr64
pushq %rbp
movq %rsp, %rbp
movl ❹ x(%rip), %eax
popq %rbp
ret
- 初期化済みの静的変数の実体は❶
.dataセクションに配置されます. 初期値 (999)を(この場合はint型なので).long命令で999のバイナリ値を配置し,その先頭アドレスをラベルx:と定義しています. - 変数
xの参照は❹x(%rip)という%rip相対のメモリ参照です.
未初期化の静的変数
// var-uninit-static.c
int x;
int main ()
{
x = 999;
return x;
}
.globl x
❶ .bss
.align 4
.type x, @object
.size x, 4
❷ x:
❸ .zero 4
.text
.globl main
.type main, @function
main:
endbr64
pushq %rbp
movq %rsp, %rbp
movl $999, ❹ x(%rip)
movl ❺ x(%rip), %eax
popq %rbp
ret
- 未初期化の静的変数の実体は❶
.bssセクションに配置されます..bssセクション中の変数は❸ゼロで初期化されます. 初期化した4バイトの先頭アドレスをラベル❷x:と定義しています.- ただし
.bssセクションが実際にゼロで初期化されるのは実行直前です
- ただし
- 変数
xの参照は,メモリ参照❹❺x(%rip)でアクセスされています.
自動変数 (static無しの局所変数)
// var-auto.c
int main ()
{
int x;
x = 999;
return x;
}
.text
.globl main
.type main, @function
main:
endbr64
pushq %rbp
movq %rsp, %rbp
movl $999, ❶ -4(%rbp)
movl ❷ -4(%rbp), %eax
popq %rbp
ret

- 自動変数は実行時にスタック上にその実体が配置されます.
上の例では変数
xは❶❷-4(%rbp)から始まる4バイトに割り当てられ, アクセスされています. (この変数xはレッドゾーンに配置されています)
実引数
// arg.c
void foo (long a1, long a2, long a3, long a4, long a5, long a6, long a7);
int main ()
{
foo (10, 20, 30, 40, 50, 60, 70);
}
.text
.globl main
.type main, @function
main:
endbr64
pushq %rbp
movq %rsp, %rbp
❹ subq $8, %rsp # パディング
❷ pushq $70 # 第7引数
❶ movl $60, %r9d # 第6引数
❶ movl $50, %r8d # 第5引数
❶ movl $40, %ecx # 第4引数
❶ movl $30, %edx # 第3引数
❶ movl $20, %esi # 第2引数
❶ movl $10, %edi # 第1引数
❸ call foo@PLT
❺ addq $16, %rsp # 第7引数とパディングを捨てる
movl $0, %eax
leave
ret

-
第6引数までは❶レジスタ渡しになります. 第7引数以降は❷スタックに積んでから関数を呼び出します.
❶で
movqではなくmovl命令を使っているのは, こちらで説明した通り, 例えばmovl $10, %ediを実行すると%rdiレジスタの上位32ビットがゼロになるからです. -
System V ABI (AMD64) により ❸
call命令実行時には%rspの値は16の倍数である必要があります. そのため,❹で8バイトのパディングをスタックに置いています. -
関数からリターン後は❷でスタックに積んだ引数と❹パディングを❸スタック上から取り除きます.
仮引数
// parameter.c
#include <stdio.h>
void
foo (long a1, long a2, long a3, long a4, long a5, long a6, long a7)
{
printf ("%ld\n", a1 + a7);
}
.text
.section .rodata
.LC0:
.string "%ld\n"
.text
.globl foo
.type foo, @function
foo:
endbr64
pushq %rbp
movq %rsp, %rbp
subq $48, %rsp
movq ❶ %rdi, -8(%rbp) # 第1引数
movq ❶ %rsi, -16(%rbp) # 第2引数
movq ❶ %rdx, -24(%rbp) # 第3引数
movq ❶ %rcx, -32(%rbp) # 第4引数
movq ❶ %r8, -40(%rbp) # 第5引数
movq ❶ %r9, -48(%rbp) # 第6引数
movq -8(%rbp), %rdx
movq ❷ 16(%rbp), %rax # 第7引数
addq %rdx, %rax
movq %rax, %rsi
leaq .LC0(%rip), %rax
movq %rax, %rdi
movl $0, %eax
call printf@PLT
nop
leave
ret

- GCCはレジスタで受け取った第1〜第6引数をスタック上に❶置いています.
一方,第7引数はスタック渡しで,その場所は❻
16(%rbp)でした.
式 (expression)
単項演算子 (unary operator)
// unary.c
int x = 111;
int main ()
{
return -x;
}
.text
.globl x
.data
.align 4
.type x, @object
.size x, 4
x:
.long 111
.text
.globl main
.type main, @function
main:
endbr64
pushq %rbp
movq %rsp, %rbp
movl x(%rip), %eax
❶ negl %eax
popq %rbp
ret
- 単項演算は対応する命令,ここでは❶
neglを使うだけです.
二項演算子(単純な加算)
// binop-add.c
int x = 111;
int main ()
{
return x + 89;
}
.globl x
.data
.align 4
.type x, @object
.size x, 4
x:
.long 111
.text
.globl main
.type main, @function
main:
endbr64
pushq %rbp
movq %rsp, %rbp
movl x(%rip), %eax
❶ addl $89, %eax
popq %rbp
ret
- 基本的に二項演算子も対応する命令 (ここでは❷
addl)を使うだけです.
二項演算子(割り算)
// binop-div.c
int x = 111, y = 9;
int main ()
{
return x / y;
}
.globl x
.data
.align 4
.type x, @object
.size x, 4
x:
.long 111
.globl y
.align 4
.type y, @object
.size y, 4
y:
.long 9
.text
.globl main
.type main, @function
main:
endbr64
pushq %rbp
movq %rsp, %rbp
movl x(%rip), %eax
movl y(%rip), %ecx
❷ cltd
❶ idivl %ecx
popq %rbp
ret
- 割り算はちょっと注意が必要です.
- 例えば,32ビット符号ありの割り算を❶
idivl命令で行う場合,%edx:%eaxを第1オペランドで割った商が%eaxに入ります. - このため,
idivlを使う前に❷cltd命令等を使って,%eaxを符号拡張した値を%edxに設定しておく必要があります (%edxの値の設定を忘れるて%idivlを実行すると,割り算の結果がおかしくなります)
二項演算(ポインタ演算)
- 復習: C言語のポインタ演算 (オペランドがポインタの場合の演算)は普通の加減算と意味が異なります.ポインタが指す先のサイズを使って計算する必要があります.
| 演算 | 意味 (int i, *p, *qの場合) |
|---|---|
p + i | p + (i * sizeof (*p)) |
i + q | p + (i * sizeof (*p)) |
p + q | コンパイルエラー |
p - i | p - (i * sizeof (*p)) |
i - q | コンパイルエラー |
p - q | (p - q) / sizeof (*p) |
// pointer-arith.c
#include <stdio.h>
int a [] = {0, 10, 20, 30};
int main ()
{
printf ("%p, %p\n", a, &a[0]); // 同じ
printf ("%p, %p, %p\n", &a[2], a + 2, 2 + a); // 同じ
printf ("%p, %p\n", a, &a[2] - 2); // 同じ
printf ("%ld\n", &a[2] - &a[0]);
// printf ("%p\n", &a[2] + &a[0]); // コンパイルエラー
// printf ("%p\n", 2 - &a[2]); // コンパイルエラー
}
$ gcc -g -no-pie pointer-arith.c
$ ./a.out
0x404030, 0x404030
0x404038, 0x404038, 0x404038
0x404030, 0x404030
2

- 復習: 式中で配列名(
a)はその配列の先頭要素のアドレス(&a[0])を意味します. - 復習: 式中で配列要素へのアクセス
a[i]は,*(a+i)や*(i+a)と書いても同じ意味です. - 例えば,上の例で
a+2は,配列の要素がint型で,sizeof(int)が4なので, \(0x404030 + 2\times 4 = 0x404038\) という計算になります. このため,a+2は&a[2]と同じ値になります.
// pointer-arith2.c
int a [] = {0, 10, 20, 30};
int* foo ()
{
return a + 2; // ❶
}
.globl a
.data
.align 16
.type a, @object
.size a, 16
a:
.long 0
.long 10
.long 20
.long 30
.text
.globl foo
.type foo, @function
foo:
endbr64
pushq %rbp
movq %rsp, %rbp
leaq ❷ 8+a(%rip), %rax
popq %rbp
ret
- 上の例でCコード中の❶
a+2は,アセンブリコード中では❷8+aになっています. 配列要素のサイズ4をかけ算して,\(a + 2\times 4\)という計算をするからです.
アドレス演算子&と逆参照演算子*
// op-addr.c
int x = 111;
int *p;
int main ()
{
p = &x;
return *p;
}
.globl x
.data
.align 4
.type x, @object
.size x, 4
x:
.long 111
.globl p
.bss
.align 8
.type p, @object
.size p, 8
p:
.zero 8
.text
.globl main
.type main, @function
main:
endbr64
pushq %rbp
movq %rsp, %rbp
❶ leaq x(%rip), %rax
movq %rax, p(%rip)
❷ movq p(%rip), %rax
❸ movl (%rax), %eax
popq %rbp
ret
- アドレス演算子
&xには変数xのアドレスを計算すれば良いので,leaq命令を使います. 具体的には❶leaq x(%rip), %raxで,xの絶対アドレスを%raxに格納しています. - 逆参照演算子
*pにはメモリ参照を使います. まず❷movq p(%rip), %raxで変数pの中身を%raxに格納し, ❸movl (%rax), %eaxとすれば,メモリ参照(%rax)でpが指す先の値を得られます.
比較演算子
// pred.c
int x = 111;
int main ()
{
return x > 100;
}
.globl x
.data
.align 4
.type x, @object
.size x, 4
x:
.long 111
.text
.globl main
.type main, @function
main:
endbr64
pushq %rbp
movq %rsp, %rbp
movl x(%rip), %eax
❶ cmpl $100, %eax
❷ setg %al
❸ movzbl %al, %eax
popq %rbp
ret
>などの比較演算子にはset␣命令を使います.- 例えば,
x > 100の場合,- ❶
cmpl命令で比較を行い, - ❷
setgを使って「より大きい」という条件が成り立っているかどうかを%alに格納し - ❸
movzblを使って,必要なサイズ(ここでは4バイト)にゼロ拡張しています
- ❶
論理ANDと論理OR,「左から右への評価」
// land.c
int x = 111;
int main ()
{
return 50 < x && x < 200;
}
.globl x
.data
.align 4
.type x, @object
.size x, 4
x:
.long 111
.text
.globl main
.type main, @function
main:
endbr64
pushq %rbp
movq %rsp, %rbp
movl x(%rip), %eax
cmpl $50, %eax
❶ jle .L2 # if x <= 50 goto .L2
movl x(%rip), %eax
cmpl $199, %eax
❷ jg .L2 # if x > 199 goto .L2
movl $1, %eax # 結果に1をセット
jmp .L4
.L2:
movl $0, %eax # 結果に0をセット
.L4:
popq %rbp
ret
-
多くの二項演算子では「両方のオペランドを計算してから,その二項演算子 (例えば加算)を行う」というコードを生成すればOKです.
-
しかし,論理AND (
&&) や論理OR (||)ではそのやり方ではNGです. 論理ANDと論理ORは左から右への評価 (left-to-right evaluation)を 行う必要があるからです.-
論理ANDでは,まず左オペランドを計算し,その結果が真の時だけ, 右オペランドを計算します.(左オペランドが偽ならば,右オペランドを計算せず,全体の結果を偽とする)
-
論理OR では,まず左オペランドを計算し,その結果が偽の時だけ, 右オペランドを計算します.(左オペランドが真ならば,右オペランドを計算せず,全体の結果を真とする)
-
要するに左オペランドだけで結果が決まる時は,右オペランドを計算してはいけないのです. このおかげで,以下のようなコードが記述可能になります. (右オペランド
*p > 100が評価されるのはpがNULLではない場合のみになります)int *p; if (p != NULL && *p > 100) { ...
-
-
このため,上のコード例でも❶左オペランドが真の場合だけ, ❷右オペランドが計算されています.
代入
// assign.c
int x = 111;
int main ()
{
return x = 100;
}
.globl x
.data
.align 4
.type x, @object
.size x, 4
x:
.long 111
.text
.globl main
.type main, @function
main:
endbr64
pushq %rbp
movq %rsp, %rbp
❶ movl $100, x(%rip)
❷ movl x(%rip), %eax
popq %rbp
ret
- 代入式は単純に❶
mov命令を使えばOKです. - 代入式には(代入するという副作用以外に)「代入した値そのものを
その代入式の評価結果とする」という役割もあります.
そのため❷で,
returnで返す値を%eaxに格納しています.
文 (statement)
式文
// exp-stmt.c
int x = 111;
int main ()
{
x = 222;
333;
}
.globl x
.data
.align 4
.type x, @object
.size x, 4
x:
.long 111
.text
.globl main
.type main, @function
main:
endbr64
pushq %rbp
movq %rsp, %rbp
❶ movl $222, x(%rip)
movl $0, %eax
popq %rbp
ret
- 復習: 式にセミコロン
;を付けたものが式文です. x = 222;という式文(代入文)は,代入式の ❶mov命令をそのまま出力すればOKです.- 式文中の式の計算にスタックを使った場合は,スタック上の値を捨てる必要があることがあります
333;は文法的に正しい式文なのですが,意味がないのでGCCはこの式文を無視しました
ブロック文
// block-stmt.c
int x = 111;
int main ()
{
{
x = 222;
x = 333;
x = 444;
}
}
.globl x
.data
.align 4
.type x, @object
.size x, 4
x:
.long 111
.text
.globl main
.type main, @function
main:
endbr64
pushq %rbp
movq %rsp, %rbp
❶ movl $222, x(%rip) # 文1
❷ movl $333, x(%rip) # 文2
❸ movl $444, x(%rip) # 文3
movl $0, %eax
popq %rbp
ret
- 復習: ブロック文 (あるいは複合文 (compound statement))は, 複数の文が並んだ文です.
- ブロック文のコード出力は簡単で,文の並びの順番に,それぞれの アセンブリコード❶❷❸を出力するだけです.
goto文とラベル文
// goto.c
int x = 111;
int main ()
{
foo:
x = 222;
goto foo;
}
.globl x
.data
.align 4
.type x, @object
.size x, 4
x:
.long 111
.text
.globl main
.type main, @function
main:
endbr64
pushq %rbp
movq %rsp, %rbp
.L2:
movl $222, x(%rip)
jmp .L2
- C言語のラベル
fooはアセンブリコードでは.L2になっていますが, (名前の重複に気をつければ)ラベルとして出力すればOKです goto文もそのまま無条件ジャンプjmpにすればOKです
return文 (intを返す)
// return.c
int x = 111;
int main ()
{
return x;
}
.globl x
.data
.align 4
.type x, @object
.size x, 4
x:
.long 111
.text
.globl main
.type main, @function
main:
endbr64
pushq %rbp
movq %rsp, %rbp
❶ movl x(%rip), %eax
❷ popq %rbp
❸ ret
intなどの整数型を返すreturn文は簡単です. ❶返す値を%raxレジスタに格納し,❷スタックフレームの後始末をしてから, ❸ret命令で,リターンアドレスに制御を移せばOKです.
return文 (構造体を返す)
// return2.c
struct foo {
char x1;
long x2;
};
struct foo f = {'A', 0x1122334455667788};
struct foo func ()
{
return f;
}
.globl f
.data
.align 16
.type f, @object
.size f, 16
f:
.byte 65
.zero 7
.quad 1234605616436508552
.text
.p2align 4
.globl func
.type func, @function
func:
endbr64
❶ movq 8+f(%rip), %rdx
❷ movq f(%rip), %rax
ret
-
復習: C言語では,配列や関数を,関数の引数に渡したり,関数から返すことはできません (配列へのポインタや,関数へのポインタなら可能ですが). 一方,構造体や共用体は,関数の引数に渡したり,関数から返すことができます.
-
8バイトより大きい構造体や共用体を関数引数や返り値にする場合, 通常のレジスタ以外のレジスタやスタックを使ってやりとりをします. 具体的な方法は System V ABI (AMD64) が定めています.
-
上の例では
%raxと%rdxを使って,構造体fを関数からリターンしています. (コードが簡単になるように,ここではgcc -O2 -Sの出力を載せています)
関数
関数定義
// add5.c
int add5 (int n)
{
return n + 5;
}
.text
.globl add5
.type add5, @function
❷ add5: # 関数名のラベル定義
endbr64
pushq %rbp # スタックフレーム作成
movq %rsp, %rbp # スタックフレーム作成
❶ movl %edi, -4(%rbp) # 関数本体
❶ movl -4(%rbp), %eax # 関数本体
❶ addl $5, %eax # 関数本体
popq %rbp # スタックフレーム破棄
ret # リターン
.size add5, .-add5
- 関数を定義するには関数本体のアセンブリコード❶の前に関数プロローグ,
後に関数エピローグのコードを出力します.
また,関数の先頭で❷関数名のラベル(
add5;)を定義します. - 関数プロローグはスタックフレームの作成や,callee-saveレジスタの退避などを行います.
- 関数エピローグはcallee-saveレジスタの回復や,スタックフレームの破棄などを行い,
retでリターンします.
関数コール
// main.c
#include <stdio.h>
int add5 (int n);
int main ()
{
printf ("%d\n", add5 (10));
}
.section .rodata
.LC0:
.string "%d\n"
.text
.globl main
.type main, @function
main:
endbr64
pushq %rbp
movq %rsp, %rbp
❶ movl $10, %edi
❷ call add5@PLT
❸ movl %eax, %esi
leaq .LC0(%rip), %rax
movq %rax, %rdi
movl $0, %eax
call printf@PLT
movl $0, %eax
popq %rbp
ret
- 関数コールをするには,
call命令の前に引数をレジスタやスタック上に格納してから,call命令を実行します.その後,%raxに入っている返り値を引き取ります. - 上の例では,
- ❶で
10を第1引数として%ediレジスタにセットしてから, - ❷で
callを実行して,制御をadd5関数に移します - ❸で
add5の返り値 (%eax)を引き取っています
- ❶で
- デフォルトの動的リンクを前提としたコンパイルなので,
関数名が
add5ではなく❷add5@PLTとなっています (PLTについてはこちらを参照)
関数コール(関数ポインタ)
// main2.c
#include <stdio.h>
int add5 (int n);
int main ()
{
int (*fp) (int n) = add5;
printf ("%d\n", fp (10));
}
.section .rodata
.LC0:
.string "%d\n"
.text
.globl main
.type main, @function
main:
endbr64
pushq %rbp
movq %rsp, %rbp
subq $16, %rsp
❶ movq add5@GOTPCREL(%rip), %rax # GOT領域のadd5のエントリ(中身はadd5の絶対アドレス)
movq %rax, -8(%rbp)
movq -8(%rbp), %rax
❷ movl $10, %edi
❸ call *%rax
movl %eax, %esi
leaq .LC0(%rip), %rax
movq %rax, %rdi
movl $0, %eax
call printf@PLT
movl $0, %eax
leave
ret
- 上のコード例では
add5を変数fpに代入して,fp中の関数ポインタを使って,add5を呼び出しています. - これをアセンブリコードにすると❶
movq add5@GOTPCREL(%rip), %raxになります.add5@GOTPCRELはGOT領域のadd5のエントリなので, メモリ参照add5@GOTPCREL(%rip)で,add5の絶対アドレスを取得できます (GOT領域についてはこちらを参照) - ❷で第1引数(
10)を%ediに渡して - ❸
call *%raxで%rax中の関数ポインタを間接コールしています
ライブラリ関数コール
// main.c
#include <stdio.h>
int add5 (int n);
int main ()
{
printf ("%d\n", add5 (10));
}
.section .rodata
.LC0:
.string "%d\n"
.text
.globl main
.type main, @function
main:
endbr64
pushq %rbp
movq %rsp, %rbp
movl $10, %edi
call add5@PLT
❷ movl %eax, %esi
❶ leaq .LC0(%rip), %rax
❶ movq %rax, %rdi
❸ movl $0, %eax
❹ call printf@PLT
movl $0, %eax
popq %rbp
ret
- ここではライブラリ関数代表として,
printfを呼び出すコードを見てみます.- ❶で
printfの第1引数である文字列"%d\n"の先頭アドレス (.LC0(%rip))を第1引数のレジスタ%rdiに格納します - ❷は
add5が返した値を,第2引数のレジスタ%esiに格納します - ❸で
%eaxに0を格納しています.%alはprintfなどの可変長引数を持つ関数の隠し引数です%alにはベクタレジスタを使って渡す浮動小数点数の引数の数をセットします- これはSystem V ABI (AMD64)が定めています
- ❹で
printfをコールしています
- ❶で
システムコール
// syscall-exit.c
#include <unistd.h>
int main ()
{
_exit (0);
}
.text
.globl main
.type main, @function
main:
endbr64
pushq %rbp
movq %rsp, %rbp
movl $0, %edi
❶ call _exit@PLT
exitはライブラリ関数なので,ここではシステムコールである_exitを呼び出しています.- が,
_exitもただのラッパ関数で,_exitの中で実際のシステムコールを呼び出します. このため,❶を見れば分かる通り,_exitの呼び出しは ライブラリ関数の呼び出し方と同じになります.
$ objdump -d /lib/x86_64-linux-gnu/libc.so.6 | less
(中略)
00000000000eac70 <_exit>:
eac70: f3 0f 1e fa endbr64
eac74: 4c 8b 05 95 e1 12 00 mov 0x12e195(%rip),%r8 # 218e10 <_DYNAMIC+0x250>
eac7b: be e7 00 00 00 mov $0xe7,%esi
eac80: ba 3c 00 00 00 mov $0x3c,%edx
eac85: eb 16 jmp eac9d <_exit+0x2d>
eac87: 66 0f 1f 84 00 00 00 nopw 0x0(%rax,%rax,1)
eac8e: 00 00
eac90: 89 d0 mov %edx,%eax
eac92: 0f 05 ❶ syscall
eac94: 48 3d 00 f0 ff ff cmp $0xfffffffffffff000,%rax
eac9a: 77 1c ja eacb8 <_exit+0x48>
eac9c: f4 hlt
eac9d: 89 f0 mov %esi,%eax
eac9f: 0f 05 ❶ syscall
eaca1: 48 3d 00 f0 ff ff cmp $0xfffffffffffff000,%rax
eaca7: 76 e7 jbe eac90 <_exit+0x20>
eaca9: f7 d8 neg %eax
eacab: 64 41 89 00 mov %eax,%fs:(%r8)
eacaf: eb df jmp eac90 <_exit+0x20>
eacb1: 0f 1f 80 00 00 00 00 nopl 0x0(%rax)
eacb8: f7 d8 neg %eax
eacba: 64 41 89 00 mov %eax,%fs:(%r8)
eacbe: eb dc jmp eac9c <_exit+0x2c>
_exit関数の中身を逆アセンブルしてみると, ❶syscall命令を使ってシステムコールを呼び出している部分を見つけられます. (お作法を正しく守れば,_exitを使わず,直接,syscallでシステムコールを呼び出すこともできます)
memcpyと最適化
-
ライブラリ関数
memcpyの呼び出しは,最適化の有無により例えば次の3パターンになります:call memcpy(通常の関数コール)movdqa src(%rip), %xmm0; movaps %xmm0, dst(%rip)(SSE/AVX命令)rep movsq(ストリング命令)
-
最適化無しの場合
// memcpy.c
#include <stdio.h>
#include <string.h>
char src [4096], dst [4096];
int main ()
{
memcpy (dst, src, 64);
}
$ gcc -S memcpy.c
$ cat memcpy.s
main:
pushq %rbp
movq %rsp, %rbp
movl $64, %edx
leaq src(%rip), %rax
movq %rax, %rsi
leaq dst(%rip), %rax
movq %rax, %rdi
call memcpy@PLT # 普通の call命令でライブラリ関数memcpyを呼ぶ
-
最適化した場合
$ gcc -S -O2 memcpy.c $ cat memcpy.s main: movdqa src(%rip), %xmm0 # 16バイト長の%xmm0レジスタに16バイトコピー movdqa 16+src(%rip), %xmm1 xorl %eax, %eax movdqa 32+src(%rip), %xmm2 movdqa 48+src(%rip), %xmm3 movaps %xmm0, dst(%rip) # %xmm0レジスタからメモリに16バイトコピー movaps %xmm1, 16+dst(%rip) movaps %xmm2, 32+dst(%rip) movaps %xmm3, 48+dst(%rip)memcpy.cを-O2でコンパイルすると,movdqaとmovaps命令を使うコードを出力しました.アラインメントなどの条件が合うと,こうなります.%xmm0〜%xmm3はSSE拡張で導入された16バイト長のレジスタです.
-
サイズを増やして最適化した場合
// memcpy2.c
#include <stdio.h>
#include <string.h>
char src [4096], dst [4096];
int main ()
{
memcpy (dst, src, 1024);
}
$ gcc -S -O2 memcpy2.c
$ cat memcpy.s
main:
leaq dst(%rip), %rax
leaq src(%rip), %rsi
movl $128, %ecx
movq %rax, %rdi
xorl %eax, %eax
rep movsq
- サイズを増やすと,
rep movsqというストリング命令を出力しました. rep movsqは,%ecx回の繰り返しを行います. 各繰り返しでは,メモリ(%rsi)の値を(%rdi)に8バイトコピーし,%rsiと%rdiの値を8増やします. (DFフラグが1の場合は8減らしますが,ABIが「関数の出入り口で(DF=1にしていたら)DF=0に戻せ」と定めているので,ここではDF=0です)
%rsiと%rdiの名前の由来
%rsiは source index,%rdiは destination index が名前の由来です.
デバッガgdbの使い方
デバッガの概要
なぜデバッガ?

gdbなどのデバッガの使用をお薦めする理由は「プログラムのデバッグ」をとても楽にしてくれるからです!!- デバッグが難しいのは実行中のプログラムの中身(実行状態)が外からでは見えにくいからです.
printfを埋め込むことでも変数の値や実行パスを調べられますが, デバッガを使うともっと効率的に調べることができます. - デバッガは「簡単に習得できて,効果も高いお得な開発ツール」です. 慣れることが大事です.
- デバッガはつまみ食いOKです. 最初は「自分が使いたい機能,使える機能」だけを使えばいいのです. デバッガを使うために「デバッガの全て」を学ぶ必要はありません.
デバッガとは

デバッガは主に以下の機能を組み合わせて,プログラムの実行状態を調べることで, バグの原因を探します.
- ① プログラム実行の一時停止: 「実行を止めたい場所(ブレークポイント)」や止めたい条件を設定できます. ブレークポイントには関数名や行番号やアドレスなどを指定できます.
- ② ステップ実行: ①でプログラムの実行を一時停止した後, ステップ実行の機能を使って,ちょっとずつ実行を進めます.
- ③ 実行状態の表示: 変数の値,現在の行番号,スタックトレース(バックトレース)などを表示できます.
- ④ 実行状態の変更: 変数に別の値を代入したり,関数を呼び出したりして, 「ここでこう実行したら」を試せます.
gdbとは
- Linux上で使える代表的で高性能なデバッガです.
- C/C++/アセンブリ言語/Objective-C/Rustなど,多くの言語をサポートしています.
- Linux/x86-64を含む,多くのOSやプロセッサに対応しています.
- オープンソースで無料で使えます (GNU GPLライセンス).
- 一次情報: GDB: The GNU Project Debugger
gdbの実行例 (C言語編)
起動 run と終了 quit
// hello.c
#include <stdio.h>
int main ()
{
printf ("hello\n");
}
$ gcc ❶ -g hello.c
$ ./a.out
hello
$ ❷ gdb ./a.out
❸(gdb) ❹ run
hello
(gdb) ❺ quit
A debugging session is active.
Inferior 1 [process 20186] will be killed.
Quit anyway? (y or n) ❻ y
$
gdbでデバッグする前に,gccのコンパイルに❶-gオプションを付けます.-gはa.outにデバッグ情報を付加します. デバッグ情報がなくてもデバッグは可能ですが, ファイル名や行番号などの情報が表示されなくなり不便です.
gcc -g -Og オプションがベスト
gdbのマニュアルに以下の記述があります.
-O2などの最適化オプションを付けてコンパイルしたプログラムでもgdbで デバッグできるが,行番号がずれたりする.なので可能なら 最適化オプションを付けない方が良い.gdbでデバッグするベストな最適化オプションは-Ogであり,-Ogは-O0よりも良い.
ですので,デバッグ時には gcc -g -Ogオプションがベストなようです.
Inferior はデバッグ対象のプログラムのこと
上の実行例中のInferior 1 [process 20186] will be killed.は
「gdbの終了に伴って,デバッグ対象のプログラムも実行終了させます」という
ことを意味しています.
inferiorは「下位の」「劣った」という意味ですね
(劣等感は英語で inferiority complex).
gdbのマニュアルでもデバッグ対象のプログラムを一貫してinferiorと呼んでいます.
なお他の文献ではデバッグ対象のプログラムのことをデバッギ (debuggee)と呼ぶことがあります.
- ❷
gdb ./a.outと,引数にデバッグ対象のバイナリ(ここでは./a.out)を指定してgdbを起動します.
gdb起動メッセージの抑制
デフォルトでgdbを起動すると以下のような長い起動メッセージが出ます.
$ gdb ./a.out
GNU gdb (Ubuntu 12.1-0ubuntu1~22.04) 12.1
Copyright (C) 2022 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Type "show copying" and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<https://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from ./a.out...
(gdb)
これを抑制するには,gdb -qオプションを付けるか,
~/.gdbearlyinitファイルに以下を指定します.
set startup-quietly on
- ❸
(gdb)はgdbのプロンプトです.gdbのコマンドが入力可能なことを示します. - ❹
runはgdb上でプログラムの実行を開始します. ここではブレークポイントを指定していないため,そのままhelloを出力して プログラムは終了しました. - ❺
quitはgdbを終了させます. (ここではすでにデバッグ対象のプログラムの実行は終了していますが) デバッグ対象のプログラムが終了しておらず, 「本当に終了して良いか?」と聞かれたら,❻yと答えて終了させます.
コマンドの省略名
gdbのコマンドは(区別できる範囲で)短く省略できます.
例えば,runはr,quitはq,それぞれ1文字でコマンドを指定できます.
慣れてきたらコマンドの省略名を使いましょう.
コマンドライン引数argvを指定して実行
// argv.c
#include <stdio.h>
int main (int argc, char *argv[])
{
for (int i = 0; i < argc; i++) {
printf ("argv[%d]=%s\n", i, argv [i]);
}
}
$ gcc -g argv.c
$ gdb ./a.out
Reading symbols from ./a.out...
(gdb) ❶ run a b c d
argv[0]=/mnt/hgfs/gondow/project/linux-x86-64-programming/src/asm/a.out
argv[1]=a
argv[2]=b
argv[3]=c
argv[4]=d
[Inferior 1 (process 20303) exited normally]
(gdb)
- コマンドライン引数を与えてデバッグしたい場合は,
runコマンドに続けて引数を与えます(ここではa b c d).
標準入出力を切り替えて実行
// cat.c
#include <stdio.h>
int main ()
{
int c;
while ((c = getchar ()) != EOF) {
putchar (c);
}
}
$ gcc -g cat.c
$ cat foo.txt
hello
byebye
$ gdb ./a.out
(gdb) run ❶ < foo.txt ❷ > out.txt
(gdb) quit
$ cat out.txt
hello
byebye
- 標準入出力をリダイレクトして(切り替えて)実行したい場合は,
通常のシェルのときと同様に
runコマンドの後で, ❶<や❷>を使って行います.
segmentation fault (あるいは bus error)の原因を探る
// segv.c
#include <stdio.h>
int main ()
{
int *p = (int *)0xDEADBEEF; // アクセスNGそうなアドレスを代入
printf ("%d\n", *p);
}
$ gcc -g segv.c
$ ./a.out
❶ Segmentation fault (core dumped)
$ gdb ./a.out
(gdb) r
Program received signal SIGSEGV, ❷ Segmentation fault.
0x0000555555555162 in ❸ main () at ❹ segv.c:6
6 ❺ printf ("%d\n", *p);
(gdb) ❻ print/x p
$1 = ❼ 0xdeadbeef
(gdb) ❽ print/x *p
❾ Cannot access memory at address 0xdeadbeef
(gdb) quit
segv.cをコンパイルして実行すると❶ segmentation fault が起きました. segumentation fault や bus error は正しくないポインタを使用して メモリにアクセスすると発生します.gdb上でa.outを実行すると,gdb上でも ❷ segmentation fault が起きました. 発生場所は ❹ ファイルsegv.cの6行目,❸main関数内と表示されています. また,6行目のソースコード ❺printf ("%d\n", *p);も表示されています.- 変数
pが怪しいので,❻print/x pコマンドで変数pの値を表示させます./xは「16進数で表示」を指示するオプションです. 怪しそうな0xDEADBEEFという値が表示されました. (printコマンドはpと省略可能です).
怪しいアドレスとは
まず,8の倍数ではないアドレスは怪しいです(正しいアドレスのこともあります). 特に奇数のアドレスは怪しいです(正しいこともありますが). アラインメント制約を守るため, 多くのデータが4の倍数や8の倍数のアドレスに配置されるからです.
また慣れてくると,例えば「0x7ffde9a98000はスタックのアドレスっぽい」と
感じるようになります.
「これ,どこのメモリだろう」と思ったら
メモリマップ
やgdb上でinfo proc mapの結果を見て調べるのが良いです.
- 念のため,
printコマンドで*pを表示させると (❽print/x *p), この番地にはアクセスできないことが確認できました (❾Cannot access memory at address 0xdeadbeef).
変数の値を表示 (print)
// calcx.c
int main ()
{
int x = 10;
x += 3;
x += 4;
return x;
}
$ gcc -g calcx.c
$ gdb ./a.out
(gdb) ❶ b main
Breakpoint 1 at 0x1131: file calcx.c, line 3.
(gdb) ❷ r
❸ Breakpoint 1, main () at calcx.c:3
3 ❹ int x = 10;
(gdb) ❺ s
❻ 4 x += 3;
(gdb) ❼ p x
❽ $1 = 10
(gdb) s
5 x += 4;
(gdb) p x
$2 = 13
(gdb) q
- 使った短縮コマンド:
b(break),r(run),s(step),p(print),q(quit) - ❶
b mainで,main関数にブレークポイントを設定し, ❷rで実行を開始すると,❸main関数で実行が一時停止しました. ❹int x = 10;`は次に実行する文です(まだ実行していません).
breakで設定できる場所
ここではb mainと関数名を指定しました.
他にも以下のように行番号やファイル名も使えます.
| 場所の指定 | 説明 |
|---|---|
b 10 | (今実行中のファイルの)10行目 |
b +5 | 今の実行地点から5行後 |
b -5 | 今の実行地点から5行前 |
b main | (今実行中のファイルの)関数main |
b main.c:main | ファイルmain.c中のmain関数 |
b main.c:10 | ファイルmain.cの10行目 |
- ❺
sで,1行だけ実行を進めます. 4行目 (❻4 x += 3;)を実行する手前で実行が止まります. - ここで
❼ p xとしてxの値を表示させます.❽ $1 = 10と表示され,xの値は10と分かりました. ($1はgdb中で使える変数ですが,ここでは使っていません).
変数の値を自動表示 (display)
// calcx.c
int main ()
{
int x = 10;
x += 3;
x += 4;
return x;
}
$ gcc -g calcx.c
$ gdb ./a.out
(gdb) b main
Breakpoint 1 at 0x1131: file calcx.c, line 4.
(gdb) r
Breakpoint 1, main () at calcx.c:4
4 int x = 10;
(gdb) ❶ disp x
❷ 1: x = 21845
(gdb) s
5 x += 3;
❸ 1: x = 10
(gdb) s
6 x += 4;
❹ 1: x = 13
(gdb) s
7 return x;
❺ 1: x = 17
(gdb) q
- 使った短縮コマンド:
b(break),r(run),s(step),disp(display),q(quit) - 「何度も
p xと入力するのが面倒」という人はdisplayを使って, 変数の値を自動表示させましょう.displayは実行が停止するたびに, 指定した変数の値を表示します. - ここでは❶
disp xとして,変数xの値を自動表示させます. (❷1: x = 21845と出てるのは,変数xが未初期化のため,ゴミの値が表示されたからです). sで1行ずつ実行を進めるたびに, 変数xの値が,❸1: x = 10→ ❹1: x = 13→ ❺1: x = 17と変化するのが分かります.
条件付きブレークポイントの設定とバックトレース表示 (break if, backtrace)
// fact.c
#include <stdio.h>
int fact (int n)
{
if (n <= 0)
return 1;
else
return n * fact (n - 1);
}
int main ()
{
printf ("%d\n", fact (5));
}
$ gcc -g fact.c
$ gdb ./a.out
(gdb) ❶ b fact if n==0
Breakpoint 1 at 0x1158: file fact.c, line 5.
(gdb) ❷ r
❸ Breakpoint 1, fact (n=0) at fact.c:5
5 if (n <= 0)
(gdb) ❹ bt
#0 fact (n=0) at fact.c:5
#1 0x0000555555555172 in fact (n=1) at fact.c:8
#2 0x0000555555555172 in fact (n=2) at fact.c:8
#3 0x0000555555555172 in fact (n=3) at fact.c:8
#4 0x0000555555555172 in fact (n=4) at fact.c:8
#5 0x0000555555555172 in fact (n=5) at fact.c:8
❺#6 0x000055555555518a in main () at fact.c:13
(gdb) q
- 使った短縮コマンド:
b(break),r(run),bt(backtrace),q(quit) - 階乗を計算する
factは再帰的に何度も呼び出されますが, ここでは「引数nの値が0のときだけブレークしたい」とします. - ❶
b fact if n==0で,引数nが0の時だけfactの実行を停止する設定をして, ❷rで実行を開始すると,意図通り ❸fact (n=0)で実行停止できました. - ここで,❹
btとしてバックトレースを表示させます. バックトレースとは「今,実行中の関数から遡ってmain関数に至るまでの 関数呼び出し系列」のことです. ❺main関数から,fact(n=5)→fact(n=4)→(中略) →fact(n=0)と呼び出されたことが分かります. - なお,
backtrace fullとすると, バックトレースに加えて,局所変数の値も表示されます.
注: Ubuntu 20.04 LTSなど,少し古いLinuxを使っている人は バックトレース中の引数の値が間違った表示 になることがあります(私はなりました). これは古い
gdbがendbr64命令に非対応だったからです. Ubuntu 22.04 LTSなど最新のLinuxにすることをお勧めします (2023年8月現在).
変数や式の変更監視 (watch)
// calcx.c
int main ()
{
int x = 10;
x += 3;
x += 4;
return x;
}
$ gcc -g calcx.c
$ gdb ./a.out
(gdb) b main
Breakpoint 1 at 0x1131: file calcx.c, line 4.
(gdb) r
Breakpoint 1, main () at calcx.c:4
4 int x = 10;
(gdb) ❶ wa x
Hardware watchpoint 2: x
(gdb) ❷ c
Continuing.
Hardware watchpoint 2: x
❸ Old value = 21845
❹ New value = 10
main () at calcx.c:5
5 x += 3;
(gdb) c
Continuing.
Hardware watchpoint 2: x
Old value = 10
New value = 13
main () at calcx.c:6
6 x += 4;
(gdb) c
Continuing.
Hardware watchpoint 2: x
Old value = 13
New value = 17
main () at calcx.c:7
7 return x;
(gdb) q
-
使った短縮コマンド:
b(break),r(run),wa(watch),c(continue),q(quit) -
watchは指定した変数や式の変化(書き込み)を監視します. 「どこで値が変わるのかわからない」という場合に便利です. ここでは ❶wa xとして変数xを監視する設定を行い, 実行を再開します (❷c). 変更箇所で自動的にブレークされて, 変更前後の値が表示されました(❸Old value = 21845,❹New value = 10). -
breakと同様に,watchにもifで条件を指定できます. 例えば,wa x if x==13とすると,変数の値が13になった時点でブレークできます. -
watchはハードウェア機能を使うため, 高速ですが指定できる個数に限りがあります. -
watchには-lというオプションを指定可能です. このオプションを指定すると,指定した変数や式の左辺値(つまりアドレス)を計算して, そのアドレスへの書き込みを(変数のスコープを無視して)監視します. 計算結果がアドレスでなかった場合(つまり左辺値を持たない式だった場合)はgdbはエラーを表示します.例えば,
staticなしの局所変数(自動変数)に対してwatchを指定すると, この局所変数のスコープから出る際に,以下のメッセージが出て ウォッチポイントは削除されてしまいます.-lオプションをつけると削除されません.Watchpoint 2 deleted because the program has left the block in which its expression is valid. -
watchは「書き込み」を監視します. 「読み込み」を監視したい時はrwatch, 「読み書き」の両方を監視したい時はawatchを使って下さい.
実行中断と,実行途中での変数の値の変更
// inf-loop.c
#include <stdio.h>
int main ()
{
int x = 1, n = 0;
while (x != 0) {
n++;
}
printf ("hello, world\n");
}
$ gcc -g inf-loop.c
$ gdb ./a.out
(gdb) r
❶ ^C
❷ Program received signal SIGINT, Interrupt.
main () at inf-loop.c:7
7 while (x != 0) {
(gdb) ❸ p x=0
$1 = 0
(gdb) ❹ c
Continuing.
❺ hello, world
(gdb) q
- 使った短縮コマンド:
r(run),p(print),c(continue),q(quit) - このプログラムは無限ループがあるため,実行を開始すると
gdbに制御が戻ってきません.そこで,ctrl-c(❶^C)を入力して プログラムを一時停止します. - 変数
xの値をゼロにすれば無限ループを抜けるので,printコマンドで ❸p x=0とすることで,変数xにゼロを代入します. このようにprintコマンドは変数を変更したり, 副作用のある関数を呼び出すことができます(例えば,p printf("hello\n")として). - 実行を再開すると (❹
c),❺hello, worldが表示され, 無事に無限ループを抜けることができました.
再開場所の変更 (jump)
// inf-loop2.c
#include <stdio.h>
#include <time.h>
int main ()
{
int n = 0;
while (time (NULL)) {
n++;
}
printf ("hello, world\n");
}
$ gcc -g inf-loop2.c
$ gdb ./a.out
(gdb) r
^C
Program received signal SIGINT, Interrupt.
main () at inf-loop2.c:8
8 n++;
(gdb) ❶ l
3 #include <time.h>
4 int main ()
5 {
6 int n = 0;
7 while (time (NULL)) {
8 n++;
9 }
❷ 10 printf ("hello, world\n");
11 }
(gdb) ❸ j 10
Continuing at 0x555555555191.
❹ hello, world
(gdb) q
- 使った短縮コマンド:
r(run),l(list),j(jump),q(quit) - 先程と異なり,今回,無限ループを抜けるのに,
単純に変数の値を変える方法は使えません.
(システムコール
timeは1970/1/1からの経過秒数を返します). そこで,ここではjumpコマンドを使います.jumpは「指定した場所から実行を再開」します. (一方,continueは「実行を一時停止した場所から実行を再開」します).
別の方法
別の方法として,timeが返した戻り値は%raxレジスタに入っているので,
timeからのリターン直後にp $rax=0とする方法もあります
(レジスタ%raxの値が0になります).
また p $rip=0x0000555555555191として,直接 %ripレジスタの値を
変更する方法もあります(jumpコマンドの中身はまさにこれでしょう).
- 何行目から実行を再開すればよいかを調べるために,
listコマンドを使ってソースコードの一部を表示します. (listに表示する行番号や関数名を指定することもできます). 10行目から再開すれば良さそうと分かります. - 10行目から実行を再開すると(❷
j 10), 無事に無限ループを抜けられました (❸hello, world).
なお,layout srcとすると,ソースコードを表示するウインドウが現れます.
ソースコードと現在の実行位置を見ながらデバッグできるので便利です.
(時々画面が乱れるので,その時はctrl-l(コントロールL)を押して,
画面を再描画して下さい).
このモードから抜けるには,tui disableあるいはctrl-x aを入力します.
型の表示 (whatis, ptype)
// struct2.c
#include <stdio.h>
#include <stddef.h> // for size_t
struct foo {
int a1;
char a2;
size_t a3;
};
int main ()
{
struct foo f = {10, 'a', 20};
printf ("%d\n", f.a1);
}
$ gcc -g struct2.c
$ gdb ./a.out
Reading symbols from ./a.out...
(gdb) b main
Breakpoint 1 at 0x1155: file struct2.c, line 12.
(gdb) r
Breakpoint 1, main () at struct2.c:12
12 struct foo f = {10, 'a', 20};
(gdb) ❶ whatis f
type = struct foo
(gdb) ❷ ptype f
type = struct foo {
int a1;
char a2;
size_t a3;
}
(gdb) ❸ ptype/o f
/* offset | size */ type = struct foo {
/* 0 | 4 */ int a1;
/* 4 | 1 */ char a2;
/* XXX 3-byte hole */
/* 8 | 8 */ size_t a3;
/* total size (bytes): 16 */
}
(gdb) ❹ ptype struct foo
type = struct foo {
int a1;
char a2;
size_t a3;
}
(gdb) ❺ whatis f.a3
type = size_t
(gdb) ❻ ptype f.a3
type = unsigned long
(gdb) ptype size_t
type = unsigned long
(gdb) ❼ info types foo
All types matching regular expression "foo":
File struct2.c:
4: struct foo;
(gdb) q
-
whatisやptypeは式や型名の型情報を表示します. -
whatisは構造体の中身を表示しませんが (❶whatis f),ptypeは表示します (❷ptype f)./oオプションを付けると,構造体のフィールドのオフセットとサイズ, 構造体中のパディング(ホール,穴)も表示してくれます (❸ptype/o f). -
whatisやptypeには型名も指定できます (❹ptype struct foo). -
whatisはtypedefを1レベルまでしか展開しませんが (❺whatis f.a3),ptypeは全て展開します (❻ptype f.a3). -
info typesを使うと,正規表現にマッチする型名一覧を表示します (❼info types foo).
gdbの実行例 (アセンブリ言語編)
アドレス指定でブレイク,レジスタの値を表示
// hello.c
#include <stdio.h>
int main ()
{
printf ("hello\n");
}
$ gcc -g hello.c
$ gdb ./a.out
(gdb) ❶ b main
Breakpoint 1 at 0x1151: file hello.c, line 5.
(gdb) r
Breakpoint 1, main () at hello.c:5
5 printf ("hello\n");
(gdb) ❷ disas
Dump of assembler code for function main:
0x0000555555555149 <+0>: endbr64
0x000055555555514d <+4>: push %rbp
0x000055555555514e <+5>: mov %rsp,%rbp
❸ => 0x0000555555555151 <+8>: lea 0xeac(%rip),%rax # 0x555555556004
0x0000555555555158 <+15>: mov %rax,%rdi
0x000055555555515b <+18>: call 0x555555555050 <puts@plt>
0x0000555555555160 <+23>: mov $0x0,%eax
0x0000555555555165 <+28>: pop %rbp
0x0000555555555166 <+29>: ret
End of assembler dump.
(gdb) ❹ b *0x0000555555555149
Breakpoint 2 at 0x555555555149: file hello.c, line 4.
(gdb) r
The program being debugged has been started already.
Start it from the beginning? (y or n) y
Breakpoint 2, main () at hello.c:4
4 {
(gdb) ❺ disp/i $rip
1: x/i $rip
❻ => 0x555555555149 <main>: endbr64
(gdb) ❼ si
0x000055555555514d 4 {
❽ 1: x/i $rip
❾ => 0x55555555514d <main+4>: push %rbp
(gdb) si
0x000055555555514e 4 {
1: x/i $rip
=> 0x55555555514e <main+5>: mov %rsp,%rbp
(gdb) ❿ p/x $rbp
$1 = 0x1
(gdb) ⓫ i r
rax 0x555555555149 93824992235849
rbx 0x0 0
rcx 0x555555557dc0 93824992247232
rdx 0x7fffffffdfb8 140737488347064
rsi 0x7fffffffdfa8 140737488347048
rdi 0x1 1
rbp 0x1 0x1
rsp 0x7fffffffde90 0x7fffffffde90
(長いので中略)
(gdb) q
-
使った短縮コマンド:
b(break),r(run),disas(disassemble),si(stepi),p(print),i r(info registers),q(quit) -
まず,
main関数にブレークポイントを設定して(❶b main), 実行を開始すると実行が一時停止するのですが, 逆アセンブル (❷disas)して確かめると, 機械語命令レベルではmain関数の先頭で実行を一時停止していません.- ❸
=> 0x0000555555555151 <+8>:の<+8>が 「main関数の先頭から8バイト目」であることを示しています.gdbは関数名を指定してブレークした場合, 関数プロローグが終わった場所でブレークします. disassembleは逆アセンブル結果を表示します. 何も指定しないと実行中の場所付近の逆アセンブル結果を表示します. 関数名やアドレスを指定することも可能です. また,disassembleには以下のオプションを指定可能です.
- ❸
| オプション | 説明 |
|---|---|
/s | ソースコードも表示 (表示順は機械語命令の順番) |
/m | ソースコードも表示 (表示順はソースコードの順番) |
/r | 機械語命令の16進ダンプも表示 |
-
ここでは
main関数の先頭番地を指定してブレークポイントを設定してみます (❹b *0x0000555555555149).行番号と区別するため*が必要です. 実行を開始するとブレークしました. -
ブレークした番地と,その番地の機械語命令を表示すると便利です. そのため,❺
disp/i $ripとしました. これはプログラムカウンタ%ripの値を命令として(i, instruction)自動表示せよ, という意味です.(gdbではレジスタを指定するのに%ripではなく,$ripのようにドルマーク$を使います). これにより,❻=> 0x555555555149 <main>: endbr64が表示されました.- 次に実行する番地は
0x555555555149番地 - その番地の命令は
endbr64命令
- 次に実行する番地は
-
stepi(❼si)を使うと,1行ではなく,機械語命令を1つ実行する ステップ実行になります. ❺disp/i $ripの効果で, 次に実行される命令の番地とニモニックが表示されました (❾=> 0x55555555514d <main+4>: push %rbp). なお,❽1: x/i $ripとあるのは, ❺disp/i $ripはprintではなく,x/i $ripコマンドで機械語命令を出力するからです (xはメモリ中の値を表示するコマンドです./iはフォーマット指定で「機械語命令」(instruction)を意味します). -
レジスタの値を表示するには
printを使います (❿p/x $rbp)/xはフォーマット指定で「16進数」(hexadecimal)を意味します. 値は1でした ($1 = 0x1). -
なお,
info registers(⓫i r)で,全ての汎用レジスタの値を 一括表示できます.
メモリ中の値(機械語命令)を表示する (x)
// hello.c
#include <stdio.h>
int main ()
{
printf ("hello\n");
}
$ gdb ./a.out
Reading symbols from ./a.out...
(gdb) b main
Breakpoint 1 at 0x1151: file hello.c, line 5.
(gdb) disp/x $rip
1: /x $rip = <error: No registers.>
(gdb) r
Breakpoint 1, main () at hello.c:5
5 printf ("hello\n");
1: /x $rip = 0x555555555151
(gdb) ❶ disas/r
Dump of assembler code for function main:
0x0000555555555149 <+0>: f3 0f 1e fa endbr64
0x000055555555514d <+4>: 55 push %rbp
0x000055555555514e <+5>: 48 89 e5 mov %rsp,%rbp
❷ => 0x0000555555555151 <+8>: 48 8d 05 ac 0e 00 00 lea 0xeac(%rip),%rax # 0x555555556004
0x0000555555555158 <+15>: 48 89 c7 mov %rax,%rdi
0x000055555555515b <+18>: e8 f0 fe ff ff call 0x555555555050 <puts@plt>
0x0000555555555160 <+23>: b8 00 00 00 00 mov $0x0,%eax
0x0000555555555165 <+28>: 5d pop %rbp
0x0000555555555166 <+29>: c3 ret
End of assembler dump.
(gdb) ❸ x/7xb 0x0000555555555151
❹ 0x555555555151 <main+8>: 0x48 0x8d 0x05 0xac 0x0e 0x00 0x00
(gdb) ❺ x/7xb $rip
0x555555555151 <main+8>: 0x48 0x8d 0x05 0xac 0x0e 0x00 0x00
(gdb) ❻ x/7xb $rip+7
0x555555555158 <main+15>: 0x48 0x89 0xc7 0xe8 0xf0 0xfe 0xff
(gdb) q
-
使った短縮コマンド:
b(break),r(run),disp(display),disas(disassemble),x(x),q(quit) -
16進ダンプ付き(
/r)で逆アセンブルすると (❶disas/r),
❷ => 0x0000555555555151 <+8>: 48 8d 05 ac 0e 00 00 lea 0xeac(%rip),%rax # 0x555555556004
と表示されました.
0x0000555555555151番地には lea 0xeac(%rip),%raxという命令があり,
機械語バイト列としては 48 8d 05 ac 0e 00 00だと分かりました.
-
xコマンドでメモリ中の値を表示できます. 例えば,❸x/7xb 0x0000555555555151は, 「0x0000555555555151番地のメモリの値を表示せよ. 表示は1バイト単位(b),16進表記(x)のものを7個,表示せよ」という意味です. その結果,逆アセンブル結果と同じ値が表示されました (❹0x555555555151 <main+8>: 0x48 0x8d 0x05 0xac 0x0e 0x00 0x00). -
なお,
xコマンドに与える指定は NFT という形式です.
N は表示個数(デフォルト1),Fはフォーマット,Uは単位サイズの指定です. FとUの順番は逆でもOKです. (例:4gxは「8バイトデータを16進数表記で4個表示」を意味する). FとUで指定できるものは以下の通りです.
| フォーマット F | 説明 |
|---|---|
x | 16進数 (hexadecimal) |
d | 符号あり10進数 (decimal) |
u | 符号なし10進数 (unsigned) |
t | 2進数 (two) |
c | 文字 (char) |
s | 文字列 (string) |
i | 機械語命令 (instruction) |
| 単位サイズ U | 説明 |
|---|---|
b | 1バイト (byte) |
h | 2バイト (half-word) |
w | 4バイト (word) |
g | 8バイト (giant) |
xへのアドレス指定にレジスタの値 (❺x/7xb $rip)や レジスタ値を使った足し算 (❻x/7xb $rip+7)も指定できます.
メモリ中の値(スタック)を表示する (x)
// fact.c
#include <stdio.h>
int fact (int n)
{
if (n <= 0)
return 1;
else
return n * fact (n - 1);
}
int main ()
{
printf ("%d\n", fact (5));
}
$ gcc -g fact.c
$ gdb ./a.out
Reading symbols from ./a.out...
(gdb) b main
Breakpoint 1 at 0x1180: file fact.c, line 13.
(gdb) b fact
Breakpoint 2 at 0x1158: file fact.c, line 5.
(gdb) r
Breakpoint 1, main () at fact.c:13
13 printf ("%d\n", fact (5));
(gdb) ❶ p/x $rbp
$1 = ❷ 0x7fffffffde90
(gdb) c
Continuing.
Breakpoint 2, fact (n=5) at fact.c:5
5 if (n <= 0)
(gdb) ❸ x/1xg $rbp + 8
0x7fffffffde88: ❹ 0x000055555555518a
(gdb) disas main
Dump of assembler code for function main:
0x0000555555555178 <+0>: endbr64
0x000055555555517c <+4>: push %rbp
0x000055555555517d <+5>: mov %rsp,%rbp
0x0000555555555180 <+8>: mov $0x5,%edi
0x0000555555555185 <+13>: call 0x555555555149 <fact>
❺ 0x000055555555518a <+18>: mov %eax,%esi
0x000055555555518c <+20>: lea 0xe71(%rip),%rax # 0x555555556004
0x0000555555555193 <+27>: mov %rax,%rdi
0x0000555555555196 <+30>: mov $0x0,%eax
0x000055555555519b <+35>: call 0x555555555050 <printf@plt>
0x00005555555551a0 <+40>: mov $0x0,%eax
0x00005555555551a5 <+45>: pop %rbp
0x00005555555551a6 <+46>: ret
End of assembler dump.
(gdb) ❻ x/1gx $rbp
0x7fffffffde80: ❼ 0x00007fffffffde90
(gdb) q
-
使った短縮コマンド:
b(break),r(run),p(print),c(continue),x(x),disas(disassemble),q(quit) -
mainとfactにブレークポイントを設定し,main関数でブレークした時点で,%rbpの値を調べると (❶p/x $rbp), ❷0x7fffffffde90と分かりました. これはmain関数のスタックフレームの一番下のアドレスです.

-
factでブレークした時点で,スタックフレームは上図になっているはずです. まずメモリ参照8(%rbp)に正しく戻り番地が入っているか調べます.$rbp+8番地のメモリの値を調べると (❸x/1xg $rbp+8), ❹0x000055555555518aが入っていました. (1xgは,8バイトデータを16進数で1個分出力する,を意味します).main関数を逆アセンブルすると,
0x0000555555555185 <+13>: call 0x555555555149 <fact>
❺ 0x000055555555518a <+18>: mov %eax,%esi
この番地(❹ 0x000055555555518a)はcall factの次の命令なので,
戻り番地として正しいことを確認できました.
- 次に
fact(5)のスタックフレーム中の「古い%rbp」の値が正しいかを調べます.%rbpが指すメモリの値を調べると(❻x/1gx $rbp), ❼0x00007fffffffde90が入っていました. これは ❷0x7fffffffde90と一致するので, 「古い%rbp」が正しいことを確認できました.
シンボルテーブル (info address, info symbol)
// hello.c
#include <stdio.h>
int main ()
{
printf ("hello\n");
}
$ gcc -g hello.c
$ gdb ./a.out
Reading symbols from ./a.out...
(gdb) ❶ info address main
Symbol "main" is a function at address ❷ 0x1149.
(gdb) b main
Breakpoint 1 at 0x1151: file hello.c, line 5.
(gdb) r
Breakpoint 1, main () at hello.c:5
5 printf ("hello\n");
(gdb) ❸ info address main
Symbol "main" is a function at address ❹ 0x555555555149.
(gdb) info address printf
Symbol "printf" is at 0x7ffff7c60770 in a file ❺ compiled without debugging.
(gdb) disas main
Dump of assembler code for function main:
0x0000555555555149 <+0>: endbr64
0x000055555555514d <+4>: push %rbp
0x000055555555514e <+5>: mov %rsp,%rbp
=> 0x0000555555555151 <+8>: lea 0xeac(%rip),%rax # 0x555555556004
0x0000555555555158 <+15>: mov %rax,%rdi
0x000055555555515b <+18>: call 0x555555555050 <puts@plt>
0x0000555555555160 <+23>: mov $0x0,%eax
0x0000555555555165 <+28>: pop %rbp
0x0000555555555166 <+29>: ret
End of assembler dump.
(gdb) ❻ info symbol 0x0000555555555149
main in section .text of /mnt/hgfs/gondow/project/linux-x86-64-programming/src/asm/a.out
(gdb) ❼ info symbol 0x0000555555555166
main + 29 in section .text of /mnt/hgfs/gondow/project/linux-x86-64-programming/src/asm/a.out
(gdb) q
-
使った短縮コマンド:
b(break),r(run),disas(disassemble),q(quit) -
info addressは指定したシンボルのアドレスを表示します. プログラム実行前の場合(❶info address main), ファイルa.out中のアドレスを表示します(❷0x1149). これはnmコマンドやobjdump -dで得られるアドレスと同じです.
$ nm ./a.out | egrep main
U __libc_start_main@GLIBC_2.34
0000000000001149 T main
-
一方,実行後では (❸
info address main),main関数のメモリ上でのアドレスが得られます (❹0x555555555149). なお,printfのアドレスを調べると, デバッグ情報無しでコンパイルされた旨のメッセージも表示されました (❺compiled without debugging). -
info symbolは指定したアドレスを持つシンボルを返します. 例えば,main関数の先頭アドレスを指定すると ( ❻info symbol 0x0000555555555149),mainを表示しました. アドレスはmain関数の途中のアドレスでも大丈夫です ( ❼info symbol 0x0000555555555166).
お便利機能
helpコマンド
help (h)はコマンドのヘルプ(説明)を表示します.
(gdb) help step
step, s
Step program until it reaches a different source line.
Usage: step ❶ [N]
Argument N means step N times (or till program stops for another reason).
例えば,help stepとすると,stepに回数を指定できる❶ことが分かりました.
[N]のカギカッコは省略可能な引数を意味します.
aproposコマンド
apropos(apr)は指定した正規表現をヘルプに含むコマンドを表示します.
(gdb) apropos break
advance -- Continue the program up to the given location (same form as args for break command).
break, brea, bre, br, b -- Set breakpoint at specified location.
break, brea, bre, br, b -- Set breakpoint at specified location.
break-range -- Set a breakpoint for an address range.
breakpoints -- Making program stop at certain points.
clear, cl -- Clear breakpoint at specified location.
commands -- Set commands to be executed when the given breakpoints are hit.
(以下略)
例えば,apropos breakとすると,breakをヘルプに含むコマンド一覧を表示します.
breakに関係するコマンドを知りたい場合に便利です.
補完とヒストリ機能
| コマンド | 省略名 | 説明 |
|---|---|---|
ctrl-p | 1つ前のコマンドを表示 | |
ctrl-n | 1つ後のコマンドを表示 | |
show commands | 自分が入力したコマンド履歴を表示 | |
ctrl-i | コマンド等を補完 (TABキーでも同じ) 2回押すと候補一覧を表示 | |
ctrl-l | 画面をクリア・リフレッシュ |
(gdb) br TAB (br とTABの間にはスペースを入れない)
(gdb) break (breakまで補完)
(gdb) break TAB (ここで2回TABを押すと)
break break-range (breakで始まるコマンドの一覧を表示)
(gdb) b main
(gdb) r
(gdb) step
(gdb) ctrl-p (ctrl-p を押すと)
(gdb) step (1つ前のコマンド step が表示された)
TUI (テキストユーザインタフェース)
layoutコマンドで,TUIの表示モードを使えます.
src (ソースコード),asm (アセンブリコード),
regs (レジスタ表示)を選べます.
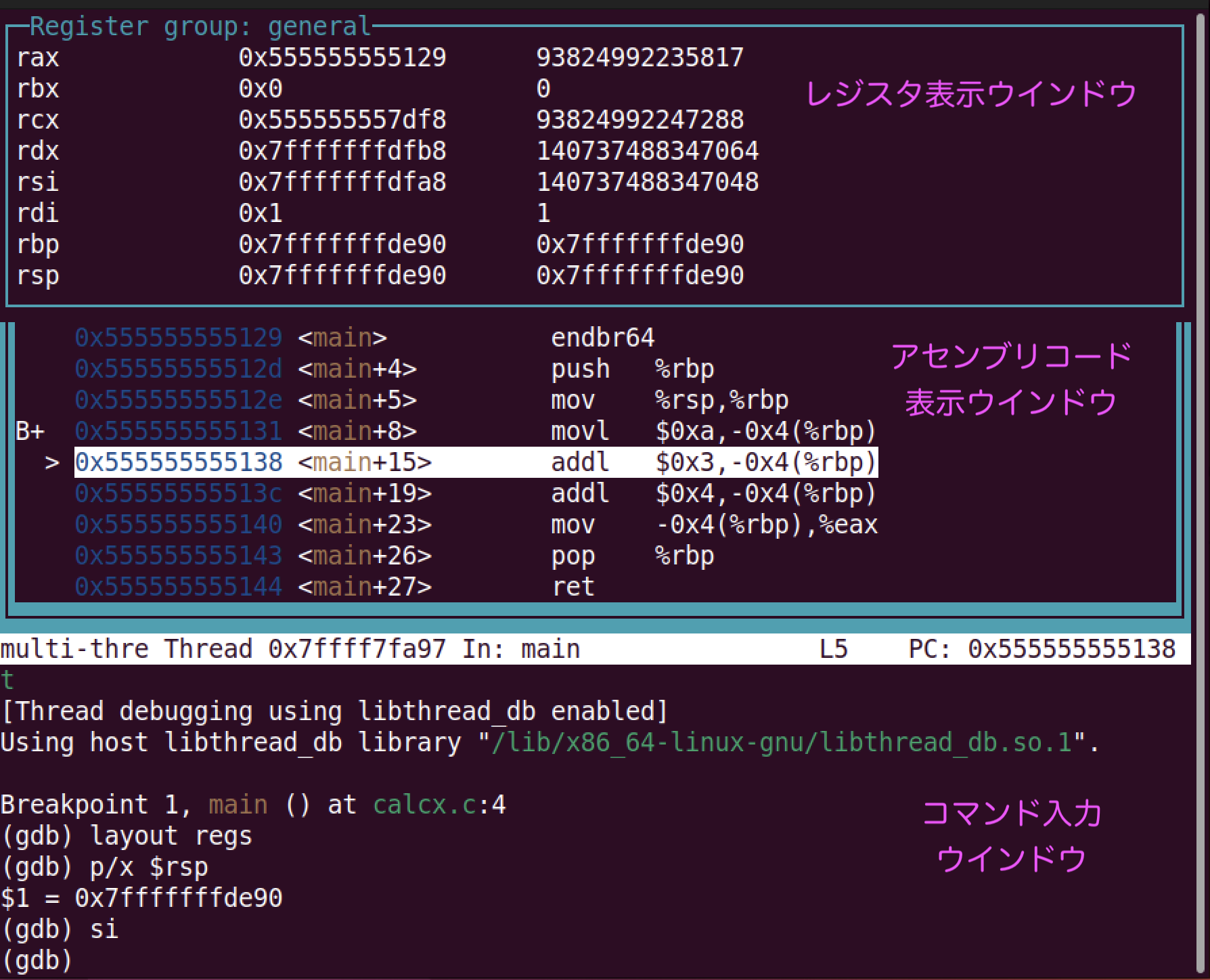
上図はlayout asm後にlayout regsとした時の画面です.
元の表示方法に戻るにはctrl-x aとして下さい.
ブレークポイントの設定
場所の指定
| 場所の指定 | 説明 |
|---|---|
b 10 | (今実行中のファイルの)10行目 |
b +5 | 今の実行地点から5行後 |
b -5 | 今の実行地点から5行前 |
b main | (今実行中のファイルの)関数main |
b main.c:main | ファイルmain.c中のmain関数 |
b main.c:10 | ファイルmain.cの10行目 |
条件付きブレークポイント
// fact.c
#include <stdio.h>
int fact (int n)
{
if (n <= 0)
return 1;
else
return n * fact (n - 1);
}
int main ()
{
printf ("%d\n", fact (5));
}
$ gcc -g fact.c
$ gdb ./a.out
Reading symbols from ./a.out...
(gdb) ❶ b fact if n==0
Breakpoint 1 at 0x1158: file fact.c, line 5.
(gdb) ❷ i b
Num Type Disp Enb Address What
1 breakpoint keep y 0x0000000000001158 in fact at fact.c:5
stop only if ❸ n==0
(gdb) ❹ cond 1 n==1
(gdb) i b
Num Type Disp Enb Address What
1 breakpoint keep y 0x0000000000001158 in fact at fact.c:5
stop only if n==1
(gdb) ❺ cond 1
Breakpoint 1 now unconditional.
(gdb) i b
Num Type Disp Enb Address What
1 breakpoint keep y 0x0000000000001158 in fact at fact.c:5
(gdb) q
- 使った短縮コマンド:
b(break),i b(info breakpoints),cond(condition),q(quit) - 条件付きブレークポイントは
ifを使って指定します (❶b fact if n==0). i bで,現在のブレークポイントの状況を確認できます (❷i b). 番号1のブレークポイントとして,❸n==0という条件が設定されています.condで,指定した番号のブレークポイントの条件を変更できます. ここでは ❹cond 1 n==1として,条件をn==1に変更しました.condで新しい条件を指定しないと,条件が外れます(❺cond 1).
コマンド付きブレークポイント
commandsで「ブレークした時に実行するコマンド列」を指定できます.
$ gcc -g fact.c
$ gdb ./a.out
(gdb) b fact
Breakpoint 1 at 0x1158: file fact.c, line 5.
(gdb) ❶ commands
Type commands for breakpoint(s) 1, one per line.
End with a line saying just "end".
>print n
>c
❷>end
(gdb) ❸ r
Breakpoint 1, fact (n=5) at fact.c:5
5 if (n <= 0)
$1 = 5
Breakpoint 1, fact (n=4) at fact.c:5
5 if (n <= 0)
$2 = 4
Breakpoint 1, fact (n=3) at fact.c:5
5 if (n <= 0)
$3 = 3
Breakpoint 1, fact (n=2) at fact.c:5
5 if (n <= 0)
$4 = 2
Breakpoint 1, fact (n=1) at fact.c:5
5 if (n <= 0)
$5 = 1
Breakpoint 1, fact (n=0) at fact.c:5
5 if (n <= 0)
$6 = 0
120
(gdb)
- 引数無しで❶
commandsとすると,最後に設定したブレークポイントに対して コマンドを設定します.commands 2やcommands 5-7などブレークポイントの番号や範囲の指定もできます. commandsに続けて,実行したいコマンドを入力します. 最後に❷endを指定します.- ❸実行すると,全ての
factの呼び出しが一気に表示できました. 指定したコマンド中にcontinueを指定できるのがとても便利です. - ここでは不使用ですが,コマンド列の最初に
silentを使用すると, ブレーク時のメッセージを非表示にできます.
ステップ実行
ステップ実行の種類
| ステップ実行の種類 | gdbコマンド | 短縮形 | 説明 |
|---|---|---|---|
| ステップイン | step | s | 1行実行を進める(関数呼び出しは中に入って1行を数える) |
| ステップオーバー | next | n | 1行実行を進める(関数呼び出しはまたいで1行を数える) |
| ステップアウト | finish | fin | 今の関数がリターンするまで実行を進める |
| 実行再開 | continue | c | ブレークされるまで実行を進める |

- 上図で,今,
B();を実行する直前でブレークしているとします. stepすると,関数Bのprintf("B\n");まで実行を進めます.nextすると,関数Aのprintf("A\n");まで実行を進めます.finishすると,関数mainのprintf("main\n");まで実行を進めます.
ステップインの実行例 (step)
#include <stdio.h>
void B ()
{
printf ("B\n");
}
void A ()
{
B ();
printf ("A\n");
}
int main ()
{
A ();
printf ("main\n");
}
$ gcc -g step.c
$ gdb ./a.out
Reading symbols from ./a.out...
(gdb) b A
Breakpoint 1 at 0x116b: file step.c, line 8.
(gdb) r
Breakpoint 1, A () at step.c:8
8 B ();
(gdb) ❶ s
B () at step.c:4
4 ❷ printf ("B\n");
step(❶ s)すると,❷ printf ("B\n");まで実行しました.
ステップオーバーの実行例 (next)
$ gcc -g step.c
$ gdb ./a.out
Reading symbols from ./a.out...
(gdb) b A
Breakpoint 1 at 0x116b: file step.c, line 8.
(gdb) r
Breakpoint 1, A () at step.c:8
8 B ();
(gdb) ❸ n
B
9 ❹ printf ("A\n");
next(❸ n)すると,❹ printf ("A\n");まで実行しました.
ステップオーバーの実行例 (finish)
$ gdb ./a.out
Reading symbols from ./a.out...
(gdb) b A
Breakpoint 1 at 0x116b: file step.c, line 8.
(gdb) r
Starting program: /mnt/hgfs/gondow/project/linux-x86-64-programming/src/asm/a.out
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
Breakpoint 1, A () at step.c:8
8 B ();
(gdb) ❺ fin
Run till exit from #0 A () at step.c:8
B
A
main () at step.c:14
14 ❻ printf ("main\n");
finish(❺ fin)すると,❻ printf ("main\n");まで実行しました.
実行再開の実行例 (continue)
$ gdb ./a.out
Reading symbols from ./a.out...
(gdb) b A
Breakpoint 1 at 0x116b: file step.c, line 8.
(gdb) r
Breakpoint 1, A () at step.c:8
8 B ();
(gdb) ❼ c
Continuing.
B
A
main
continue(❼ c)すると,ブレークポイントがなかったので,
最後まで実行して実行終了しました.
変数の値の表示
配列 (@)
// array2.c
#include <stdlib.h>
int main (int argc, char **argv)
{
int arr [4] = {0, 10, 20, 30};
int *p = malloc (sizeof (int) * 4);
p [0] = 40;
p [1] = 50;
p [2] = 60;
p [3] = 70;
}
$ gcc -g array2.c
(gdb) b 11
Breakpoint 1 at 0x5555555551ee: file array2.c, line 11.
(gdb) r aa bb cc dd
Starting program: /mnt/hgfs/gondow/project/linux-x86-64-programming/src/asm/a.out aa bb cc dd
Breakpoint 1, main (argc=5, argv=0x7fffffffdf78) at array2.c:11
11 }
(gdb) ❶ p arr
❷ $1 = {0, 10, 20, 30}
(gdb) ❸ p *p
❹ $2 = 40
(gdb) ❺ p *p@4
❻ $3 = {40, 50, 60, 70}
(gdb) ❼ p *argv@5
❽ $4 = {
0x7fffffffe2f7 "/mnt/hgfs/gondow/project/linux-x86-64-programming/src/asm/a.out", 0x7fffffffe337 "aa", 0x7fffffffe33a "bb", 0x7fffffffe33d "cc",
0x7fffffffe340 "dd"}
- 普通の配列は
printでそのまま表示できます. 例えば ❶p arrとすると,❷$1 = {0, 10, 20, 30}と表示されます. mallocで配列を確保した場合, 単純に ❸p *pとすると,pの型はint *なので, ❹$2 = 40しか表示されません. この場合は@を使って ❺p *p@4とすると, 4要素の配列としてうまく表示できます(❻$3 = {40, 50, 60, 70}).- 同様に
argvも ❼p *argv@5とすると,うまく表示できます(❽).
スコープの指定 ('::')
#include <stdio.h>
int x = 111;
int main ()
{
static int x = 222;
{
int x = 333;
printf ("hello\n");
}
}
$ gcc -g scope.c
$ gdb ./a.out
Reading symbols from ./a.out...
(gdb) b 8
Breakpoint 1 at 0x115c: file scope.c, line 8.
(gdb) r
Breakpoint 1, main () at scope.c:8
8 printf ("hello\n");
(gdb) p x
$1 = 333
(gdb) ❶ p 'scope.c'::x
$2 = 111
(gdb) ❷ p main::x
$3 = 222
'::'を使うと,特定のファイルや関数中の変数の値を表示できます.
- ❶
p 'scope.c'::xはscope.cのグローバル変数xの値を表示します. (ファイル名をクオート文字'で囲む必要があります). - ❷
p main::xは関数mainの静的変数xの値を表示します.
構造体 (リスト構造)
// list.c
#include <stdio.h>
struct list {
int data;
struct list *next;
};
int main ()
{
struct list n1 = {10, NULL};
struct list n2 = {20, &n1};
struct list n3 = {30, &n2};
struct list *p = &n3;
}
$ gdb ./a.out
Reading symbols from ./a.out...
(gdb) b 14
Breakpoint 1 at 0x119e: file list.c, line 14.
(gdb) r
Breakpoint 1, main () at list.c:14
14 }
(gdb) p p
$1 = (struct list *) 0x7fffffffde70
(gdb) ❶ p *p
❷ $2 = {data = 30, next = 0x7fffffffde60}
(gdb) ❸ p *p->next
$3 = {data = 20, next = 0x7fffffffde50}
(gdb) ❹ p *p->next->next
$4 = {data = 10, next = 0x0}

pが指すリスト構造は上図のようになっています.printを使って(❶p *p), 構造体の中身を普通に表示できます(❷{data = 30, next = 0x7fffffffde60}).*p->nextなどのC言語の式と(ほぼ)同じ記法で, リスト構造をたどって中身を表示できます (❸p *p->next,❹p *p->next->next).
共用体
// union.c
#include <stdio.h>
union foo {
int u1;
float u2;
};
int main ()
{
union foo f;
f.u1 = 999;
f.u2 = 123.456;
}
(gdb) b 13
Breakpoint 3 at 0x555555555138: file union.c, line 13.
(gdb) r
Breakpoint 3, main () at union.c:13
13 f.u2 = 123.456;
(gdb) ❶ p f
❷ $1 = {u1 = 999, u2 = 1.39989717e-42}
(gdb) ❸ p f.u1
❹ $2 = 999
(gdb) s
14 }
(gdb) p f
$3 = {u1 = 1123477881, u2 = 123.456001}
(gdb) p f.u2
$4 = 123.456001
- 共用体を
printすると (❶p f),u1とu2のどちらのメンバが使われているかgdbは分からないので, 両方の可能性を表示します (❷{u1 = 999, u2 = 1.39989717e-42}). - メンバ名を
u1と指定すると (❸p f.u1), そのメンバに対する値を表示します (❹$2 = 999).
特定の値をメモリ中から探す (find)
// find.c
#include <stdio.h>
int arr [1000];
int main ()
{
arr [500] = 0xDEADBEEF;
printf ("%p\n", &arr [500]);
}
(gdb) b 8
Breakpoint 1 at 0x115b: file find.c, line 8.
(gdb) r
Breakpoint 1, main () at find.c:8
8 printf ("%p\n", &arr [500]);
(gdb) ❶ p/x &arr[500]
❷ $1 = 0x555555558810
(gdb) ❸ find /w &arr[0], &arr[1000-1], 0xDEADBEEF
❹ 0x555555558810 <arr+2000>
1 pattern found.
- 上のプログラムでは
arr[500]に0xDEADBEEFという値が入っています. この値が格納されている場所のアドレスはprintで(❶p/x &arr[500]), ❷0x555555558810番地と分かります. - ここで仮に,配列のどこに
0xDEADBEEFが入っているか分からず, この配列に入っているか調べたいとします.findコマンドで調べられます. ❸find /w &arr[0], &arr[1000-1], 0xDEADBEEFは, 指定したアドレス範囲 (&arr[0]番地から&arr[1000-1]番地まで), 4バイト (/w)の値0xDEADBEEFを探せ,という意味になります. アドレスの範囲は,最後に指定したアドレスを含む(inclusive)ことに注意です. 正しく結果が表示されました (❹0x555555558810 <arr+2000>).
変数,レジスタ,メモリに値をセット (set)
setを使うと,変数,レジスタ,メモリに値をセットできます.
// calcx.c
int main ()
{
int x = 10;
x += 3;
x += 4;
return x;
}
$ gcc -g calcx.c
$ gdb ./a.out
(gdb) b main
Breakpoint 1 at 0x1131: file calcx.c, line 4.
(gdb) r
Breakpoint 1, main () at calcx.c:4
4 int x = 10;
(gdb) s
5 x += 3;
(gdb) ❶ set x = 20
(gdb) p x
$1 = 20
(gdb) ❷ p x = 30
$2 = 30
(gdb) p x
$3 = 30
(gdb) ❸ p/x &x
$4 = 0x7fffffffde8c
(gdb) ❹ set {int}0x7fffffffde8c = 40
(gdb) p x
❺ $5 = 40
(gdb) p/x $rax
$6 = 0x555555555129
(gdb) ❻ set $rax = 0xDEADBEEF
(gdb) p/x $rax
$7 = 0xdeadbeef
- ❶
set x = 20で,変数xに20を代入しています. - ❸
p/x &xで変数xのアドレスを調べて, そのアドレスに代入してみます(❹set {int}0x7fffffffde8c = 40). 変数xの値が40に変わりました (❺$5 = 40). - ❺
set $rax = 0xDEADBEEFで,レジスタ%raxの値を変更しました. - なお,変数,メモリ,レジスタのどの場合でも,
printコマンドを使っても代入できます (❷p x = 30).
gdb の主なコマンドの一覧
起動・終了
| コマンド | 省略名 | 説明 |
|---|---|---|
gdb ./a.out | gdbの起動 | |
run | r | 実行開始 |
quit | q | gdbの終了 |
ctrl-c | 実行中のプログラムを一時停止 (シグナル SIGINTを使用) | |
ctrl-z | 実行中のプログラムを一時停止 (シグナル SIGTSTPを使用) | |
| ⏎ (改行) | 前と同じコマンドを再実行 |
ctrl-cでSIGINTをgdbではなく実行中のプログラムに渡すには,handle SIGINT nostop passとします.gdbのシグナル処理状態はinfo signalsで見られます.gdbのプロンプト(gdb)が出ている状態で,ctrl-zを入力すると,gdb自体の実行を一時停止します.再開するにはfgコマンドなどを使います.
ヘルプ
| コマンド | 省略名 | 説明 |
|---|---|---|
help コマンド | h | コマンドのヘルプ(説明)を表示 |
apropos [-v] 正規表現 | apr | 正規表現をヘルプに含むコマンドを表示(-vは詳細表示) |
ヒストリ(コマンド履歴)と補完(コンプリーション)など
| コマンド | 省略名 | 説明 |
|---|---|---|
ctrl-p | 1つ前のコマンドを表示 | |
ctrl-n | 1つ後のコマンドを表示 | |
show commands | 自分が入力したコマンド履歴を表示 | |
ctrl-i | コマンド等を補完 (TABキーでも同じ) 2回押すと候補一覧を表示 | |
ctrl-l | 画面をクリア・リフレッシュ |
ブレークポイント・ウォッチポイント
| コマンド | 省略名 | 説明 |
|---|---|---|
break 場所 | b | ブレークポイントの設定 |
rbreak 正規表現 | rb | 正規表現にマッチする全関数にブレークポイントの設定 |
watch 場所 | wa | ウォッチポイント(書き込み)の設定 |
rwatch 場所 | rw | ウォッチポイント(読み込み)の設定 |
awatch 場所 | aw | ウォッチポイント(読み書き)の設定 |
info break | i b | ブレークポイント・ウォッチポイント一覧表示 |
break 場所 if 条件 | b | 条件付きブレークポイントの設定 |
condition 番号 条件 | cond | ブレークポイントに条件を設定 |
commands [番号] | comm | ブレークした時に実行するコマンド列を設定(endで終了) |
delete 番号 | d | ブレークポイントの削除 |
delete | d | 全ブレークポイントの解除 |
| 場所の指定方法 | 例 |
|---|---|
| 関数名 | main |
| 行番号 | 6 |
| ファイル名:行番号 | main.c:6 |
| ファイル名:関数名 | main.c:main |
*アドレス | *0x55551290 |
ステップ実行
| コマンド | 省略名 | 説明 |
|---|---|---|
step | s | 次の行までステップ実行(関数コールに入って1行を数える) |
next | n | 次の行までステップ実行(関数コールはまたいで1行を数える) |
finish | fin | 今の関数を終了するまで実行 |
continue | c | ブレークポイントに当たるまで実行 |
until 場所 | u | 指定した場所まで実行(ループを抜けたい時に便利) |
jump 場所 | j | 指定した場所から実行を再開(%ripを書き換えて再開に相当) |
stepi | si | 次の機械語命令を1つだけ実行して停止(関数コールに入って1命令を数える) |
nexti | ni | 次の機械語命令を1つだけ実行して停止(関数コールはまたいで1命令を数える) |
式,変数,レジスタ,メモリの表示
| コマンド | 省略名 | 説明 |
|---|---|---|
print/フォーマット 式 | p | 式を実行して値を表示 |
display/フォーマット 式 | disp | 実行停止毎にprintする |
info display | i di | displayの設定一覧表示 |
undisplay 番号 | und | displayの設定解除 |
x/NFU アドレス | x | メモリの内容を表示 (examine) |
info registers | i r | 全汎用レジスタの内容を表示 |
info all-registers | i al | 全汎用レジスタの内容を表示 |
- 表示する「式」は副作用があっても良い.
代入式でも良いし,副作用のある関数呼び出しやライブラリ関数呼び出しでも良い.
(例:
p x = 999,p printf ("hello\n")). このためprintfコマンドは単なる「実行状態の表示コマンド」ではなく 「実行状態の変更」も可能 (このためにgdbは裏で結構すごいことやってる).
| 式 | 説明 |
|---|---|
$レジスタ名 | レジスタ参照 |
アドレス@要素数 | 配列「アドレス[要素数]」として処理 |
- N は表示個数(デフォルト1),Fはフォーマット,Uは単位サイズを指定する.
FとUの順番は逆でも良い.
(例:
4gxは「8バイトデータを16進数表記で4個表示」を意味する)
| フォーマット F | 説明 |
|---|---|
x | 16進数 (hexadecimal) |
z | 16進数 (上位バイトのゼロも表示) |
o | 8進数 (octal) |
d | 符号あり10進数 (decimal) |
u | 符号なし10進数 (unsigned) |
t | 2進数 (two) |
c | 文字 (char) |
s | 文字列 (string) |
i | 機械語命令 (instruction) |
a | アドレス (address) |
f | 浮動小数点数 (float) |
| 単位サイズ U | 説明 |
|---|---|
b | 1バイト (byte) |
h | 2バイト (half-word) |
w | 4バイト (word) |
g | 8バイト (giant) |
変数,レジスタ,メモリの変更
| コマンド | 省略名 | 説明 |
|---|---|---|
set 変数 = 式 | set | 変数に式の値を代入する |
- 変数には通常の変数(
x),レジスタ($rax), メモリ ({int}0x0x1200), デバッガ変数 ($foo)が指定できます.
スタック表示
| コマンド | 省略名 | 説明 |
|---|---|---|
backtrace | bt, ba | コールスタックを表示 where, info stackでも同じ |
backtrace full | bt f, ba f | コールスタックと全局所変数を表示 |
プログラム表示
| コマンド | 省略名 | 説明 |
|---|---|---|
list 場所 | l | ソースコードを表示 |
disassemble 場所 | disas | 逆アセンブル結果を表示 |
disassembleへのオプション
| オプション | 説明 |
|---|---|
/s | ソースコードも表示 (表示順は機械語命令の順番) |
/m | ソースコードも表示 (表示順はソースコードの順番) |
/r | 機械語命令の16進ダンプも表示 |
TUI (テキストユーザインタフェース)
| コマンド | 省略名 | 説明 |
|---|---|---|
layout レイアウト | la | TUIレイアウトを変更 |
| レイアウト | 説明 |
|---|---|
asm | アセンブリコードのウインドウを表示 |
regs | レジスタのウインドウを表示 |
src | ソースコードのウインドウを表示 |
split | ソースとアセンブリコードのウインドウを表示 |
next | 次のレイアウトを表示 |
prev | 前のレイアウトを表示 |
| キーバインド | 説明 |
|---|---|
ctrl-x a | TUIモードのオン・オフ |
ctrl-x 1 | ウインドウを1つにする |
ctrl-x 2 | ウインドウを2つにする |
ctrl-x o | 選択ウインドウを変更 |
ctrl-x s | シングルキーモードのオン・オフ |
ctrl-l | ウインドウをリフレッシュ(再表示) |
| シングルキーモードの キーバインド | 説明 |
|---|---|
c | continue |
d | down |
f | finish |
n | next |
o | nexti |
q | シングルキーモードの終了 |
r | run |
s | step |
i | stepi |
v | info locals |
v | where |
シンボルテーブル
| コマンド | 省略名 | 説明 |
|---|---|---|
info address シンボル | i ad | シンボルのアドレスを表示 |
info symbol アドレス | i s | そのアドレスを持つシンボルを表示 |
型の表示
| コマンド | 省略名 | 説明 |
|---|---|---|
whatis 式または型名 | wha | その式や型名の型情報を表示 |
ptype 式または型名 | pt | その式や型名の型情報を詳しく表示 |
info types 正規表現 | i types | 正規表現にマッチする型を表示 |
whatisはtypedefを1レベルだけ展開します.ptypeはtypedefを全て展開します.ptypeに/oオプションを付けると,構造体のフィールドの オフセットとサイズも表示します.
その他の使い方
どんなものがあるか,ごく簡単に説明します(詳しくは説明しません). 詳しくはGDBマニュアルを参照下さい.
初期化ファイル
| ファイル名 | 説明 |
|---|---|
~/.gdbearlyinit | gdbの初期化前に読み込まれる初期化ファイル |
~/.gdbinit | gdbの初期化後に読み込まれる初期化ファイル |
./.gdbinit | 最後に読み込まれる初期化ファイル |
- よく使う
gdbの設定,ユーザ定義コマンドや コマンドエイリアスは 初期化ファイルに記述しておくと便利です. gdbの起動メッセージを抑制するset startup-quietly onは~/.gdbearlyinitに指定する必要があります../.gdbinitは個別の設定の記述に便利です. ただしデフォルトでは許可されていないので,add-auto-load-safe-path パスやset auto-load safe-path /を~/.gdbinitに書く必要があります.
ユーザ定義コマンド
defineとendでユーザ定義コマンドを定義できます.
$ cat ~/.gdbinit
define hello
echo hello, ❶ $arg0\n
end
❷ define start
b main
r
end
define ❸ hook-print
echo size: b (1 byte), h (2 byte), w (4 byte), g (8 byte)\n
end
define ❹ hook-stop
x/i $rip
end
$ gdb ./a.out
(gdb) hello gdb
hello, gdb
(gdb) start
=> 0x555555555151 <main+8>: lea 0xeac(%rip),%rax # 0x555555556004
Breakpoint 1, main () at hello.c:5
5 printf ("hello\n");
(gdb) p main
size: b (1 byte), h (2 byte), w (4 byte), g (8 byte)
$1 = {int ()} 0x555555555149 <main>
(gdb) ❺ help user-defined
User-defined commands.
The commands in this class are those defined by the user.
Use the "define" command to define a command.
List of commands:
hello -- User-defined.
hook-print -- User-defined.
hook-stop -- User-defined.
start -- User-defined.
(gdb)
- ユーザ定義コマンドの引数は,❶
$arg0,$arg1... と参照します. - 例えば「毎回
b mainとrを2回打つのは面倒だ」 という場合はユーザ定義コマンド❷startを定義すると便利かも知れません. (ここでは使っていませんが)if,while,setを組み合わせて スクリプト的なユーザ定義コマンドも定義可能です. hook-で始まるコマンド名は特別な意味を持ちます. 例えば,❸hook-printはprintを実行するたびに実行されるユーザ定義コマンドになります.(ここでは試しにサイズ指定bhwgの意味を表示しています).hook-stopはプログラムが一時停止するたびに実行されるユーザ定義コマンドです.help user-definedで,ユーザ定義コマンドの一覧を表示できます.
コマンドエイリアス
$ cat ~/.gdbinit
❶ alias di = disassemble
$ gdb ./a.out
(gdb) b main
Breakpoint 1 at 0x1151: file hello.c, line 5.
(gdb) r
Breakpoint 1, main () at hello.c:5
5 printf ("hello\n");
(gdb) ❷ di
Dump of assembler code for function main:
0x0000555555555149 <+0>: endbr64
0x000055555555514d <+4>: push %rbp
0x000055555555514e <+5>: mov %rsp,%rbp
=> 0x0000555555555151 <+8>: lea 0xeac(%rip),%rax # 0x555555556004
0x0000555555555158 <+15>: mov %rax,%rdi
0x000055555555515b <+18>: call 0x555555555050 <puts@plt>
0x0000555555555160 <+23>: mov $0x0,%eax
0x0000555555555165 <+28>: pop %rbp
0x0000555555555166 <+29>: ret
End of assembler dump.
(gdb) ❸ help di
disassemble, di
Disassemble a specified section of memory.
Usage: disassemble[/m|/r|/s] START [, END]
(以下略)
(gdb) ❹ help aliases
User-defined aliases of other commands.
List of commands:
di -- Disassemble a specified section of memory.
aliasコマンドでコマンドの別名を定義できます. ここではalias di = disassembleとして,❷diで逆アセンブルができるようにしました.- 素晴らしいことに,❸
helpがユーザ定義のエイリアスに対応していて,help diでヘルプを表示できます. - また,❹
help aliasesでエイリアスの一覧を表示できます. (-aオプションで定義したエイリアスは,補完の対象にならず, エイリアス一覧にも表示されません).
プロセスのアタッチとデタッチ (attach, detach)
gdb -pオプションやattachを使うと,すでに実行中のプログラムを
gdbの支配下に置けます(これをプロセスにアタッチするといいます).
// inf-loop.c
#include <stdio.h>
int main ()
{
int x = 1, n = 0;
while (x != 0) {
n++;
}
printf ("hello, world\n");
}
$ ❶ sudo sysctl -w kernel.yama.ptrace_scope=0
$ gcc -g inf-loop.c
$ ./a.out
❷^Z
[1]+ Stopped ./a.out
$ ❸ bg
[1]+ ./a.out &
$ ps | egrep a.out
❹ 27373 pts/0 00:00:10 a.out
$ ❺ gdb -p 27373
Attaching to process 27373
main () at inf-loop.c:6
6 while (x != 0) {
(gdb) bt
#0 main () at inf-loop.c:6
(gdb) ❻ kill
Kill the program being debugged? (y or n) y
[Inferior 1 (process 27373) killed]
(gdb) q
- まず ❶
sudo sysctl -w kernel.yama.ptrace_scope=0として, プロセスへのアタッチを許可します.デフォルトでは以下のメッセージが出て アタッチができません.❶の操作はLinuxを再起動するまで有効です.
$ gdb -p 27373
Attaching to process 27373
Could not attach to process. If your uid matches the uid of the target
process, check the setting of /proc/sys/kernel/yama/ptrace_scope, or try
again as the root user. For more details, see /etc/sysctl.d/10-ptrace.conf
ptrace: Operation not permitted.
- ここでは無限ループする
inf-loop.cをコンパイルして実行します. ❷ctrl-zで実行をサスペンド(一時中断)して,❸bgで バックグラウンド実行にします. (別の端末からgdbを起動するなら,❷❸の作業は不要です) psコマンドでa.outのプロセス番号を調べると❹27373と分かりました. ❺gdb -p 27373とすると,プロセス番号27373のプロセスをgdbが支配下に置きます(これをプロセスにアタッチすると言います).- ここでは単に
killコマンドでa.outを終了させました. 終了させたくない場合は,調査後にdetachするかgdbを終了すれば,a.outはそのまま実行を継続できます. gdb起動後に,attachコマンドを使ってもアタッチできます.
コアファイルによる事後デバッグ
コアファイルとは
コアファイル(core file)あるいはコアダンプ(core dump)とは, 実行中のプロセスのメモリやレジスタの値を記録したファイルのことです. 再現性がないバグに対してコアファイルがあると, 後から何度でもそのコアファイルを使ってデバッグできるので便利です.
コアファイルのコアはメモリを意味する
コアファイルのコア (core)はメモリを意味します. これはかつて(大昔)のメモリが磁気コアだったことに由来します.
コアファイルを生成する設定
セキュリティ等の理由で,デフォルトの設定ではコアファイルが生成されません. 以下でコアファイルを生成する設定にできます.
$ ❶ ulimit -c unlimited
$ ❷ sudo sysctl -w kernel.core_pattern=core
❶でコアファイルのサイズを無制限に設定します.
❷で,コアファイル名のパターンをcoreにします
(生成されるファイル名は core.<pid> となります.<pid>はそのプロセスのプロセス番号です).
❶の設定はそのシェル内のみ,❷の設定はLinuxを再起動するまで有効です.
コアファイルで事後解析してみる
segmentation faultでクラッシュしたプログラムの事後解析をしてみます.
$ gcc -g segv.c
$ ./a.out
❶ Segmentation fault (core dumped)
$ ls -l core*
❷ -rw------- 1 gondow gondow 307200 8月 25 10:54 core.2224
$ ❸ gdb ./a.out core.2224
Reading symbols from ./a.out...
Core was generated by `./a.out'.
Program terminated with signal SIGSEGV, Segmentation fault.
#0 0x0000559ad81bb162 in main () at segv.c:6
6 printf ("%d\n", *p);
(gdb) p p
❹ $1 = (int *) 0xdeadbeef
(gdb) bt
#0 0x0000559ad81bb162 in main () at segv.c:6
segv.cをコンパルして実行すると,segmentation fault を起こし,
コアファイルが作成されました(❷).
gdbにコアファイル名も指定して起動すると(❸),
segmentation faultが起きた状態でデバッグが可能になりました.
例えば,変数pの値を表示できています
(❹ $1 = (int *) 0xdeadbeef).
注: 著者の環境(仮想マシンVMWare Fusion 上のUbuntu 22.04LTS,ホストマシン macOS 13.4)の共有フォルダ上で上記を行った場合, 作られたコアファイルのサイズが0になってしまいました. 共有フォルダではなく
/tmpなどでは問題なくコアファイルが作られました.
動作中のプロセスのコアファイルを生成する
gcoreコマンドや,gdbのgcoreコマンドで,
動作中のプロセスのコアファイルを生成できます.
$ gcc -g inf-loop.c
$ ./a.out &
[1] 2325
$ ❶ sudo sysctl -w kernel.yama.ptrace_scope=0
kernel.yama.ptrace_scope = 0
$ ❷ gcore 2325
0x0000561775b05169 in main ()
Saved corefile core.2325
$ ❸ gdb ./a.out core.2325
Reading symbols from ./a.out...
Core was generated by `./a.out'.
#0 main () at inf-loop.c:6
6 while (x != 0) {
❶でアタッチを可能にする設定が必要です.
gcoreコマンドが対象プログラムにアタッチするからです.
gcoreコマンドでコアファイルを生成し(❷),gdbでコアファイルを指定すると(❸),
無事にデバッグ可能になりました.
$ gcc -g inf-loop.c
$ gdb ./a.out
(gdb) r
Starting program: /tmp/a.out
❶ ^C
Program received signal SIGINT, Interrupt.
main () at inf-loop.c:6
6 while (x != 0) {
(gdb) ❷ gcore
Saved corefile core.2369
gdb上でもコアファイルを生成できます.
gdb上でa.outを実行後,このプログラムは無限ループしてるので,
ctrl-c (❶)で実行を中断してから,
gcoreコマンドを使うと,コアファイルを生成できました.
キャッチポイント (catch)
キャッチポイントは様々なイベント発生時にブレークする仕組みです.
キャッチポイントが扱えるイベントには,
例外,exec,fork,vfork,
システムコール(syscall),
ライブラリのロード・アンロード(load, unload),
シグナル (signal)などがあります.
システムコールをキャッチしてみる
$ gcc -g hello.c
$ gdb ./a.out
(gdb) ❶ catch syscall write
Catchpoint 1 (syscall 'write' [1])
(gdb) r
❷ Catchpoint 1 (call to syscall write), 0x00007ffff7d14a37 in __GI___libc_write (fd=1, buf=0x5555555592a0, nbytes=6) at ../sysdeps/unix/sysv/linux/write.c:26
26 ../sysdeps/unix/sysv/linux/write.c: No such file or directory.
(gdb) ❸ bt
#0 0x00007ffff7d14a37 in __GI___libc_write (fd=1, buf=0x5555555592a0,
nbytes=6) at ../sysdeps/unix/sysv/linux/write.c:26
#1 0x00007ffff7c8af6d in _IO_new_file_write (
f=0x7ffff7e1a780 <_IO_2_1_stdout_>, data=0x5555555592a0, n=6)
at ./libio/fileops.c:1180
#2 0x00007ffff7c8ca61 in new_do_write (to_do=6,
data=0x5555555592a0 "hello\n", fp=0x7ffff7e1a780 <_IO_2_1_stdout_>)
at ./libio/libioP.h:947
#3 _IO_new_do_write (to_do=6, data=0x5555555592a0 "hello\n",
fp=0x7ffff7e1a780 <_IO_2_1_stdout_>) at ./libio/fileops.c:425
#4 _IO_new_do_write (fp=fp@entry=0x7ffff7e1a780 <_IO_2_1_stdout_>,
data=0x5555555592a0 "hello\n", to_do=6) at ./libio/fileops.c:422
#5 0x00007ffff7c8cf43 in _IO_new_file_overflow (
f=0x7ffff7e1a780 <_IO_2_1_stdout_>, ch=10) at ./libio/fileops.c:783
#6 0x00007ffff7c8102a in __GI__IO_puts (str=0x555555556004 "hello")
at ./libio/ioputs.c:41
#7 0x0000555555555160 in main () at hello.c:5
(gdb)
❶ catch syscall writeで,writeシステムコールをキャッチしてみます.
printfが最終的にはwriteシステムコールを呼ぶはずです.
やってみたら,無事にキャッチできました(❷).
バックトレースを見ると(❸),main関数からwriteが呼ばれるまでの
関数呼び出しを表示できました.
シグナルをキャッチしてみる (handle, catch signal)
handleを使う
#include <stdio.h>
#include <signal.h>
#include <unistd.h>
void handler (int n)
{
fprintf (stderr, "I am handler\n");
}
int main (void)
{
signal (SIGUSR1, handler);
while (1) {
fprintf (stderr, ".");
sleep (1);
}
}
$ gcc -g sigusr1.c
$ gdb ./a.out
Reading symbols from ./a.out...
(gdb) ❶ handle SIGUSR1
Signal Stop Print Pass to program Description
SIGUSR1 Yes Yes Yes User defined signal 1
(gdb) r
❷ ...........
❸ Program received signal SIGUSR1, User defined signal 1.
0x00007ffff7ce57fa in __GI___clock_nanosleep (clock_id=clock_id@entry=0, flags=flags@entry=0, req=req@entry=0x7fffffffde50, rem=rem@entry=0x7fffffffde50) at ../sysdeps/unix/sysv/linux/clock_nanosleep.c:78
78 ../sysdeps/unix/sysv/linux/clock_nanosleep.c: No such file or directory.
(gdb) ❹ handle SIGUSR1 nostop noprint pass
Signal Stop Print Pass to program Description
SIGUSR1 No No Yes User defined signal 1
(gdb) ❺ c
Continuing.
❻ I am handler
......I am handler
.....❼ ^C
Program received signal SIGINT, Interrupt.
0x00007ffff7ce57fa in __GI___clock_nanosleep (clock_id=clock_id@entry=0, flags=flags@entry=0, req=req@entry=0x7fffffffde50, rem=rem@entry=0x7fffffffde50) at ../sysdeps/unix/sysv/linux/clock_nanosleep.c:78
78 in ../sysdeps/unix/sysv/linux/clock_nanosleep.c
(gdb)
-
❶
handle SIGUSR1とすると,gdbがシグナルSIGUSR1を受け取った時の処理設定が表示されます.- Stop Yes:
gdbはa.outの実行を一時停止します. - Print Yes:
gdbはSIGUSR1を受け取ったことを表示します. - Pass Yes:
gdbはa.outにSIGUSR1を渡します.
- Stop Yes:
-
❷ 実行を開始すると,
a.outは1秒ごとに.を出力しながらSIGUSR1を待ちます. -
別端末から
a.outのプロセス番号を調べて(ここでは2696),kill -USR1 2696として,a.outにSIGUSR1を送信しました. その結果,a.outの実行が一時停止し(❸),gdbに制御が戻りました. -
今度は
SIGUSR1の設定を変えてやってみます ❹handle SIGUSR1 nostop noprint passは, 「SIGUSR1で一時停止しない,表示もしない,a.outにSIGUSR1を渡す」 という設定を意味します (stop,nostop,print,noprint,pass,nopassを指定可能です).gdbがSIGUSR1を受け取った時,gdbはa.outを一時停止させず,SIGUSR1をa.outに渡すはずです. -
実行を再開すると (❺
c), ❻I am handlerが表示されています. これは先程送ったSIGUSR1に対してa.outのシグナルハンドラが出力した表示です. ここでもう一度,kill -USR1 2696として,a.outにSIGUSR1を送信すると, (gdbはa.outを一時停止させること無く) 再度I am handlerが表示されました.期待した通りの動作です. -
ctrl-C(❼^C)を押して,a.outの動作を一時停止しました.
catch signalを使う
$ gcc -g sigusr1.c
$ gdb ./a.out
Reading symbols from ./a.out...
(gdb) ❶ catch signal SIGUSR1
Catchpoint 1 (signal SIGUSR1)
(gdb) r
..........
❷ Catchpoint 1 (signal SIGUSR1), 0x00007ffff7ce57fa in __GI___clock_nanosleep (clock_id=clock_id@entry=0, flags=flags@entry=0, req=req@entry=0x7fffffffde50, rem=rem@entry=0x7fffffffde50) at ../sysdeps/unix/sysv/linux/clock_nanosleep.c:78
78 ../sysdeps/unix/sysv/linux/clock_nanosleep.c: No such file or directory.
(gdb)
- ❶
catch signal SIGUSR1で,SIGUSR1をキャッチする設定をします. - 別端末から
kill -USR1 2696として,a.outにSIGUSR1を送信すると, 期待通り,SIGUSR1をキャッチしてa.outの実行が一時停止されました (❷Catchpoint 1 (signal SIGUSR1)). handleもcatchもシグナルをキャッチできるのですが,catchがhandleより嬉しいのは,catchを使うと 停止する条件や 停止時に実行する コマンドを設定できることです.- なお
catchを設定すると,handleのnostop設定は無視されます.
GDBのPythonプラグイン
PythonでGDBのユーザ定義コマンドを定義できます.
# gdb-script.py
class python_test (❶ gdb.Command):
"""Python Script Test"""
def __init__ (self):
super (python_test, self).__init__ (
"python_test", gdb.COMMAND_USER
)
def invoke (self, args, from_tty):
val = ❷ gdb.parse_and_eval (args)
print ("args = " + args)
print ("val = " + str (val))
❸ gdb.execute ("p/x" + str (val) + "\n");
python_test ()
- 例えば上の
gdb-script.pyはpython_testというユーザ定義コマンドを定義します.~/.gdbinitなどでこのファイルをsource gdb-script.pyとして読み込む必要があります. - 定義するコマンドは❶
gdb.Commandのサブクラスとして定義します. ❷gdb.parse_and_evalを使えば与えられた引数をgdbの下で評価できます. ❸gdb.executeを使えば,gdbのコマンドとして実行できます.
$ gdb ./a.out
(gdb) b main
Breakpoint 1 at 0x1180: file fact.c, line 13.
(gdb) r
Breakpoint 1, main () at fact.c:13
13 printf ("%d\n", fact (5));
(gdb) ❹ python_test $rsp
args = $rsp
val = 0x7fffffffde60
$1 = 0x7fffffffde60
(gdb) help user-defined
User-defined commands.
The commands in this class are those defined by the user.
Use the "define" command to define a command.
List of commands:
❺ python_test -- Python Script Test
(gdb)
gdb上で定義したpython_testというコマンドを実行すると(❹) 意図通り実行できました(%rspの値が評価されて0x7fffffffde60になっています).help user-definedすると,ちゃんと登録されていました(❺).
GDB/MI machine interface
gdbのMI(マシンインタフェース)とは
gdbとのやり取りをプログラムで処理しやすくするためのモードです.
$ gdb --interpreter=mi ./a.out
=thread-group-added,id="i1"
=cmd-param-changed,param="auto-load safe-path",value="/"
~"Reading symbols from ./a.out...\n"
(gdb)
❶ b main
❷ &"b main\n"
❸ ~"Breakpoint 1 at 0x1180: file fact.c, line 13.\n"
❹ =breakpoint-created,bkpt={number="1",type="breakpoint",disp="keep",enabled="y",addr="0x0000000000001180",func="main",file="fact.c",fullname="/mnt/hgfs/gondow/project/linux-x86-64-programming/src/asm/fact.c",line="13",thread-groups=["i1"],times="0",original-location="main"}
^done
(gdb)
r
&"r\n"
~"Starting program: /mnt/hgfs/gondow/project/linux-x86-64-programming/src/asm/a.out \n"
=thread-group-started,id="i1",pid="5171"
=thread-created,id="1",group-id="i1"
=breakpoint-modified,bkpt={number="1",type="breakpoint",disp="keep",enabled="y",addr="0x0000555555555180",func="main",file="fact.c",fullname="/mnt/hgfs/gondow/project/linux-x86-64-programming/src/asm/fact.c",line="13",thread-groups=["i1"],times="0",original-location="main"}
=library-loaded,id="/lib64/ld-linux-x86-64.so.2",target-name="/lib64/ld-linux-x86-64.so.2",host-name="/lib64/ld-linux-x86-64.so.2",symbols-loaded="0",thread-group="i1",ranges=[{from="0x00007ffff7fc5090",to="0x00007ffff7fee335"}]
^running
*running,thread-id="all"
(gdb)
=library-loaded,id="/lib/x86_64-linux-gnu/libc.so.6",target-name="/lib/x86_64-linux-gnu/libc.so.6",host-name="/lib/x86_64-linux-gnu/libc.so.6",symbols-loaded="0",thread-group="i1",ranges=[{from="0x00007ffff7c28700",to="0x00007ffff7dbaabd"}]
~"[Thread debugging using libthread_db enabled]\n"
~"Using host libthread_db library \"/lib/x86_64-linux-gnu/libthread_db.so.1\".\n"
=breakpoint-modified,bkpt={number="1",type="breakpoint",disp="keep",enabled="y",addr="0x0000555555555180",func="main",file="fact.c",fullname="/mnt/hgfs/gondow/project/linux-x86-64-programming/src/asm/fact.c",line="13",thread-groups=["i1"],times="1",original-location="main"}
~"\n"
~"Breakpoint 1, main () at fact.c:13\n"
~"13\t printf (\"%d\\n\", fact (5));\n"
*stopped,reason="breakpoint-hit",disp="keep",bkptno="1",frame={addr="0x0000555555555180",func="main",args=[],file="fact.c",fullname="/mnt/hgfs/gondow/project/linux-x86-64-programming/src/asm/fact.c",line="13",arch="i386:x86-64"},thread-id="1",stopped-threads="all",core="1"
(gdb)
quit
&"quit\n"
=thread-exited,id="1",group-id="i1"
gdbのMIは「CSVのようなもの」です.- ❶
b mainとブレークポイントの設定をすると, ❷&"b main\n"と入力したコマンドが返り, その結果 ❸~"Breakpoint 1 at 0x1180: file fact.c, line 13.\n"と 付属情報が表示されます ❹=breakpoint-created,bkpt={number="1",type="breakpoint",disp="keep",enabled="y",addr="0x0000000000001180",func="main",file="fact.c",fullname="/mnt/hgfs/gondow/project/linux-x86-64-programming/src/asm/fact.c",line="13",thread-groups=["i1"],times="0",original-location="main"}各行は1行で,カンマ,などの区切り子(デリミタ)で区切られており, プログラムで処理しやすい出力になっています. - JSONで出力してくればいいのにと思ったり.
gdbのMI出力をJSONに変換するツールpygdbmi はあるようです(試していません).
遠隔デバッグ (gdbserver, target remote)
gdbは遠隔デバッグが可能です.
遠隔デバッグとは,デバッグ対象のプログラムが動作しているマシンとは
異なるマシン上でデバッグすることです.
リソースが貧弱な組み込みシステムなどで,遠隔デバッグは有用です.
ここでは(簡単のため)ローカルホスト,つまり同じマシン上で遠隔デバッグをしてみます
まず予め gdbserverをインストールしておく必要があります.
$ sudo apt install gdbserver
gdbserverを使ってデバッグしたいプログラムa.outを起動します.
$ gdbserver :1234 ./a.out
Process ./a.out created; pid = 5195
Listening on port 1234
:1234は遠隔デバッグに使用するポート番号です.
$ ❶ gdb ./a.out
Reading symbols from ./a.out...
(gdb) ❷ target remote localhost:1234
Remote debugging using localhost:1234
Reading /lib64/ld-linux-x86-64.so.2 from remote target...
(gdb) ❸ c
Continuing.
Reading /lib/x86_64-linux-gnu/libc.so.6 from remote target...
[Inferior 1 (process 5195) exited normally]
(gdb)
gdbを起動して(❶),デバッグ対象を 遠隔で対象はlocalhost:1234と指定します(❷). (localhostを省略して:1234だけ指定してもOKです).- デバッグ対象のプログラムはすでに実行を開始しているので,
❸
cで実行を再開します.その後は通常のgdbと同様の操作が可能です.
トレースポイント (trace, actions, collect, tstart, tstop, tfind, tdump, tstatus)
通常,gdbを使う時はブレークポイントを使ってプログラムを一時的に停止させて,
対話的にデバッグ作業を行います.
一方,トレースポイントを使うとプログラムを一時停止させずに,
プログラムの動作を観察できます.
手順は以下の通りです.
- 遠隔デバッグでプログラムを
gdbの監視下に置きます. (現在,トレースポイントは遠隔デバッグでのみ有効です). traceとcollectを使って,観察したい場所とデータを事前に設定します.tstartとtstopを使って,プログラムのデータ収集の開始と停止を指示します.- 事後に
tfind,tdump,tstatusで収集したデータを調査します.
$ gcc -g -static fact.c
$ gdbserver :1234 ./a.out
Process ./a.out created; pid = 5696
Listening on port 1234
ここでは簡単のため静的リンクでコンパイルしたa.outを使って
遠隔デバッグの準備をします.
$ gdb ./a.out
Reading symbols from ./a.out...
(gdb) target remote :1234
Remote debugging using :1234
0x0000000000401620 in _start ()
(gdb) ❶ trace fact
Tracepoint 1 at 0x401754: file fact.c, line 5.
(gdb) ❷ actions
Enter actions for tracepoint 1, one per line.
End with a line saying just "end".
>❸ collect n
>end
(gdb) b 14
Breakpoint 2 at 0x4017a1: file fact.c, line 14.
(gdb) ❹ tstart
(gdb) c
Continuing.
Breakpoint 2, main () at fact.c:14
14 }
(gdb) ❺ tstop
(gdb) ❻ tstatus
Trace stopped by a tstop command ().
Collected 6 trace frames.
Trace buffer has 5237852 bytes of 5242880 bytes free (0% full).
Trace will stop if GDB disconnects.
Not looking at any trace frame.
Trace started at 135843.311816 secs, stopped 5.701432 secs later.
(gdb) ❼ tfind start
Found trace frame 0, tracepoint 1
#0 fact (n=5, n@entry=<error reading variable: PC not available>) at fact.c:5
5 if (n <= 0)
(gdb) ❽ tdump
Data collected at tracepoint 1, trace frame 0:
n = 5
(gdb) ❾ tfind
Found trace frame 1, tracepoint 1
#0 fact (n=4, n@entry=<error reading variable: PC not available>) at fact.c:5
5 if (n <= 0)
(gdb) tfind
Found trace frame 2, tracepoint 1
#0 fact (n=3, n@entry=<error reading variable: PC not available>) at fact.c:5
5 if (n <= 0)
(gdb) tfind
Found trace frame 3, tracepoint 1
#0 fact (n=2, n@entry=<error reading variable: PC not available>) at fact.c:5
5 if (n <= 0)
(gdb) tfind
Found trace frame 4, tracepoint 1
#0 fact (n=1, n@entry=<error reading variable: PC not available>) at fact.c:5
5 if (n <= 0)
(gdb) tfind
Found trace frame 5, tracepoint 1
#0 fact (n=0, n@entry=<error reading variable: PC not available>) at fact.c:5
5 if (n <= 0)
(gdb) quit
-
事前準備をします. 関数
factにトレースポイントを設定します(❶trace fact). コマンド付きブレークポイントのcomandsと同じ要領で, ❷actionsを使って,トレースポイントで収集するデータや動作を指定します. ここでは単に引数nの値を収集します (❸collect n). -
❹
tstartでデータの収集を開始します.continueでプログラムの実行を再開すると, トレースポイントにヒットした情報が集められます. ❺tstopで収集を終了します. -
事後の調査をします. ❻
tstatusで収集状況を調べると, 6回トレースポイントにヒットしてデータを収集していました (Collected 6 trace frames). ❼tfind startで最初の収集データを見ます. ❽tdumpとするとその収集データの内容を全て表示します (が,ここでは引数nの値しか表示されません). 引数無しで ❾tfindとすると,次の収集データを表示します. 引数nの値が,6から0まで変化したことが分かりました.
トレースポイントに関する付記:
traceにはifを使って ヒットする条件を指定可能です.traceはint3などのトラップ命令を使って計装(instrumentation)するので遅いです.ftraceを使うと5バイト長のジャンプ命令を使って計装するので高速になります (が,計装位置の命令長が5バイト以上必要です). (試していませんが)静的計装を行うstraceもあります.
実行の記録とリプレイ,逆実行 (record full, reverse-step)
gdbでは実行状態の記録とリプレイが可能です.
またリプレイ機能を使って逆実行も可能です.
リプレイでは実際には機械語命令の実行を行わず,
実行ログの内容を使って,メモリやレジスタの値を変化させます.
$ gcc -g fact.s
$ gdb ./a.out
Reading symbols from ./a.out...
(gdb) b main
Breakpoint 1 at 0x40177c: file fact.c, line 13.
(gdb) r
Breakpoint 1, main () at fact.c:13
13 printf ("%d\n", fact (5));
(gdb) ❶ record full
(gdb) b fact if n==0
Breakpoint 2 at 0x401754: file fact.c, line 5.
(gdb) c
Continuing.
Breakpoint 2, fact (n=0) at fact.c:5
5 if (n <= 0)
(gdb) reverse-TABTAB
reverse-continue reverse-next reverse-search reverse-stepi
reverse-finish reverse-nexti reverse-step
(gdb) ❷ reverse-next
8 return n * fact (n - 1);
(gdb) (改行のみ入力,以下も同様)
5 if (n <= 0)
(gdb)
8 return n * fact (n - 1);
(gdb)
5 if (n <= 0)
(gdb)
8 return n * fact (n - 1);
(gdb) ❸ print n
$1 = 3
(gdb) quit
-
❶
record fullで実行状態の記録を開始します. ソフトウェア的に全実行状態を保存します. (当然,メモリを激しく消費します). -
❷
reverse-nextなど逆実行用のステップ実行を行うと, 逆実行できます(実際には実行はせず,元の状態に戻すだけですが). ❸nの値が3の状態まで戻りました.
実行の記録とリプレの付記:
record fullではなく,record btrace ptなどとすると, ハードウェア機能(例えば,Intel PT)を使った高速な記録になりますが, リングバッファを使うため,バッファがあふれると古いデータは捨てられます.record stopとすると実行の記録を止めて実行ログは破棄されます. 実行ログはrecord save ファイル名,record restore ファイル名で 保存や回復が可能です.上の例だとファイルサイズは約700KBでした.- x86-64ではAVX命令などが非対応のようです.
例えば,AVX512の
vmovdqu命令を試すと,以下のエラーとなりました(2023/8/27現在).
main () at movdqu.s:23
23 vmovdqu (%rsp), %ymm0
(gdb)
Process record does not support instruction 0xc5 at address 0x555555555171.
Process record: failed to record execution log.
(gdb)
glibcなどのライブラリは-O2などでコンパイルされているため,
AVX命令が使われることが多くあります.
試しにhello.cで試した所,同じエラーとなりました.
(gdb) n
5 printf ("hello\n");
(gdb) n
Process record does not support instruction 0xc5 at address 0x7ffff7d9d969.
Process record: failed to record execution log.
macOS上でgdbを使うには?
2024/3/11現在,Apple Silicon Mac上ではgdbは使えないようです.
lldbを使いましょう.
x86-64 命令一覧
概要と記号
add5.cをgcc -S add5.cでコンパイルした結果
add5.s(余計なものの削除後)を用いて,
x86-64アセンブリ言語の概要と記号を説明します.

$ gcc -S add5.cを実行(コンパイル)すると,アセンブリコードadd5.sが生成されます.(結果は環境依存なので,add5.sの中身が違ってても気にしなくてOK)- ドット記号
.で始まるのはアセンブラ命令(assembler directive)です. - コロン記号
:で終わるのはラベル定義です. - シャープ記号
#から行末までと,/*と*/で囲まれた範囲(複数行可)はコメントです. movq %rsp, %rbpは機械語命令(2進数)の記号表現(ニモニック(mnemonic))です.movqが命令でオペコード(opcode),%rspと%rbpは引数でオペランド(operand)と呼ばれます.- ドル記号
$で始まるのは即値(immediate value,定数)です. - パーセント記号
%で始まるのはレジスタです. -4(%rbp)は間接メモリ参照です.この場合は「%rbp-4の計算結果」をアドレスとするメモリの内容にアクセスすることを意味します.
命令サフィックス
| AT&T形式の サイズ指定 | Intel形式の サイズ指定 | メモリオペランドの サイズ | AT&T形式での例 | Intel形式での例 |
|---|---|---|---|---|
b | BYTE PTR | 1バイト(8ビット) | movb $10, -8(%rbp) | mov BYTE PTR [rbp-8], 10 |
w | WORD PTR | 2バイト(16ビット) | movw $10, -8(%rbp) | mov WORD PTR [rbp-8], 10 |
l | DWORD PTR | 4バイト(32ビット) | movl $10, -8(%rbp) | mov DWORD PTR [rbp-8], 10 |
q | QWORD PTR | 8バイト(64ビット) | movq $10, -8(%rbp) | mov QWORD PTR [rbp-8], 10 |
- 間接メモリ参照ではサイズ指定が必要です (「何バイト読み書きするのか」が決まらないから)
- AT&T形式では命令サフィックス(instruction suffix)でサイズを指定します.
例えば
movq $10, -8(%rbp)のqは, 「メモリ参照-8(%rbp)への書き込みサイズが8バイト」であることを意味します.
サフィックスとプリフィックス
サフィックス(suffix)は接尾語(後ろに付けるもの), プリフィックス(prefix)は接頭語(前に付けるもの)という意味です.
- Intel形式ではメモリ参照の前に,
BYTE PTRなどと指定します. - 他のオペランドからサイズが決まる場合は命令サフィックスを省略可能です.
例えば,
movq %rax, -8(%rsp)はmov %rax, -8(%rsp)にできます.mov命令の2つのオペランドはサイズが同じで%raxレジスタのサイズが8バイトだからです.
即値(定数)
| 種類 | 説明 | 例 |
|---|---|---|
| 10進数定数 | 0で始まらない | pushq $74 |
| 16進数定数 | 0xか0Xで始まる | pushq $0x4A |
| 8進数定数 | 0で始まる | pushq $0112 |
| 2進数定数 | 0bか0Bで始まる | pushq $0b01001010 |
| 文字定数 | '(クオート)で始まる | pushq $'J |
'(クオート)で囲む | pushq $'J' | |
\バックスラッシュでエスケープ可 | pushq $'\n |
- 即値(immediate value,定数)には
$をつけます - 上の例の定数は最後以外は全部,値が同じです
- GNUアセンブラでは文字定数の値はASCIIコードです.
上の例では,文字
'J'の値は74です. - バックスラッシュでエスケープできる文字は,
\b,\f,\n,\r,\t,\",\\です. また\123は8進数,\x4Fは16進数で指定した文字コードになります. - 多くの場合,即値は32ビットまでで, オペランドのサイズが64ビットの場合, 32ビットの即値は,64ビットの演算前に 64ビットに符号拡張 されます (ゼロ拡張だと 負の値が大きな正の値になって困るから)
64ビットに符号拡張される例(1)
# asm/add-imm2.s
.text
.globl main
.type main, @function
main:
movq $0, %rax
addq $-1, %rax
ret
.size main, .-main
上のaddq $-1, %rax命令の即値$-1は
32ビット(以下の場合もあります)の符号あり整数$0xFFFFFFFFとして
機械語命令に埋め込まれます.
addq命令が実行される時は,
この$0xFFFFFFFFが64ビットに符号拡張されて$0xFFFFFFFFFFFFFFFFとなります.
以下の実行例でもこれが確認できました.
0 + 0xFFFFFFFFFFFFFFFF = 0xFFFFFFFFFFFFFFFF
$ gcc -g add-imm2.s
$ gdb ./a.out -x add-imm2.txt
Breakpoint 1, main () at add-imm2.s:8
8 ret
7 addq $-1, %rax
$1 = 0xffffffffffffffff
# 0xffffffffffffffff が表示されていれば成功
64ビットに符号拡張される例(2)
32ビットの即値が,64ビットの演算前に64ビットに符号拡張されることを見てみます.
32ビット符号あり整数が表現できる範囲は-0x80000000から0x7FFFFFFFです.
# asm/add-imm.s
.text
.globl main
.type main, @function
main:
movq $0, %rax
addl $0xFFFFFFFF, %eax # OK (0xFFFFFFFF = -1)
# addq $0xFFFFFFFF, %rax # NG (0x7FFFFFFFを超えている)
addq $0xFFFFFFFFFFFFFFFF, %rax # OK (0xFFFFFFFFFFFFFFFF = -1)
addq $0x7FFFFFFF, %rax # OK
addq $-0x80000000, %rax # OK
addq $0xFFFFFFFF80000000, %rax # OK (0xFFFFFFFF80000000 = -0x80000000)
ret
.size main, .-main
-
7行目の
$0xFFFFFFFFは32ビット符号あり整数として-1, つまり32ビット符号あり整数が表現できる範囲内なのでOKです. -
一方,8行目の
$0xFFFFFFFFは 64ビット符号あり整数として$0x7FFFFFFFを超えてるのでNGです. (アセンブルするとエラーになります) -
9行目の
$0xFFFFFFFFFFFFFFFFは一見NGですが, 64ビット符号あり整数としての値は-1なので, GNUアセンブラはこの即値を-1として機械語命令に埋め込みます. -
いちばん大事なのは最後の2つの
addq命令です.addq $-0x80000000, %raxの 即値$-0x80000000は(機械語命令中では32ビットで埋め込まれますが) 足し算を実行する前に64ビットに符号拡張されるので,$0xFFFFFFFF80000000という値で足し算されます. (つまり,$0x80000000を引きます). 以下の実行例を見ると,その通りの実行結果になっています.❶ 0x17ffffffd - $0x80000000 = ❷ 0xfffffffd❷ 0xfffffffd - $0x80000000 = ❸ 0x7ffffffd
一方,もし
$-0x80000000を(符号拡張ではなく) ゼロ拡張 すると,$0x0000000080000000となるので,$0x80000000を(引くのではなく)足すことになってしまいます.
$ gcc -g add-imm.s
$ gdb ./a.out -x add-imm.txt
Breakpoint 1, main () at add-imm.s:7
7 addl $0xFFFFFFFF, %eax # OK (0xFFFFFFFF = -0x1)
9 addq $0xFFFFFFFFFFFFFFFF, %rax # OK (0xFFFFFFFFFFFFFFFF = -0x1)
1: /x $rax = 0xffffffff
10 addq $0x7FFFFFFF, %rax # OK
1: /x $rax = 0xfffffffe
11 addq $-0x80000000, %rax # OK
1: /x $rax = ❶ 0x17ffffffd
12 addq $0xFFFFFFFF80000000, %rax # OK (0xFFFFFFFF80000000 = -0x80000000)
1: /x $rax = ❷ 0xfffffffd
main () at add-imm.s:13
13 ret
1: /x $rax = ❸ 0x7ffffffd
#以下が表示されていれば成功
#1: /x $rax = 0xffffffff
#1: /x $rax = 0xfffffffe
#1: /x $rax = 0x17ffffffd
#1: /x $rax = 0xfffffffd
#1: /x $rax = 0x7ffffffd
以下の通り,逆アセンブルすると, 32ビット以下の即値として機械語命令中に埋め込まれていることが分かります.
$ gcc -g add-imm.s
$ objdump -d ./a.out
0000000000001129 <main>:
1129: 48 c7 c0 00 00 00 00 mov $0x0,%rax
1130: 83 c0 ff add $0xffffffff,%eax
1133: 48 83 c0 ff add $0xffffffffffffffff,%rax
1137: 48 05 ff ff ff 7f add $0x7fffffff,%rax
113d: 48 05 00 00 00 80 add $0xffffffff80000000,%rax
1143: 48 05 00 00 00 80 add $0xffffffff80000000,%rax
1149: c3 ret
mov命令は例外で64ビットの即値を扱えます
64ビットの即値を扱う例
# asm/movqabs-1.s
.text
.globl main
.type main, @function
main:
movq $0x1122334455667788, %rax
movabsq $0x99AABBCCDDEEFF00, %rax
ret
.size main, .-main
$ gcc -g movqabs-1.s
$ gdb ./a.out -x movqabs-1.txt
Breakpoint 1, main () at movqabs-1.s:6
6 movq $0x1122334455667788, %rax
7 movabsq $0x99AABBCCDDEEFF00, %rax
1: /x $rax = 0x1122334455667788
main () at movqabs-1.s:8
8 ret
1: /x $rax = 0x99aabbccddeeff00
# 以下が表示されれば成功
# 1: /x $rax = 0x1122334455667788
# 1: /x $rax = 0x99aabbccddeeff00
- ジャンプでは64ビットの相対ジャンプができないので, 間接ジャンプを使う必要がある
64ビットの相対ジャンプの代わりに間接ジャンプを使う例
# asm/jmp-64bit.s
.text
.globl main
.type main, @function
main:
# jmp 0x1122334455667788 # NG
movq $0x1122334455667788, %rax
jmp *%rax
ret
.size main, .-main
0x1122334455667788はいい加減なアドレスなので,
コンパイルは可能ですが,実行すると segmentation fault になります.
レジスタ
汎用レジスタ
- 上記16個のレジスタが汎用レジスタ(general-purpose register)です. 原則として,プログラマが自由に使えます.
- ただし,
%rspはスタックポインタ,%rbpはベースポインタと呼び, 一番上のスタックフレームの上下を指す という役割があります. (ただし,-fomit-frame-pointer オプションでコンパイルされたa.out中では,%rbpはベースポインタとしてではなく, 汎用レジスタとして使われています).
caller-saved/callee-savedレジスタ
| 汎用レジスタ | |
|---|---|
| caller-savedレジスタ | %rax, %rcx, %rdx, %rsi, %rdi, %r8〜%r11 |
| callee-savedレジスタ | %rbx, %rbp, %rsp, %r12〜%r15 |
引数
| 引数 | レジスタ |
|---|---|
| 第1引数 | %rdi |
| 第2引数 | %rsi |
| 第3引数 | %rdx |
| 第4引数 | %rcx |
| 第5引数 | %r8 |
| 第6引数 | %r9 |
- 第7引数以降はレジスタではなくスタックを介して渡します
プログラムカウンタ(命令ポインタ)
ステータスレジスタ(フラグレジスタ)
本書で扱うフラグ
ステータスレジスタのうち,本書は以下の6つのフラグを扱います.
| フラグ | 名前 | 説明 |
|---|---|---|
CF | キャリーフラグ | 算術演算で結果の最上位ビットにキャリーかボローが生じるとセット.それ以外はクリア.符号なし整数演算でのオーバーフロー状態を表す. |
OF | オーバーフローフラグ | 符号ビット(MSB)を除いて,整数の演算結果が大きすぎるか小さすぎるかするとセット.それ以外はクリア.2の補数表現での符号あり整数演算のオーバーフロー状態を表す. |
ZF | ゼロフラグ | 結果がゼロの時にセット.それ以外はクリア. |
SF | 符号フラグ | 符号あり整数の符号ビット(MSB)と同じ値をセット.(0は正の数,1は負の数であることを表す) |
PF | パリティフラグ | 結果の最下位バイトの値1のビットが偶数個あればセット,奇数個であればクリア. |
AF | 調整フラグ | 算術演算で,結果のビット3にキャリーかボローが生じるとセット.それ以外はクリア.BCD演算で使用する(本書ではほとんど使いません). |
ステータスフラグの変化の記法
x86-64命令を実行すると,ステータスフラグが変化する命令と 変化しない命令があります. ステータスフラグの変化は以下の記法で表します.
記法の意味は以下の通りです.
| 記法 | 意味 |
|---|---|
| 空白 | フラグ値に変化なし |
| ! | フラグ値に変化あり |
| ? | フラグ値は未定義(参照禁止) |
| 0 | フラグ値はクリア(0になる) |
| 1 | フラグ値はセット(1になる) |
レジスタの別名
%raxレジスタの別名 (%rbx, %rcx, %rdxも同様)
%raxの下位32ビットは%eaxとしてアクセス可能%eaxの下位16ビットは%axとしてアクセス可能%axの上位8ビットは%ahとしてアクセス可能%axの下位8ビットは%alとしてアクセス可能
%rbpレジスタの別名 (%rsp, %rdi, %rsiも同様)
%rbpの下位32ビットは%ebpとしてアクセス可能%ebpの下位16ビットは%bpとしてアクセス可能%bpの下位8ビットは%bplとしてアクセス可能
%r8レジスタの別名 (%r9〜%r15も同様)
%r8の下位32ビットは%r8dとしてアクセス可能%r8dの下位16ビットは%r8wとしてアクセス可能%r8wの下位8ビットは%r8bとしてアクセス可能
同時に使えない制限
- 一部のレジスタは
%ah,%bh,%ch,%dhと一緒には使えない. - 例:
movb %ah, (%r8)やmovb %ah, %bplはエラーになる. - 正確には
REXプリフィクス付きの命令では,%ah,%bh,%ch,%dhを使えない.
32ビットレジスタ上の演算は64ビットレジスタの上位32ビットをゼロにする
- 例:
movl $0xAABBCCDD, %eaxを実行すると%raxの上位32ビットが全てゼロになる - 例:
movw $0x1122, %axやmovb $0x11, %alでは上位をゼロにすることはない
上位32ビットをゼロにする実行例
# asm/zero-upper32.s
.text
.globl main
.type main, @function
main:
movq $0x1122334455667788, %rax
movl $0xAABBCCDD, %eax
movq $0x1122334455667788, %rax
movw $0x1122, %ax
movq $0x1122334455667788, %rax
movb $0x11, %al
ret
.size main, .-main
$ gcc -g zero-upper32.s
$ gdb ./a.out -x zero-upper32.txt
Breakpoint 1, main () at zero-upper32.s:7
7 movl $0xAABBCCDD, %eax
6 movq $0x1122334455667788, %rax
7 movl $0xAABBCCDD, %eax
$1 = 0x1122334455667788
8 movq $0x1122334455667788, %rax
$2 = 0x00000000aabbccdd
# 以下が出力されれば成功
# $1 = 0x1122334455667788 (%raxは8バイトの値を保持)
# $2 = 0x00000000aabbccdd (%raxの上位4バイトがゼロになった)
アドレッシングモード(オペランドの記法)
アドレッシングモードの種類
| アドレッシング モードの種類 | オペランドの値 | 例 | 計算するアドレス |
|---|---|---|---|
| 定数の値 | movq $0x100, %rax | ||
movq $foo, %rax | |||
| レジスタの値 | movq %rbx, %rax | ||
| 定数で指定した アドレスのメモリ値 | movq 0x100, %rax | 0x100 | |
movq foo, %rax | foo | ||
| レジスタ等で計算した アドレスのメモリ値 | movq (%rsp), %rax | %rsp | |
movq 8(%rsp), %rax | %rsp+8 | ||
movq foo(%rip), %rax | %rip+foo |
fooはラベルであり,定数と同じ扱い.(定数を書ける場所にはラベルも書ける).- メモリ参照では例えば
-8(%rbp, %rax, 8)など複雑なオペランドも指定可能. 参照するメモリのアドレスは-8+%rbp+%rax*8になる. (以下を参照).
メモリ参照の形式
| AT&T形式 | Intel形式 | 計算されるアドレス | |
|---|---|---|---|
| 通常のメモリ参照 | disp (base, index, scale) | [base + index * scale + disp] | base + index * scale + disp |
%rip相対参照 | disp (%rip) | [rip + disp] | %rip + disp |
注: Intelのマニュアルには「segment: メモリ参照」という形式もあるとありますが, segment: はほとんど使わないので,省いて説明します.
segmentは使わないの?(いえ,ちょっと使います)
%fsはセグメントレジスタと呼ばれる16ビット長のレジスタで,
他には%cs,%ds,%ss,%es,%gsがあります.
x86-64では%cs,%ds,%ss,%esは常にベースアドレスが0と扱われます.
%fs:という記法が使われた時は,
「%fsレジスタが示すベースアドレスをアクセスするアドレスに加える」
ことを意味します.
%fsのベースレジスタの値を得るには次の方法があります.
arch_prctl()システムコールを使う (ここでは説明しません).gdbでp/x $fs_baseを実行する. (なお,p/x $fsを実行すると0が返りますがこの値は嘘です)rdfsbase命令を使う.
rdfsbase命令はCPUとOSの設定に依存
rdfsbase命令が使えるかどうかは,CPUとOSの設定に依存します.
/proc/cpuinfoのflagsの表示にfsgsbaseがあれば,rdfsbase命令は使えます.
(以下の出力例ではfsgsbaseが入っています).
$ less /proc/cpuinfo
processor : 0
cpu family : 6
model name : Intel(R) Core(TM) i9-9880H CPU @ 2.30GHz
(一部略)
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon nopl xtopology tsc_reliable nonstop_tsc cpuid tsc_known_freq pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch cpuid_fault invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced fsgsbase tsc_adjust bmi1 avx2 smep bmi2 invpcid rdseed adx smap clflushopt xsaveopt xsavec xgetbv1 xsaves arat md_clear flush_l1d arch_capabilities
Linuxでは%fs:や%gs:を使って
スレッドローカルストレージ(TLS)を実現しています.
スレッドローカルストレージとは「スレッドごとの(一種の)グローバル変数」です.
マルチスレッドはスレッド同士がメモリ空間を共有しているので,
普通にグローバル変数を使うと,他のスレッドに内容が破壊される可能性があります.
スレッドローカルストレージを使えば,他のスレッドに破壊される心配がなくなります.
スレッドごとに%fsレジスタの値を変えて,
(プログラム上では同じ変数に見えても)スレッドごとに別のアドレスを
参照させて実現しているのでしょう.
(CPUがスレッドの実行を停止・再開するたびに,
スレッドが使用しているレジスタの値も退避・回復するので,
見た目上,「スレッドはそれぞれ独自のレジスタセットを持っている」ように動作します).
C11からは_Thread_local,gccでは__threadというキーワードで,
スレッドローカルな変数を宣言できます.
// tls.c
#include <stdio.h>
❶ __thread int x = 0xdeadbeef;
int main ()
{
printf ("x=%x\n", x);
}
$ gcc -g tls.c
$ ./a.out
x=deadbeef
$ objdump -d ./a.out | less
0000000000001149 <main>:
1149: f3 0f 1e fa endbr64
114d: 55 push %rbp
114e: 48 89 e5 mov %rsp,%rbp
1151: 64 8b 04 25 fc ff ff mov ❷ %fs:0xfffffffffffffffc,%eax
1158: ff
1159: 89 c6 mov %eax,%esi
$ gdb ./a.out
(gdb) b main
Breakpoint 1 at 0x1151: file tls.c, line 5.
(gdb) r
Breakpoint 1, main () at tls.c:5
5 printf ("x=%x\n", x);
(gdb) p/x x
$1 = 0xdeadbeef
(gdb) ❸ p/x $fs_base
$2 = ❹ 0x7ffff7fa9740
(gdb) x/1wx $fs_base - 4
0x7ffff7fa973c: ❺ 0xdeadbeef
- ❶
__threadキーワードを使って,変数xをスレッドローカルにします. - コンパイルした
a.outを逆アセンブルすると, ❷%fs:0xfffffffffffffffcというメモリ参照があります. これがスレッドローカルな変数xの実体の場所で, 「%fsのベースレジスタ - 4」がxのアドレスになります. - ❸
p/x $fs_baseを使って,%fsのベースレジスタの値を調べると ❹0x7ffff7fa9740と分かりました. - アドレス
$fs_base - 4のメモリの中身(4バイト)を調べると, 変数xの値である❺0xDEADBEEFが入っていました.
0xDEADBEEFとは
バイナリ上でデバッグする際,「ありそうもない値」を使うと便利なことがあります.
1や2だと偶然の一致がありますが,「ありそうもない値」を使うと
「高い確率でこれは私が書き込んだ値だよね」と分かるからです.
0xDEADBEEFは正しい16進数でありながら,英単語としても読めるので,
「ありそうもない値」として便利です.
他にはCAFEBABEもよく使われます.
0xDEADBEEFや0xCAFEBABEはバイナリを識別するマジックナンバーとしても使われます.
%fs:はスタック保護でも使われる
$ gcc -S -fstack-protector-all add5.c
add5.cを-fstack-protector-allオプションで
スタック保護機能をオンにしてコンパイルします.
(最近のLinuxのgccのデフォルトでは,-fstack-protector-strongが有効に
なっています.これはバッファを使用する関数のみにスタック保護機能を加えます.
ここでは-fstack-protector-allを使って全関数にスタック保護機能を加えました).
.text
.globl add5
.type add5, @function
add5:
endbr64
pushq %rbp
movq %rsp, %rbp
subq $32, %rsp
movl %edi, -20(%rbp)
movq ❶ %fs:40, %rax
movq ❷ %rax, -8(%rbp)
xorl %eax, %eax
movl -20(%rbp), %eax
addl $5, %eax
movq ❸ -8(%rbp), %rdx
subq ❹ %fs:40, %rdx
je .L3
call ❺ __stack_chk_fail@PLT
.L3:
leave
ret
.size add5, .-add5
- 関数の最初の方で,スレッドローカルストレージの❶
%fs:40の値を, (%rax経由で)スタック上の-8(%rbp)に書き込みます. - 関数の終わりの方で,❸
-8(%rbp)の値を%rdxレジスタにコピーし, ❹%fs:40の値を引き算しています. - もし,引き算の結果がゼロでなければ(つまり❸と❹の値が異なれば),
「バッファオーバーフローが起きた」と判断して,
❺
__stack_chk_fail@PLTを呼び出して プロセスを強制終了させます(つまりバッファオーバーフロー攻撃を防げたことになります).
メモリ参照で可能な組み合わせ(64ビットモードの場合)
通常のメモリ参照
- disp には符号あり定数を指定する.ただし「64ビット定数」は無いことに注意. アドレス計算時に64ビット長に符号拡張される. dispは変位(displacement)を意味する.
- base には上記のいずれかのレジスタを指定可能.省略も可.
- index には上記のいずれかのレジスタを指定可能.省略も可.
%rspを指定できないことに注意. - scale を省略すると
1と同じ
注: dispの例外.
mov␣命令のみ,64ビットのdispを指定可能. この場合,movabs␣というニモニックを使用可能. メモリ参照はdispのみで,base,index,scaleは指定不可. 他方のオペランドは%raxのみ指定可能.movq 0x1122334455667788, %rax movabsq 0x1122334455667788, %rax movq %rax, 0x1122334455667788 movabsq %rax, 0x1122334455667788
%rip相対参照
%rip相対参照では32ビットのdispと%ripレジスタのみが指定可能です.
メモリ参照の例
| AT&T形式 | Intel形式 | 指定したもの | 計算するアドレス |
|---|---|---|---|
8 | [8] | disp | 8 |
foo | [foo] | disp | foo |
(%rbp) | [rbp] | base | %rbp |
8(%rbp) | [rbp+8] | dispとbase | %rbp + 8 |
foo(%rbp) | [rbp+foo] | dispとbase | %rbp + foo |
8(%rbp,%rax) | [rbp+rax+8] | dispとbaseとindex | %rbp + %rax + 8 |
8(%rbp,%rax, 2) | [rbp+rax*2+8] | dispとbaseとindexとscale | %rbp + %rax*2 + 8 |
(%rip) | [rip] | base | %rip |
8(%rip) | [rip+8] | dispとbase | %rip + 8 |
foo(%rip) | [rip+foo] | dispとbase | %rip + foo |
%fs:-4 | fs:[-4] | segmentとdisp | %fsのベースレジスタ - 4 |
- メモリに読み書きするサイズの指定方法 (先頭アドレスだけだと,何バイト読み書きすればいいのか不明):
-
AT&T形式では命令サフィックス (
q,l,w,b)で指定する.例:movq $4, 8(%rbp) -
Intel形式では,メモリ参照の前に
QWORD PTR,DWORD PTR,WORD PTR,BYTE PTRを付加する (順番に,8バイト,4バイト,2バイト,1バイトを意味する). 例: `mov QWORD PTR [rbp+8], 4
-
「記法」「詳しい記法」欄で用いるオペランドの記法と注意
以下の機械語命令の説明で使う記法を説明します. この記法はその命令に許されるオペランドの形式を表します.
オペランド,即値(定数)
| 記法 | 例 | 説明 |
|---|---|---|
| op1 | 第1オペランド | |
| op2 | 第2オペランド | |
| imm | $100 | imm8, imm16, imm32のどれか |
$foo | ||
| imm8 | $100 | 8ビットの即値(定数) |
| imm16 | $100 | 16ビットの即値(定数) |
| imm32 | $100 | 32ビットの即値(定数) |
- 多くの場合,サイズを省略して単にimmと書きます. 特にサイズに注意が必要な時だけ,imm32などとサイズを明記します.
- 一部例外を除き, x86-64では64ビットの即値を書けません(32ビットまでです).
汎用レジスタ
| 記法 | 例 | 説明 |
|---|---|---|
| r | %rax | r8, r16, r32, r64のどれか |
| r8 | %al | 8ビットの汎用レジスタ |
| r16 | %ax | 16ビットの汎用レジスタ |
| r32 | %eax | 32ビットの汎用レジスタ |
| r64 | %rax | 64ビットの汎用レジスタ |
メモリ参照
| 記法 | 例 | 説明 |
|---|---|---|
| r/m | %rbp | r/m8, r/m16, r/m32, r/m32, r/m64のどれか |
100 | ||
-8(%rbp) | ||
foo(%rbp) | ||
| r/m8 | -8(%rbp) | r8 または 8ビットのメモリ参照 |
| r/m16 | -8(%rbp) | r16 また は16ビットのメモリ参照 |
| r/m32 | -8(%rbp) | r32 また は32ビットのメモリ参照 |
| r/m64 | -8(%rbp) | r64 また は64ビットのメモリ参照 |
| m | -8(%rbp) | メモリ参照 |
ジャンプ・コール用のオペランド
| 記法 | 例 | 説明 |
|---|---|---|
| rel | 0x100 | rel8, rel32のどちらか |
foo | ||
| rel8 | 0x100 | 8ビット相対アドレス(直接ジャンプ,定数だが$は不要) |
| rel32 | 0x1000 | 32ビット相対アドレス(直接ジャンプ,定数だが$は不要) |
| *r/m64 | *%rax | r64 または64ビットのメモリ参照による絶対アドレス (間接ジャンプ, *が前に必要) |
*(%rax) | ||
*-8(%rax) |
-
GNUアセンブラの記法のおかしな点
- 直接ジャンプ先の指定relは,定数なのに
$をつけてはいけない - 間接ジャンプ先の指定**r/m64は,
(他のr/m*オペランドでは不要だったのに)
*をつけなくてはいけない - 相対アドレスで
rel8かrel32をプログラマは選べない (jmp命令に命令サフィックスbやlをつけると怒られる.アセンブラにお任せするしか無い)
- 直接ジャンプ先の指定relは,定数なのに
-
*%raxと*(%rax)の違いに注意(以下の図を参照)

データ転送(コピー)系の命令
mov命令: データの転送(コピー)
| 記法 | 何の略か | 動作 |
|---|---|---|
mov␣ op1, op2 | move | op1の値をop2にデータ転送(コピー) |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
mov␣ r, r/m | movq %rax, %rbx | %rbx = %rax | movq-1.s movq-1.txt |
movq %rax, -8(%rsp) | *(%rsp - 8) = %rax | movq-2.s movq-2.txt | |
mov␣ r/m, r | movq -8(%rsp), %rax | %rax = *(%rsp - 8) | movq-3.s movq-3.txt |
mov␣ imm, r | movq $999, %rax | %rax = 999 | movq-4.s movq-4.txt |
mov␣ imm, r/m | movq $999, -8(%rsp) | *(%rsp - 8) = 999 | movq-5.s movq-5.txt |
␣は命令サフィックスmov命令(および他のほとんどのデータ転送命令)はステータスフラグの値を変更しないmov命令はメモリからメモリへの直接データ転送はできない
xchg命令: オペランドの値を交換
| 記法 | 何の略か | 動作 |
|---|---|---|
xchg op1, op2 | exchange | op1 と op2 の値を交換する |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
xchg r, r/m | xchg %rax, (%rsp) | %raxと(%rsp)の値を交換する | xchg.s xchg.txt |
xchg r/m, r | xchg (%rsp), %rax | (%rsp)と%raxの値を交換する | xchg.s xchg.txt |
xchg命令はアトミックに2つのオペランドの値を交換します.(LOCKプリフィクスをつけなくてもアトミックになります)- このアトミックな動作はロックなどの同期機構を作るために使えます.
lea命令: 実効アドレスを計算
| 記法 | 何の略か | 動作 |
|---|---|---|
lea␣ op1, op2 | load effective address | op1 の実効アドレスを op2 に代入する |
pushとpop命令: スタックとデータ転送
| 記法 | 何の略か | 動作 |
|---|---|---|
push␣ op1 | push | op1 をスタックにプッシュ |
pop␣ op1 | pop | スタックから op1 にポップ |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
push␣ imm | pushq $999 | %rsp-=8; *(%rsp)=999 | push1.s push1.txt |
push␣ r/m16 | pushw %ax | %rsp-=2; *(%rsp)=%ax | push2.s push2.txt |
push␣ r/m64 | pushq %rax | %rsp-=8; *(%rsp)=%rax | push-pop.s push-pop.txt |
pop␣ r/m16 | popw %ax | *(%rsp)=%ax; %rsp += 2 | pop2.s pop2.txt |
pop␣ r/m64 | popq %rbx | %rbx=*(%rsp); %rsp += 8 | push-pop.s push-pop.txt |
四則演算・論理演算の命令
add, adc命令: 足し算
| 記法 | 何の略か | 動作 |
|---|---|---|
add␣ op1, op2 | add | op1 を op2 に加える |
adc␣ op1, op2 | add with carry | op1 と CF を op2 に加える |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
add␣ imm, r/m | addq $999, %rax | %rax += 999 | sub-1.s sub-1.txt |
add␣ r, r/m | addq %rax, (%rsp) | *(%rsp) += %rax | add-2.s add-2.txt |
add␣ r/m, r | addq (%rsp), %rax | %rax += *(%rsp) | add-2.s add-2.txt |
adc␣ imm, r/m | adcq $999, %rax | %rax += 999 + CF | adc-1.s adc-1.txt |
adc␣ r, r/m | adcq %rax, (%rsp) | *(%rsp) += %rax + CF | adc-2.s adc-2.txt |
adc␣ r/m, r | adcq (%rsp), %rax | %rax += *(%rsp) + CF | adc-3.s adc-3.txt |
addとadcはオペランドが符号あり整数か符号なし整数かを区別せず, 両方の結果を正しく計算する.
sub, sbb命令: 引き算
| 記法 | 何の略か | 動作 |
|---|---|---|
sub␣ op1, op2 | subtract | op1 を op2 から引く |
sbb␣ op1, op2 | subtract with borrow | op1 と CF を op2 から引く |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
sub␣ imm, r/m | subq $999, %rax | %rax -= 999 | sub-1.s sub-1.txt |
sub␣ r, r/m | subq %rax, (%rsp) | *(%rsp) -= %rax | sub-2.s sub-2.txt |
sub␣ r/m, r | subq (%rsp), %rax | %rax -= *(%rsp) | sub-2.s sub-2.txt |
sbb␣ imm, r/m | sbbq $999, %rax | %rax -= 999 + CF | sbb-1.s sbb-1.txt |
sbb␣ r, r/m | sbbq %rax, (%rsp) | *(%rsp) -= %rax + CF | sbb-2.s sbb-2.txt |
sbb␣ r/m, r | sbbq (%rsp), %rax | %rax -= *(%rsp) + CF | sbb-2.s sbb-2.txt |
addと同様に,subとsbbは オペランドが符号あり整数か符号なし整数かを区別せず, 両方の結果を正しく計算する.
mul, imul命令: かけ算
| 記法 | 何の略か | 動作 |
|---|---|---|
mul␣ op1 | unsigned multiply | 符号なし乗算.(%rdx:%rax) = %rax * op1 |
imul␣ op1 | signed multiply | 符号あり乗算.(%rdx:%rax) = %rax * op1 |
imul␣ op1, op2 | signed multiply | 符号あり乗算.op2 *= op1 |
imul␣ op1, op2, op3 | signed multiply | 符号あり乗算.op3 = op1 * op2 |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
mul␣ r/m | mulq %rbx | (%rdx:%rax) = %rax * %rbx | mul-1.s mul-1.txt |
imul␣ r/m | imulq %rbx | (%rdx:%rax) = %rax * %rbx | imul-1.s imul-1.txt |
imul␣ imm, r | imulq $4, %rax | %rax *= 4 | imul-2.s imul-2.txt |
imul␣ r/m, r | imulq %rbx, %rax | %rax *= %rbx | imul-2.s imul-2.txt |
imul␣ imm, r/m, r | imulq $4, %rbx, %rax | %rax = %rbx * 4 | imul-2.s imul-2.txt |
- オペランドが1つの形式では,
%raxが隠しオペランドになる. このため,乗算の前に%raxに値をセットしておく必要がある. また,8バイト同士の乗算結果は最大で16バイトになるので, 乗算結果を%rdxと%raxに分割して格納する (16バイトの乗算結果の上位8バイトを%rdxに,下位8バイトを%raxに格納する). これをここでは(%rdx:%rax)という記法で表現している. imulだけ例外的に,オペランドが2つの形式と3つの形式がある. 2つか3つの形式では乗算結果が64ビットを超えた場合, 越えた分は破棄される(乗算結果は8バイトのみ).
div, idiv命令: 割り算,余り
| 記法 | 何の略か | 動作 |
|---|---|---|
div␣ op1 | unsigned divide | 符号なし除算と余り%rax = (%rdx:%rax) / op1 %rdx = (%rdx:%rax) % op1 |
idiv␣ op1 | signed divide | 符号あり除算と余り%rax = (%rdx:%rax) / op1 %rdx = (%rdx:%rax) % op1 |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
div␣ r/m | divq %rbx | %rax = (%rdx:%rax) / %rbx %rdx = (%rdx:%rax) % %rbx | div-1.s div-1.txt |
idiv␣ r/m | idivq %rbx | %rax = (%rdx:%rax) / %rbx %rdx = (%rdx:%rax) % %rbx | idiv-1.s idiv-1.txt |
- 16バイトの値
%rdx:%raxを第1オペランドで割った商が%raxに入り, 余りが%rdxに入る. - 隠しオペランドとして
%rdxと%raxが使われるので,事前に値を設定しておく必要がある.idivを使う場合,もし%rdxを使わないのであれば,cqto命令で%raxを%rdx:%raxに符号拡張しておくと良い.
inc, dec命令: インクリメント,デクリメント
| 記法 | 何の略か | 動作 |
|---|---|---|
inc␣ op1 | increment | op1の値を1つ増加 |
dec␣ op1 | decrement | op1の値を1つ減少 |
incやdecはオーバーフローしてもCFが変化しないところがポイント.
neg命令: 符号反転
| 記法 | 何の略か | 動作 |
|---|---|---|
neg␣ op1 | negation | 2の補数によるop1の符号反転 |
not命令: ビット論理演算 (1)
| 記法 | 何の略か | 動作 |
|---|---|---|
not␣ op1 | bitwise not | op1の各ビットの反転 (NOT) |
and, or, xor命令: ビット論理演算 (2)
| 記法 | 何の略か | 動作 |
|---|---|---|
and␣ op1, op2 | bitwise and | op1とop2の各ビットごとの論理積(AND) |
or␣ op1, op2 | bitwise or | op1とop2の各ビットごとの論理和(OR) |
xor␣ op1, op2 | bitwise xor | op1とop2の各ビットごとの排他的論理和(XOR) |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
and␣ imm, r/m | andq $0x0FFF, %rax | %rax &= 0x0FFF | and-1.s and-1.txt |
and␣ r, r/m | andq %rax, (%rsp) | *(%rsp) &= %rax | and-1.s and-1.txt |
and␣ r/m, r | andq (%rsp), %rax | %rax &= *(%rsp) | and-1.s and-1.txt |
or␣ imm, r/m | orq $0x0FFF, %rax | %rax |= 0x0FFF | or-1.s or-1.txt |
or␣ r, r/m | orq %rax, (%rsp) | *(%rsp) |= %rax | or-1.s or-1.txt |
or␣ r/m, r | orq (%rsp), %rax | %rax |= *(%rsp) | or-1.s or-1.txt |
xor␣ imm, r/m | xorq $0x0FFF, %rax | %rax ^= 0x0FFF | xor-1.s xor-1.txt |
xor␣ r, r/m | xorq %rax, (%rsp) | *(%rsp) ^= %rax | xor-1.s xor-1.txt |
xor␣ r/m, r | xorq (%rsp), %rax | %rax ^= *(%rsp) | xor-1.s xor-1.txt |
&,|,^はC言語で,それぞれ,ビットごとの論理積,論理和,排他的論理積です (忘れた人はC言語を復習しましょう).
sal, sar, shl, shr命令: シフト
| 記法 | 何の略か | 動作 |
|---|---|---|
sal␣ op1[, op2] | shift arithmetic left | 算術左シフト |
shl␣ op1[, op2] | shift logical left | 論理左シフト |
sar␣ op1[, op2] | shift arithmetic right | 算術右シフト |
shr␣ op1[, op2] | shift logical right | 論理右シフト |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
sal␣ r/m | salq %rax | %raxを1ビット算術左シフト | sal-1.s sal-1.txt |
sal␣ imm8, r/m | salq $2, %rax | %raxを2ビット算術左シフト | sal-1.s sal-1.txt |
sal␣ %cl, r/m | salq %cl, %rax | %raxを%clビット算術左シフト | sal-1.s sal-1.txt |
shl␣ r/m | shlq %rax | %raxを1ビット論理左シフト | shl-1.s shl-1.txt |
shl␣ imm8, r/m | shlq $2, %rax | %raxを2ビット論理左シフト | shl-1.s shl-1.txt |
shl␣ %cl, r/m | shlq %cl, %rax | %raxを%clビット論理左シフト | shl-1.s shl-1.txt |
sar␣ r/m | sarq %rax | %raxを1ビット算術右シフト | sar-1.s sar-1.txt |
sar␣ imm8, r/m | sarq $2, %rax | %raxを2ビット算術右シフト | sar-1.s sar-1.txt |
sar␣ %cl, r/m | sarq %cl, %rax | %raxを%clビット算術右シフト | sar-1.s sar-1.txt |
shr␣ r/m | shrq %rax | %raxを1ビット論理右シフト | shr-1.s shr-1.txt |
shr␣ imm8, r/m | shrq $2, %rax | %raxを2ビット論理右シフト | shr-1.s shr-1.txt |
shr␣ %cl, r/m | shrq %cl, %rax | %raxを%clビット論理右シフト | shr-1.s shr-1.txt |
- op1[, op2] という記法は「op2は指定してもしなくても良い」という意味です.
- シフトとは(指定したビット数だけ)右か左にビット列をずらすことを意味します. op2がなければ「1ビットシフト」を意味します.
- 論理シフトとは「空いた場所に0を入れる」, 算術シフトとは「空いた場所に符号ビットを入れる」ことを意味します.
- 左シフトの場合は(符号ビットを入れても意味がないので),論理シフトでも算術シフトでも,0を入れます.その結果,算術左シフト
salと論理左シフトshlは全く同じ動作になります. - C言語の符号あり整数に対する右シフト(>>)は算術シフトか論理シフトかは 決まっていません(実装依存です). C言語で,ビット演算は符号なし整数に対してのみ行うようにしましょう.
rol, ror, rcl, rcr命令: ローテート
| 記法 | 何の略か | 動作 |
|---|---|---|
rol␣ op1[, op2] | rotate left | 左ローテート |
rcl␣ op1[, op2] | rotate left through carry | CFを含めて左ローテート |
ror␣ op1[, op2] | rotate right | 右ローテート |
rcr␣ op1[, op2] | rotate right through carry | CFを含めて右ローテート |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
rol␣ r/m | rolq %rax | %raxを1ビット左ローテート | rol-1.s rol-1.txt |
rol␣ imm8, r/m | rolq $2, %rax | %raxを2ビット左ローテート | rol-1.s rol-1.txt |
rol␣ %cl, r/m | rolq %cl, %rax | %raxを%clビット左ローテート | rol-1.s rol-1.txt |
rcl␣ r/m | rclq %rax | %raxを1ビットCFを含めて左ローテート | rcl-1.s rcl-1.txt |
rcl␣ imm8, r/m | rclq $2, %rax | %raxを2ビットCFを含めて左ローテート | rcl-1.s rcl-1.txt |
rcl␣ %cl, r/m | rclq %cl, %rax | %raxを%clビットCFを含めて左ローテート | rcl-1.s rcl-1.txt |
ror␣ r/m | rorq %rax | %raxを1ビット右ローテート | ror-1.s ror-1.txt |
ror␣ imm8, r/m | rorq $2, %rax | %raxを2ビット右ローテート | ror-1.s ror-1.txt |
ror␣ %cl, r/m | rorq %cl, %rax | %raxを%clビット右ローテート | ror-1.s ror-1.txt |
rcr␣ r/m | rcrq %rax | %raxを1ビットCFを含めて右ローテート | rcr-1.s rcr-1.txt |
rcr␣ imm8, r/m | rcrq $2, %rax | %raxを2ビットCFを含めて右ローテート | rcr-1.s rcr-1.txt |
rcr␣ %cl, r/m | rcrq %cl, %rax | %raxを%clビットCFを含めて右ローテート | rcr-1.s rcr-1.txt |
- op1[, op2] という記法は「op2は指定してもしなくても良い」という意味です.
- ローテートは,シフトではみ出したビットを空いた場所に入れます.
- ローテートする方向(右か左),CFを含めるか否かで,4パターンの命令が存在します.
cmp, test命令: 比較
cmp命令
| 記法 | 何の略か | 動作 |
|---|---|---|
cmp␣ op1[, op2] | compare | op1とop2の比較結果をフラグに格納(比較はsub命令を使用) |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
cmp␣ imm, r/m | cmpq $999, %rax | subq $999, %raxのフラグ変化のみ計算.オペランドは変更なし | cmp-1.s cmp-1.txt |
cmp␣ r, r/m | cmpq %rax, (%rsp) | subq %rax, (%rsp)のフラグ変化のみ計算.オペランドは変更なし | cmp-1.s cmp-1.txt |
cmp␣ r/m, r | cmpq (%rsp), %rax | subq (%rsp), %raxのフラグ変化のみ計算.オペランドは変更なし | cmp-1.s cmp-1.txt |
cmp命令はフラグ計算だけを行います. (レジスタやメモリは変化しません).cmp命令は条件付きジャンプ命令と一緒に使うことが多いです. 例えば以下の2命令で「%raxが(符号あり整数として)1より大きければジャンプする」という意味になります.
cmpq $1, %rax
jg L2
test命令
| 記法 | 何の略か | 動作 |
|---|---|---|
test␣ op1[, op2] | logical compare | op1とop2の比較結果をフラグに格納(比較はand命令を使用) |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
test␣ imm, r/m | testq $999, %rax | andq $999, %raxのフラグ変化のみ計算.オペランドは変更なし | test-1.s test-1.txt |
test␣ r, r/m | testq %rax, (%rsp) | andq %rax, (%rsp)のフラグ変化のみ計算.オペランドは変更なし | test-1.s test-1.txt |
test␣ r/m, r | testq (%rsp), %rax | andq (%rsp), %raxのフラグ変化のみ計算.オペランドは変更なし | test-1.s test-1.txt |
cmp命令と同様に,test命令はフラグ計算だけを行います. (レジスタやメモリは変化しません).cmp命令と同様に,test命令は条件付きジャンプ命令と一緒に使うことが多いです. 例えば以下の2命令で「%raxが0ならジャンプする」という意味になります.
testq %rax, %rax
jz L2
- 例えば
%raxが0かどうかを知りたい場合,cmpq $0, %raxとtestq %rax, %raxのどちらでも調べることができます. どちらの場合も,ZF==1なら,%raxが0と分かります (testq %rax, %raxはビットごとのANDのフラグ変化を計算するので,%raxがゼロの時だけ,ZF==1となります). コンパイラはtestq %rax, %raxを使うことが多いです.testq %rax, %raxの方が命令長が短くなるからです.
movs, movz, cbtw, cqto命令: 符号拡張とゼロ拡張
movs, movz命令
| 記法(AT&T形式) | 記法(Intel形式) | 何の略か | 動作 |
|---|---|---|---|
movs␣␣ op1, op2 | movsx op2, op1 movsxd op2, op1 | move with sign-extention | op1を符号拡張した値をop2に格納 |
movz␣␣ op1, op2 | movzx op2, op1 | move with zero-extention | op1をゼロ拡張した値をop2に格納 |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
movs␣␣ r/m, r | movslq %eax, %rbx | %rbx = %eaxを8バイトに符号拡張した値 | movs-movz.s movs-movz.txt |
movz␣␣ r/m, r | movzwq %ax, %rbx | %rbx = %axを8バイトにゼロ拡張した値 | movs-movz.s movs-movz.txt |
␣␣に入るもの | 何の略か | 意味 |
|---|---|---|
bw | byte to word | 1バイト→2バイトの拡張 |
bl | byte to long | 1バイト→4バイトの拡張 |
bq | byte to quad | 1バイト→8バイトの拡張 |
wl | word to long | 2バイト→4バイトの拡張 |
wq | word to quad | 2バイト→8バイトの拡張 |
lq | long to quad | 4バイト→8バイトの拡張 |
movs,movz命令はAT&T形式とIntel形式でニモニックが異なるので注意です.- GNUアセンブラではAT&T形式でも実は
movsx,movzxのニモニックが使用できます. ただし逆アセンブルすると,movslq,movzwqなどのニモニックが表示されるので,movslq,movzwqなどを使う方が良いでしょう. movzlq(Intel形式ではmovzxd)はありません.例えば,%eaxに値を入れると,%raxの上位32ビットはクリアされるので,movzlqは不要だからです.- Intel形式では,4バイト→8バイトの拡張の時だけ,
(
movsxではなく)movsxdを使います.
cbtw, cqto命令
| 記法(AT&T形式) | 記法(Intel形式) | 何の略か | 動作 |
|---|---|---|---|
**c␣t␣ | c␣␣␣ | convert ␣ to ␣ | %rax (または%eax, %ax, %al)を符号拡張 |
| 詳しい記法 (AT&T形式) | 詳しい記法 (Intel形式) | 例 | 例の動作 | サンプルコード |
|---|---|---|---|---|
cbtw | cbw | cbtw | %al(byte)を%ax(word)に符号拡張 | cbtw.s cbtw.txt |
cwtl | cwde | cwtl | %ax(word)を%eax(long)に符号拡張 | cbtw.s cbtw.txt |
cwtd | cwd | cwtd | %ax(word)を%dx:%ax(double word)に符号拡張 | cbtw.s cbtw.txt |
cltd | cdq | cltd | %eax(long)を%edx:%eax(doube long, quad)に符号拡張 | cbtw.s cbtw.txt |
cltq | cdqe | cltd | %eax(long)を%rax(quad)に符号拡張 | cbtw.s cbtw.txt |
cqto | cqo | cqto | %rax(quad)を%rdx:%rax(octuple)に符号拡張 | cbtw.s cbtw.txt |
cqtoなどはidivで割り算する前に使うと便利(%rdx:%raxがidivの隠しオペランドなので).- GNUアセンブラはIntel形式のニモニックも受け付ける.
ジャンプ命令
jmp: 無条件ジャンプ
| 記法 | 何の略か | 動作 |
|---|---|---|
jmp op1 | jump | op1にジャンプ |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
jmp rel | jmp 0x1000 | 0x1000番地に相対・直接ジャンプ (%rip += 0x1000) | jmp.s jmp.txt |
jmp foo | foo番地に相対・直接ジャンプ (%rip += foo) | jmp.s jmp.txt | |
jmp r/m | jmp *%rax | *%rax番地に絶対・間接ジャンプ (%rip = *%rax)) | jmp.s jmp.txt |
jmp r/m | jmp *(%rax) | *(%rax)番地に絶対・間接ジャンプ (%rip = *(%rax)) | jmp.s jmp.txt |
- x86-64では,相対・直接と絶対・間接の組み合わせしかありません. (つまり,相対・間接ジャンプや絶対・直接ジャンプはありません. なお,ここで紹介していないfarジャンプでは絶対・直接もあります).
- 相対・直接ジャンプでは符号ありの8ビット(rel8)か 32ビット(rel32)の整数定数で相対アドレスを指定します. (64ビットの相対アドレスは指定できません.64ビットのジャンプをしたい時は 絶対・間接ジャンプ命令を使います).
- rel8かrel32かはアセンブラが勝手に選んでくれます.
逆に
jmpbやjmplなどとサフィックスをつけて指定することはできません. - なぜか,定数なのにrel8やrel32にはドルマーク
$をつけません. 逆にr/mの前にはアスタリスク*が必要です. GNUアセンブラのこの部分は一貫性がないので要注意です.
条件付きジャンプの概要
- 条件付きジャンプ命令
j␣は ステータスフラグ (CF, OF, PF, SF, ZF)をチェックして, 条件が成り立てばジャンプします. - 条件付きジャンプは比較命令と一緒に使うことが多いです.
例えば以下の2命令で「
%raxが(符号あり整数として)1より大きければジャンプする」という意味になります.
cmpq $1, %rax
jg L2
- 条件付きジャンプ命令のニモニックでは次の用語を使い分けます
- 符号あり整数の大小には less/greater を使う
- 符号なし整数の大小には above/below を使う
条件付きジャンプ: 符号あり整数用
| 記法 | 何の略か | 動作 | ジャンプ条件 |
|---|---|---|---|
jg reljnle rel | jump if greater jump if not less nor equal | op2>op1ならrelにジャンプ !(op2<=op1)ならrelにジャンプ | ZF==0&&SF==OF |
jge reljnl rel | jump if greater or equal jump if not less | op2>=op1ならrelにジャンプ !(op2<op1)ならrelにジャンプ | SF==OF |
jle reljng rel | jump if less or equal jump if not greater | op2<=op1ならrelにジャンプ !(op2>op1)ならrelにジャンプ | ZF==1||SF!=OF |
jl reljnge rel | jump if less jump if not greater nor equal | op2<op1ならrelにジャンプ !(op2>=op1)ならrelにジャンプ | SF!=OF |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
jg rel | cmpq $0, %raxjg foo | if (%rax>0) goto foo | jg.s jg.txt |
jnle rel | cmpq $0, %raxjnle foo | if (!(%rax<=0)) goto foo | jg.s jg.txt |
jge rel | cmpq $0, %raxjge foo | if (%rax>=0) goto foo | jge.s jge.txt |
jnl rel | cmpq $0, %raxjnl foo | if (!(%rax<0)) goto foo | jge.s jge.txt |
jle rel | cmpq $0, %raxjle foo | if (%rax<=0) goto foo | jle.s jle.txt |
jng rel | cmpq $0, %raxjng foo | if (!(%rax>0)) goto foo | jle.s jle.txt |
jl rel | cmpq $0, %raxjl foo | if (%rax<0) goto foo | jl.s jl.txt |
jnge rel | cmpq $0, %raxjnge foo | if (!(%rax>=0)) goto foo | jl.s jl.txt |
- op1 と op2 は条件付きジャンプ命令の直前で使用した
cmp命令のオペランドを表します. jgとjnleは異なるニモニックですが動作は同じです. その証拠にジャンプ条件はZF==0&&SF==OFと共通です. 他の3つのペア,jgeとjnl,jleとjng,jlとjngeも同様です.
条件付きジャンプ: 符号なし整数用
| 記法 | 何の略か | 動作 | ジャンプ条件 |
|---|---|---|---|
ja reljnbe rel | jump if above jump if not below nor equal | op2>op1ならrelにジャンプ !(op2<=op1)ならrelにジャンプ | CF==0&ZF==0 |
jae reljnb rel | jump if above or equal jump if not below | op2>=op1ならrelにジャンプ !(op2<op1)ならrelにジャンプ | CF==0 |
jbe reljna rel | jump if below or equal jump if not above | op2<=op1ならrelにジャンプ !(op2>op1)ならrelにジャンプ | CF==1&&ZF==1 |
jb reljnae rel | jump if below jump if not above nor equal | op2<op1ならrelにジャンプ !(op2>=op1)ならrelにジャンプ | CF==1 |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
ja rel | cmpq $0, %raxja foo | if (%rax>0) goto foo | ja.s ja.txt |
jnbe rel | cmpq $0, %raxjnbe foo | if (!(%rax<=0)) goto foo | ja.s ja.txt |
jae rel | cmpq $0, %raxjae foo | if (%rax>=0) goto foo | jae.s jae.txt |
jnb rel | cmpq $0, %raxjnb foo | if (!(%rax<0)) goto foo | jae.s jae.txt |
jbe rel | cmpq $0, %raxjbe foo | if (%rax<=0) goto foo | jbe.s jbe.txt |
jna rel | cmpq $0, %raxjna foo | if (!(%rax>0)) goto foo | jbe.s jbe.txt |
jb rel | cmpq $0, %raxjb foo | if (%rax<0) goto foo | jb.s jb.txt |
jnae rel | cmpq $0, %raxjnae foo | if (!(%rax>=0)) goto foo | jb.s jb.txt |
- op1 と op2 は条件付きジャンプ命令の直前で使用した
cmp命令のオペランドを表します. jaとjnbeは異なるニモニックですが動作は同じです. その証拠にジャンプ条件はCF==0&&ZF==0と共通です. 他の3つのペア,jaeとjnb,jbeとjna,jbとjnaeも同様です.
条件付きジャンプ: フラグ用
| 記法 | 何の略か | 動作 | ジャンプ条件 |
|---|---|---|---|
jc rel | jump if carry | CF==1ならrelにジャンプ | CF==1 |
jnc rel | jump if not carry | CF==0ならrelにジャンプ | CF==0 |
jo rel | jump if overflow | OF==1ならrelにジャンプ | OF==1 |
jno rel | jump if not overflow | OF==0ならrelにジャンプ | OF==0 |
js rel | jump if sign | SF==1ならrelにジャンプ | SF==1 |
jns rel | jump if not sign | SF==0ならrelにジャンプ | SF==0 |
jz rel je rel | jump if zero jump if equal | ZF==1ならrelにジャンプ op2==op1ならrelにジャンプ | ZF==1 |
jnz rel jne rel | jump if not zero jump if not equal | ZF==0ならrelにジャンプ op2!=op1ならrelにジャンプ | ZF==0 |
jp rel jpe rel | jump if parity jump if parity even | PF==1ならrelにジャンプ | PF==1 |
jnp rel jpo rel | jump if not parity jump if parity odd | PF==0ならrelにジャンプ | PF==0 |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
jc rel | jc foo | if (CF==1) goto foo | jc.s jc.txt |
jnc rel | jnc foo | if (CF==0) goto foo | jc.s jc.txt |
jo rel | jo foo | if (OF==1) goto foo | jo.s jo.txt |
jno rel | jno foo | if (OF==0) goto foo | jo.s jo.txt |
js rel | js foo | if (SF==1) goto foo | js.s js.txt |
jns rel | jns foo | if (SF==0) goto foo | js.s js.txt |
jz rel | jz foo | if (ZF==1) goto foo | jz.s jz.txt |
je rel | cmpq $0, %raxje foo | if (%rax==0) goto foo | jz.s jz.txt |
jnz rel | jnz foo | if (ZF==0) goto foo | jz.s jz.txt |
jne rel | cmpq $0, %raxjne foo | if (%rax!=0) goto foo | jz.s jz.txt |
jp rel | jp foo | if (PF==1) goto foo | jp.s jp.txt |
jpe rel | jpe foo | if (PF==1) goto foo | jp.s jp.txt |
jnp rel | jnp foo | if (PF==0) goto foo | jp.s jp.txt |
jpo rel | jpo foo | if (PF==0) goto foo | jp.s jp.txt |
- op1 と op2 は条件付きジャンプ命令の直前で使用した
cmp命令のオペランドを表します. jzとjeは異なるニモニックですが動作は同じです. その証拠にジャンプ条件はZF==1と共通です. 他の3つのペア,jnzとjne,jpとjpe,jnpとjpoも同様です.- AFフラグのための条件付きジャンプ命令は存在しません.
関数呼び出し(コール命令)
call, ret命令: 関数を呼び出す,リターンする
| 記法 | 何の略か | 動作 |
|---|---|---|
call op1 | call procedure | %ripをスタックにプッシュしてから op1にジャンプする( pushq %rip; %rip = op1) |
ret | return from procedure | スタックからポップしたアドレスにジャンプする ( popq %rip) |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
call rel | call foo | 相対・直接の関数コール | call.s call.txt |
call r/m | call *%rax | 絶対・間接の関数コール | call.s call.txt |
ret | ret | 関数からリターン | call.s call.txt |
enter, leave命令: スタックフレームを作成する,破棄する
| 記法 | 何の略か | 動作 |
|---|---|---|
enter op1, op2 | make stack frame | サイズop1のスタックフレームを作成する |
leave | discard stack frame | 今のスタックフレームを破棄する |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
enter imm16, imm8 | enter $0x20, $0 | pushq %rbpmovq %rsp, %rbpsubq $0x20, %rsp | enter.s enter.txt |
leave | leave | movq %rbp, %rsppopq %rbp | enter.s enter.txt |
enter命令のop2には関数のネストレベルを指定するのですが, C言語では入れ子の関数がない(つまりネストレベルは常にゼロ)なので 常にゼロを指定します.- ただし,
enterは遅いので通常は使いません. 代わりに同等の動作をするpushq %rbp; movq %rsp, %rbp; subq $n, %rspを使います.
その他
nop命令
| 記法 | 何の略か | 動作 |
|---|---|---|
nop | no operation | 何もしない(プログラムカウンタのみ増加) |
nop op1 | no operation | 何もしない(プログラムカウンタのみ増加) |
nopは何もしない命令です(ただしプログラムカウンタ%ripは増加します).- 機械語命令列の間を(何もせずに)埋めるために使います.
nopの機械語命令は1バイト長です.nopr/m という形式の命令は2〜9バイト長のnop命令になります. 1バイト長のnopを9個並べるより, 9バイト長のnopを1個並べた方が,実行が早くなります.- 「複数バイトの
nop命令がある」という知識は, 逆アセンブル時にnopl (%rax)などを見てビックリしないために必要です.
cmpxchg, cmpxchg8b, cmpxchg16b命令: CAS (compare-and-swap)命令
cmpxchg命令
| 記法 | 何の略か | 動作 |
|---|---|---|
cmpxchg op1, op2 | compare and exchange | %raxとop2を比較し,同じならop2=op1,異なれば %rax=op2 |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
cmpxchg r, r/m | cmpxchg %rbx, (%rsp) | if (*(%rsp)==%rax) *(%rsp)=%rbx;else %rax=*(%rsp); | cmpxchg.s cmpxchg.txt |
cmpxchg命令などのCAS命令は,lock-free,つまりロックを使わず 同期機構を実現するために使われます. アトミックに実行する必要があるため,通常,LOCKプリフィックスをつけて使います.- 気持ち:
- あるメモリにあるop2を新しい値op1で書き換えたい.
- ただし,代入前のop2の値は
%raxと同じはずで, もし(割り込まれて)知らない間に別の値になっていたら,この代入は失敗させる. - 代入が失敗したことを知るために,
(他の誰かが更新した最新の)op2の値を
%raxに入れる.cmpxchg実行後に%raxの値を調べれば,無事にop1への代入ができたかどうかが分かる.
cmpxchg8b, cmpxchg16b命令
| 記法 | 何の略か | 動作 |
|---|---|---|
cmpxchg8b op1 | compare and exchange bytes | %edx:%eaxとop1を比較し,同じならop1=%ecx:%ebx,異なれば %edx:%eax=op1 |
cmpxchg16b op1 | compare and exchange bytes | %rdx:%raxとop1を比較し,同じならop1=%rcx:%rbx,異なれば %rdx:%rax=op1 |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
cmpxchg8b m64 | cmpxchg8b (%rsp) | if (*(%rsp)==%edx:%eax) *(%rsp)=%ecx:%ebx;else %edx:%eax=*(%rsp); | cmpxchg8b.s cmpxchg8.txt |
cmpxchg16b m128 | cmpxchg16b (%rsp) | if (*(%rsp)==%rdx:%rax) *(%rsp)=%rcx:%rbx;else %rdx:%rax=*(%rsp); | cmpxchg16b.s cmpxchg16.txt |
cmpxchg8b,cmpxchg16bもCAS命令の一種ですが,cmpxchgとステータスフラグの変化が異なるので,分けて書いています.cmpxchg16b命令が参照するメモリは16バイト境界のアラインメントが必要です. (つまりメモリアドレスが16の倍数である必要があります).
rdtsc, rdtscp命令: タイムスタンプを読む
| 記法 | 何の略か | 動作 |
|---|---|---|
rdtsc | read time-stamp counter | %edx:%eax = 64ビットタイムスタンプカウンタ |
rdtscp | read time-stamp counter and processor ID | %edx:%eax = 64ビットタイムスタンプカウンタ %ecx = 32ビットプロセッサID |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
rdtsc | rdtsc | %edx:%eax = 64ビットタイムスタンプカウンタ | rdtsc.s rdtsc.txt |
rdtscp | rdtscp | %edx:%eax = 64ビットタイムスタンプカウンタ %ecx = 32ビットプロセッサID | rdtscp.s rdtscp.txt |
- x86-64は64ビットのタイムスタンプカウンタ (TSC: time stamp counter)を備えており, リセット後のCPUのサイクル数を数えています. 原理的には「サイクル数の差分をCPUのクロック周波数で割れば実行時間が得られる」 はずですが,実際にはout-of-order実行や, 内部クロックの変化などを考慮する必要があります. 詳しくはHow to Benchmark Code Execution Times on Intel® IA-32 and IA-64 Instruction Set Architectures を参照して下さい.
rdtscp命令を使うと,プロセッサIDも取得できます.rdtscとrdtscpではシリアライズ処理が異なるため,得られるサイクル数も異なります. 詳しくは x86-64のマニュアルSDM を参照して下さい.
int3命令
| 記法 | 何の略か | 動作 |
|---|---|---|
int3 | call to interrupt procedure | ブレークポイントトラップを発生 |
int3命令はブレークポイントトラップ(ソフトウェア割り込みの一種)を発生させます. 通常実行ではint3を実行した時点でプロセスは強制終了となりますが, デバッガ上ではその時点でブレークします.continueコマンドでその後の実行も継続できます.ブレークしたい場所が分かっている場合は, Cコード中にasm ("int3");と書くことでデバッガ上でブレークさせることができます.
ud2命令
| 記法 | 何の略か | 動作 |
|---|---|---|
ud2 | undefined instruction | 無効オペコード例外を発生させる |
ud2命令は無効オペコード例外を発生させます. 通常実行ではud2を実行した時点でプロセスは, シグナルSIGILL(illegal instruction)を受け取り,強制終了となります デバッガ上でも,Program received signal SIGILL, Illegal instruction.というメッセージが出て,プロセスは終了になります. 本書では「実行が通るはずがない場所が本当かどうか」の確認のためud2を使います.(通るはずがない場所にud2を置いて,SIGILLが発生しなければOKです)
例外 (exception)とは
例外(exception)はCPUが発生させる割り込み(ソフトウェア割り込み)です. Intel用語で,例外はさらにフォールト(fault),トラップ(trap), アボート(abort)に分類されます. 例えばゼロ割はフォールト,ブレークポイントはトラップです. マイOS作りたい人は頑張って勉強して下さい.
endbr64命令
| 記法 | 何の略か | 動作 |
|---|---|---|
endbr64 | end branch 64 bit | 間接ジャンプ先として許す |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
endbr64 | endbr64 | 間接ジャンプ先として許す | endbr64.s endbr64.txt |
- Intel CET IBT技術に対応したCPUの場合,
間接ジャンプ後のジャンプ先が
endbr64以外だった場合, 例外が発生してプログラムは強制終了となります. - Intel CET IBT技術に未対応のCPUの場合は,
nop命令として動作します. - 逆アセンブルして
endbr64を見てもビックリしないためにこの説明を書いています. - 私のPCが古すぎて,Intel CET未対応だったため,2023/8/17現在,クラッシュが発生するサンプルコードを作れていません.
bndプリフィクス
Intel MPX (Memory Protection Extensions)の機能の一部で,
制御命令 (ジャンプ命令やリターン命令など)に指定できます.
BND0からBND3レジスタに指定した境界に対して境界チェックを行います.
この機能をサポートしてないCPUではnopとして動作します.
- 逆アセンブルして
bndを見てもビックリしないためにこの説明を書いています.
以下のようにPLTセクションを見ると❶bndが使われています.
$ objdump -d /bin/ls | less
(中略)
Disassembly of section .plt:
0000000000004030 <.plt>:
4030: ff 35 2a dc 01 00 push 0x1dc2a(%rip) # 21c60 <_ob
stack_memory_used@@Base+0x114b0>
4036: f2 ff 25 2b dc 01 00 ❶ bnd jmp *0x1dc2b(%rip) # 21c68 <_obstack_memory_used@@Base+0x114b8>
403d: 0f 1f 00 nopl (%rax)
set␣命令: ステータスフラグの値を取得
| 記法 | 何の略か | 動作 |
|---|---|---|
set␣ op1 | set byte on condition | if (条件␣が成立) op1=1; else op1=0; |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
set␣ r/m8 | setz %al | %al = ZF | setz.s setz.txt |
setg %al | より大きい(greater)条件が成立なら%al =1,違えば%al =0 | setg.s setg.txt |
set␣命令はステータスフラグの値を取得します.␣には条件付きジャンプ命令j␣の␣と同じものをすべて入れられます.
ストリング命令
movsなどのストリング命令はREPプリフィクスと組み合わせて使います.
- REPプリフィクス
| 記法 | 何の略か | 動作 |
|---|---|---|
rep insn | repeat | %ecx==0になるまで命令insnと %ecx--を繰り返し実行 |
repe insn | repeat while equal | %ecx==0またはフラグZF==0になるまで命令insnと %ecx--を繰り返し実行 |
repz insn | repeat while zero | |
repne insn | repeat while not equal | %ecx==0またはフラグZF==1になるまで命令insnと %ecx--を繰り返し実行 |
repnz insn | repeat while not zero |
| 詳しい記法 | 例 | 例の動作 | サンプルコード |
|---|---|---|---|
rep insn | rep movsb | while (%ecx-- > 0) (*%rdi++) = (*%rsi++); # 1バイトずつコピー | rep.s rep.txt |
repe insn repz insn | repe cmpsb repz cmpsb | while (%ecx-- > 0 && (*%rdi++ == *%rsi++)); # 1バイトずつ比較 | repe.s repe.txt repz.s repz.txt |
repne insn repnz insn | repne cmpsb repnz cmpsb | while (%ecx-- > 0 && (*%rdi++ != *%rsi++)); # 1バイトずつ比較 | repne.s repne.txt repnz.s repnz.txt |
注意: DFフラグ(direction flag)が0の場合,
%rsiと%rdiを増やす.DFが1の場合は減らす.上記の説明はDF==0を仮定.
注意: ストリング命令はセグメントレジスタ
%dsと%esを使って,%ds:(%rsi)と%es:(%rdi)にアクセスします.が,x86-64では%dsも%esもベースレジスタをゼロと扱うので,%dsと%esは無視して構いません.

-
ストリング命令
記法 何の略か 動作 movs␣move string (%rsi)を(%rdi)にnバイト転送;%rsi+= n;%rdi+= n;lods␣load string (%rsi)を%raxにnバイト転送;%rsi+= n;stos␣store string %raxを(%rdi)にnバイト転送;%rdi+= n;ins␣input string I/Oポート %dxから(%rdi)にnバイト転送;%rdi+= n;outs␣output string (%rsi)からI/Oポート%dxにnバイト転送;%rsi+= n;cmps␣compare string (%rsi)と(%rdi)をnバイト比較;%rsi+= n;%rdi+= n;scas␣scan string %raxと(%rdi)をnバイト比較;%rdi+= n;詳しい記法 例 例の動作 サンプルコード rep movsbrep movsbwhile (%ecx-- > 0) (*%rdi++) = (*%rsi++);
# 1バイトずつコピーrep.s rep.txt rep lodsbrep lodsbwhile (%ecx-- > 0) %al = (*%rsi++);
# 1バイトずつコピーlods.s lods.txt rep stosqrep stosqwhile (%ecx-- > 0) {(*%rdi) = %rax; %rdi+=8; }
# 8バイトずつコピーstos.s stos.txt repe cmpsbrepe cmpsbwhile (%ecx-- > 0 && (*%rdi++) == (*%rsi++);
# 1バイトずつ比較repe.s repe.txt repne scasbrepne scasbwhile (%ecx-- > 0 && (*%rdi++) != %rax);
# 1バイトずつ比較scas.s scas.txt ␣にはb,w,l,qが入り,それぞれ, メモリ参照のサイズ(上ではnと表記)が1バイト,2バイト,4バイト,8バイトになる. (ただし,insとoutsはb,w,lのみ指定可能).%raxはオペランドサイズにより,%rax,%eax,%ax,%alのいずれかになる.ins␣とout␣の実例はここでは無し.
-
DFフラグ(方向フラグ)と
cld命令・std命令記法 何の略か 動作 cldclear direction flag DF=0 stdset direction flag DF=1 - DFフラグはストリング命令で,
%rsiと%rdiを増減する方向を決めます.- DF=0 の時は
%rsiと%rdiを増やします - DF=1 の時は
%rsiと%rdiを減らします
- DF=0 の時は
- DFフラグの変更は
cldやstdで行います (一般的にフラグレジスタの値を変更する場合,pushfでフラグレジスタの値を保存し,popfで元に戻すのが安全です). - Linux AMD64のABIにより,
関数の出入り口ではDF=0に戻す必要があります.このお約束のため,
自分で
stdしていなければ,必ずDF==0となります(わざわざcldする必要はありません).
- DFフラグはストリング命令で,
リンク集
- デバッグ情報の仕様書 dwarf5仕様書
- WindowsのLinux環境 WSL2
- 仮想マシン VirtualBox
- コンテナ環境 Docker
- オンライン開発環境 repl.it
- OS自作本 ゼロからのOS自作入門
- Linuxディストリビューション Ubuntu
- GNUアセンブラのマニュアル Using as
- GCC 9.4のマニュアル 9.4 Manuals
- x86-64のマニュアル Intel 64 and IA-32 Architectures Software Developer Manuals
- LinuxのABI System V ABI
- Linux AMD64のABI System V ABI (AMD64)
-
マークダウン環境 mdbook
-
call frame informationの短い解説 CFI
-
rdtscpで実行時間を測る際の注意事項 How to Benchmark Code Execution Times on Intel® IA-32 and IA-64 Instruction Set Architectures